Kafka优化提升
一、如何优化kafka集群
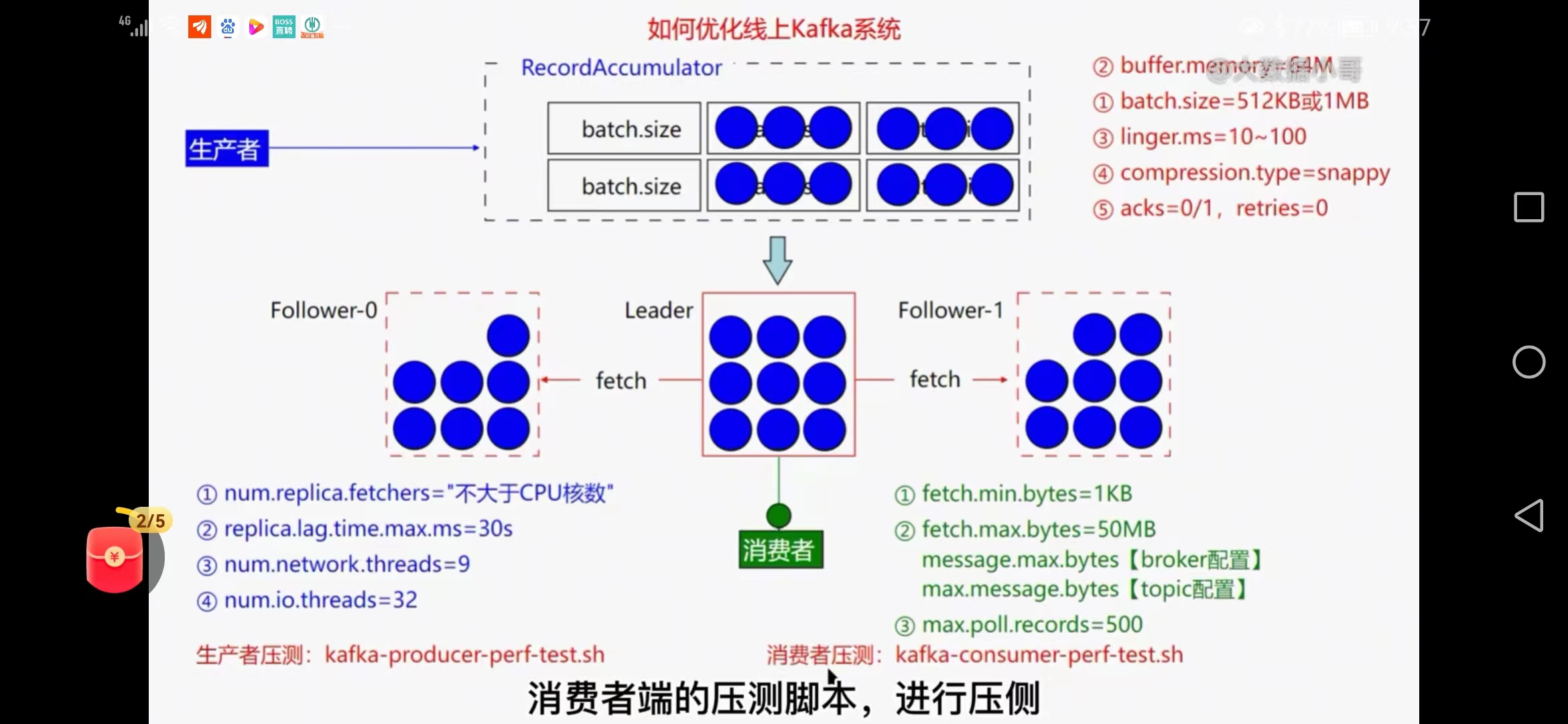
1、吞吐量
2、低延时
生产者
a.batch.size=512kb或1MB(批量数据大小)
b.buffer.memory=64M(缓冲区大小)
c.linger.ms=10-100(毫秒)(是否等待传输)
d.compression.type=snappy(是否压缩)
e.acks=0或1 retries=0(安全系数定,重试次数可以设置小一点)
broker端
f.num.replica.fetchers='不大于cpu的核数'(副本数量)
g.replica.lag.time.max=30s(isr列表复制快速剔除)
f.num.network.threads=9(工作线程数)
g.num.io.threads=32(服务器用于请求的线程数)
消费者
f.fetch.min.bytes=1kb(broker积攒多少条数据就可以返回给cosumer端)
g.fetch.max.bytes=50M(消费者获取一批的最大字节数)
f.message.max.bytes=9(broker配置)
g.max.message.bytes=32(topic配置)
g.max.poll.records=500(一次拉取的条数)
topic端
设置合理的分区数(压测调整)
生产者压测脚本、消费端压测脚本
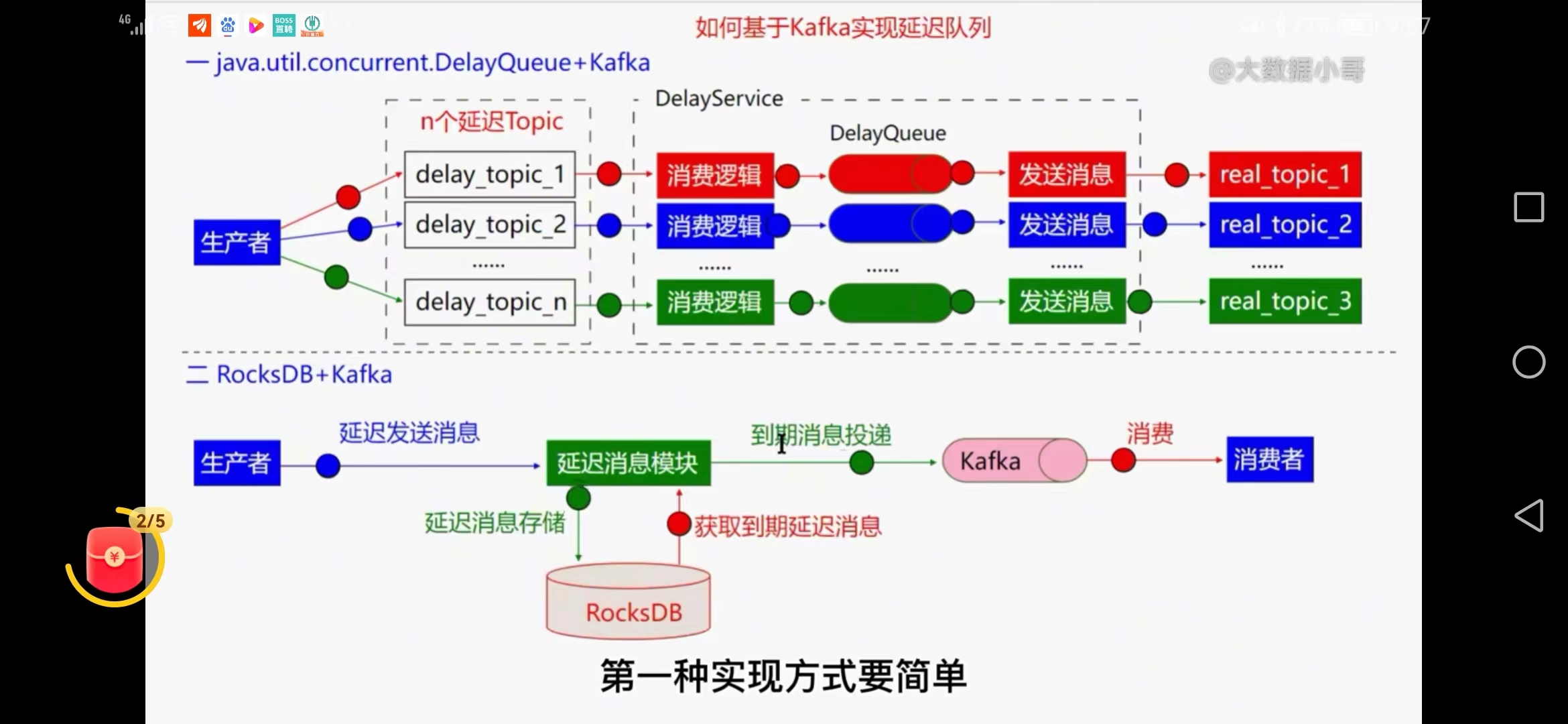
二、kafka实现延迟队列
不适合实现延迟队列,roketmq实现更方便
1、java的delayQueue+kafka实现延迟队列
实现方式:发送消息不直接发送到真实mq,而是发送到内部主题中,对用户不可见
按照5,10秒的延迟等级划分发到多个topic,有一定时间误差,内部有DelayService消费逻辑处理并存储到DelayQueue中
可以在DelayService中计数到达指定值时停止发送到DelayQueue,DelayQueue可以按照投递时间进行排序,最后发送到真实的主题,最后消费者可以在真实的主题中进行消费
虚拟内部主题topic---DelayService用于计数-----DelayQueue------realtopic
问题:不准确时间
2、Rocksdb+kafka实现延迟队列
延迟消费模块 先把消息进Rocksdb 当时间到达再取出来消息放回到kafka中
Rocksdb使用的是LSM算法,适合大量数据写入的场景
结构清晰
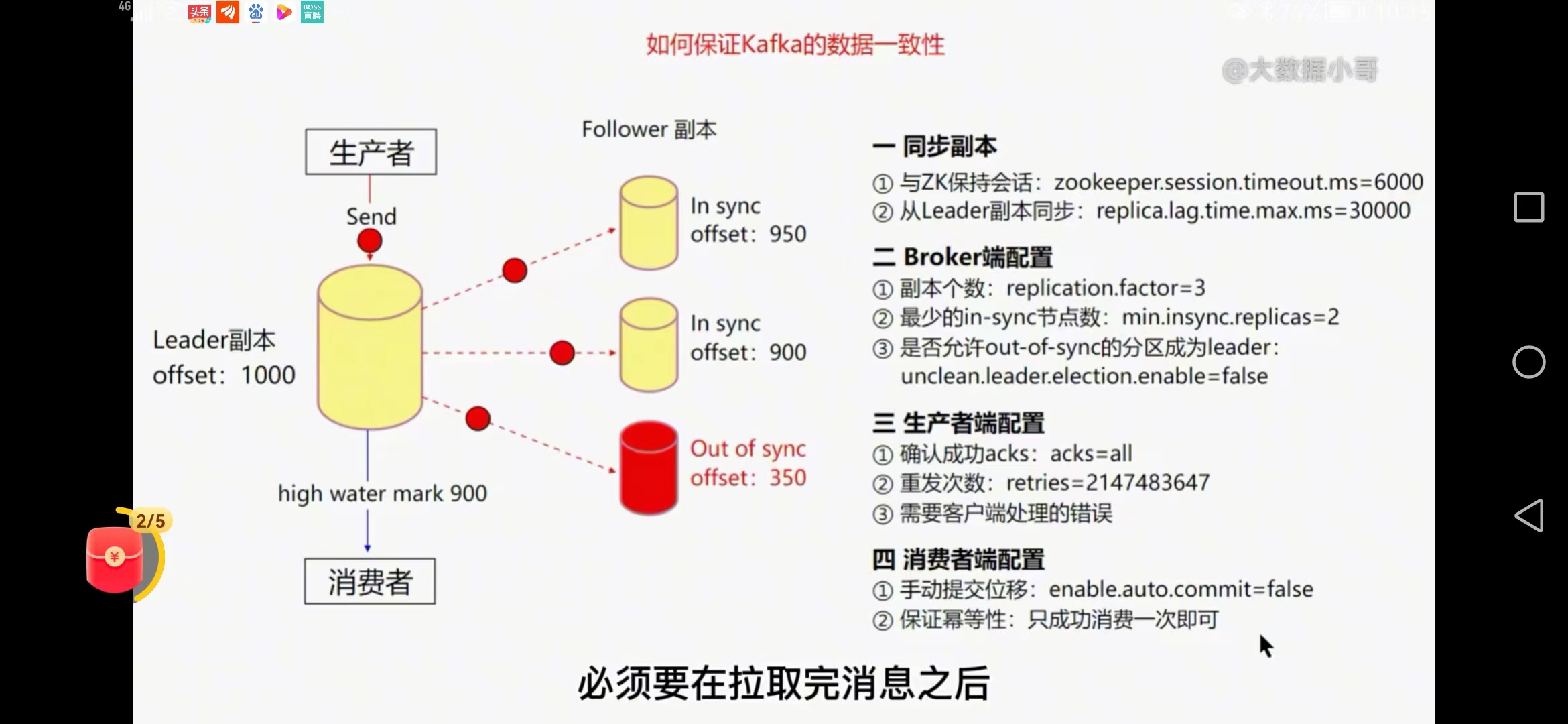
三、如何保障kafka的数据一致性
1、主从副本、
是核心、同步副本
与zk保持会话 zookeeper.session.timeout.ms=6000(副本与zk会话时间保持心跳)
从leader副本同步 replica.lag.time.max=30000(follower最多与leader副本晚30秒内的消息)
副本是个动态的过程,时间过长可能剔除,只用在用副本(in sync)延迟会影响整个kafka的速度,out sync不影响整体速度
2、broker端配置、
beoker的数量一定要大于副本的个数
副本个数 replication.factor=3 (高5低2)
最少的in-sync节点数 min.insync.replicas=2(允许部分副本不可用)
是否允许out-of-sync分区成为leader unclean.leader.election.enable=false
3、生产者、
确认成功acks acks=all
重发次数 retries=2147
需要客户端处理错误
4、消费者可靠性配置
手动提交位移 enable.auto.commit=false
保证幂等性:只成功消费一次即可
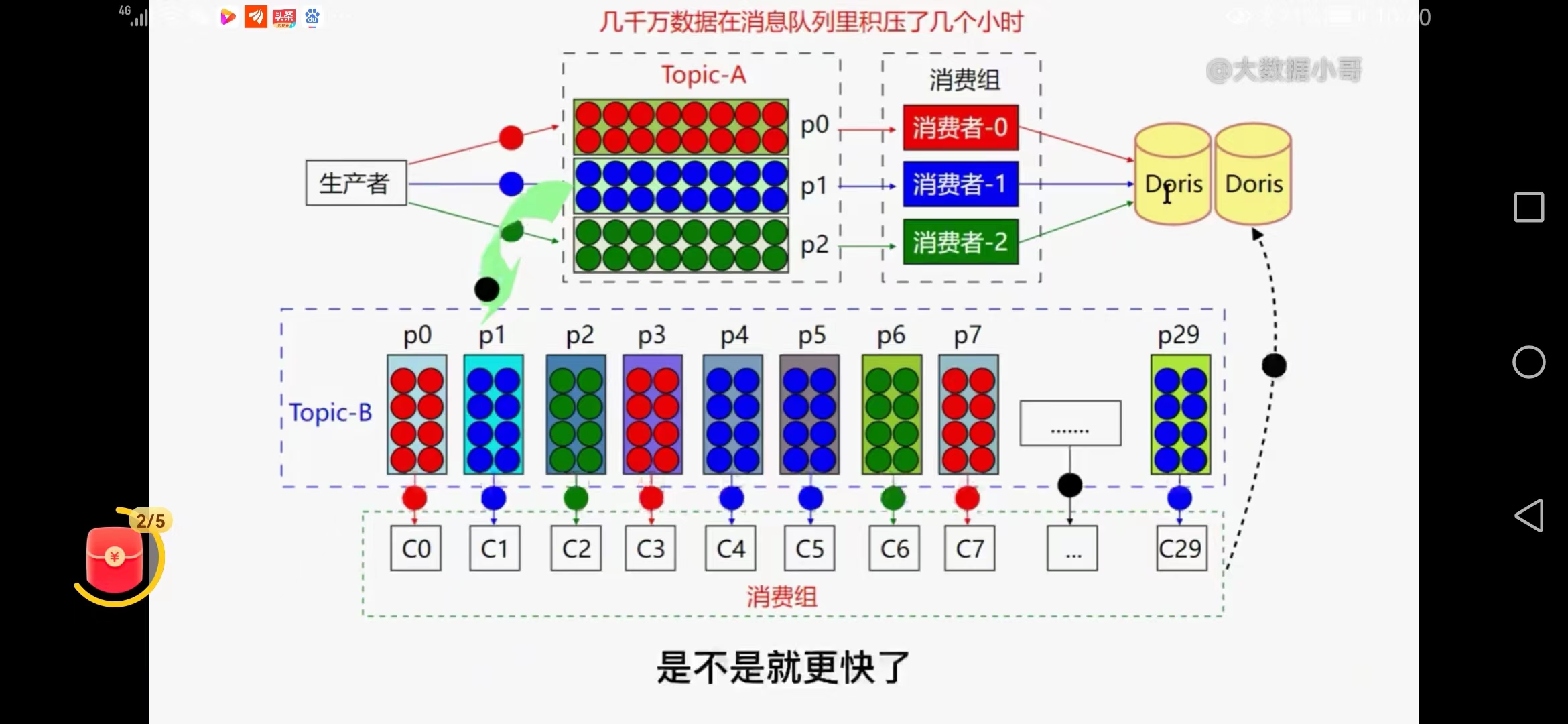
四、线上kafka有大量数据挤压时几千万几个小时,如何处理
产生原因:数据库磁盘满,消费错误
接口处理慢,瞬间消息量大、缓存实现方式慢导致
1、修复consumer程序
快速修复消费方式,增加硬盘或让消息尽量快速消费,需要上线处理,风险高,傻傻等待。。。
2、新建一个topic,临时扩容
新建立consumerb程序,
新建一个topicb,partion扩大为原来的10倍(30个)
把原有topic的数据写到新的topicb中,
再加30台机器快速去启动消费consumerb
问题:硬件+机器,如果程序不健壮可能丢失数据
3、离线+实时增量(lambda架构)
停掉消费者
spark离线计算挤压任务,几分钟处理几千万

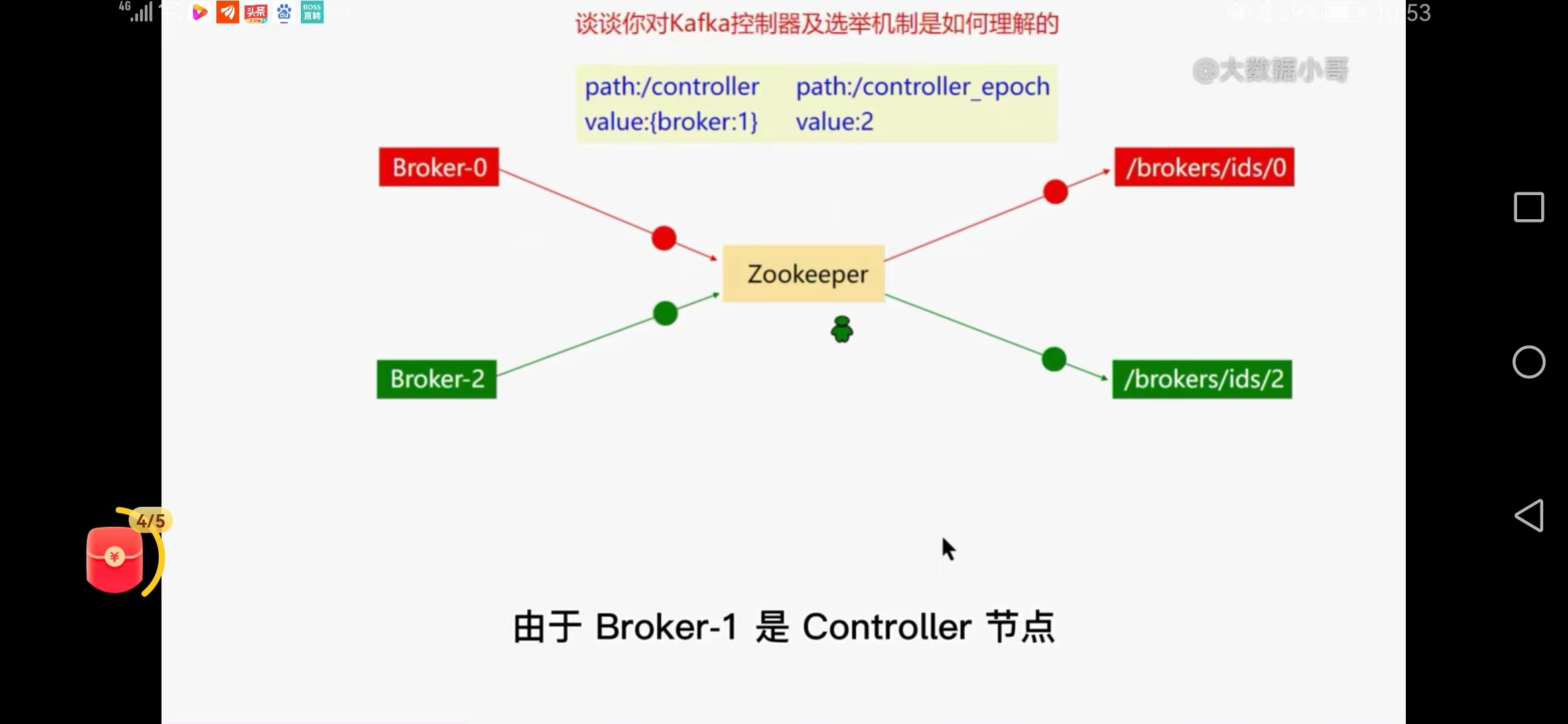
五、谈谈kafka控制器及选举机制的理解
在kafka集群中只能有一个controller存在
zk集群启动----启动broker0----brokers/ids/0
controller-broker0-epoch
启动broker1----brokers/ids/1
启动broker2----brokers/ids/2
controller节点脑裂问题
GC触发原controller挂掉假死
epoch版本号避免脑裂
controller故障如何启动新的controller
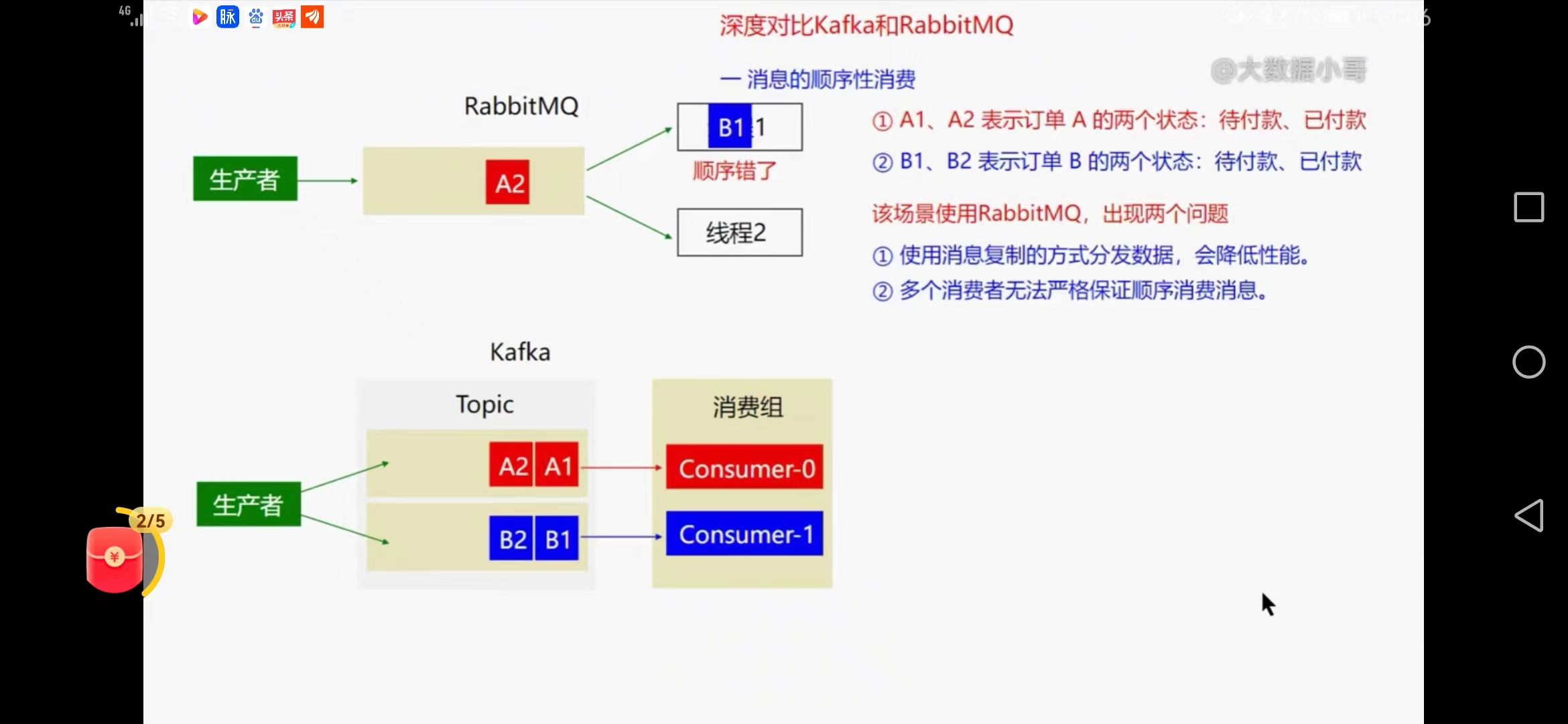
六、深度对比kafka和rabbitmq
1、消息的顺序性消费比对
rabbitmq出现问题
使用消息复制的方式分发数据,会降低性能
多消费者无法严格保证顺序消费消息
2、kafka
可以把同一个订单消息发一个分区
主动拉取消息,没有消息复制过程,不存在消息出错再放回去的情况,吞吐量高,不乱序
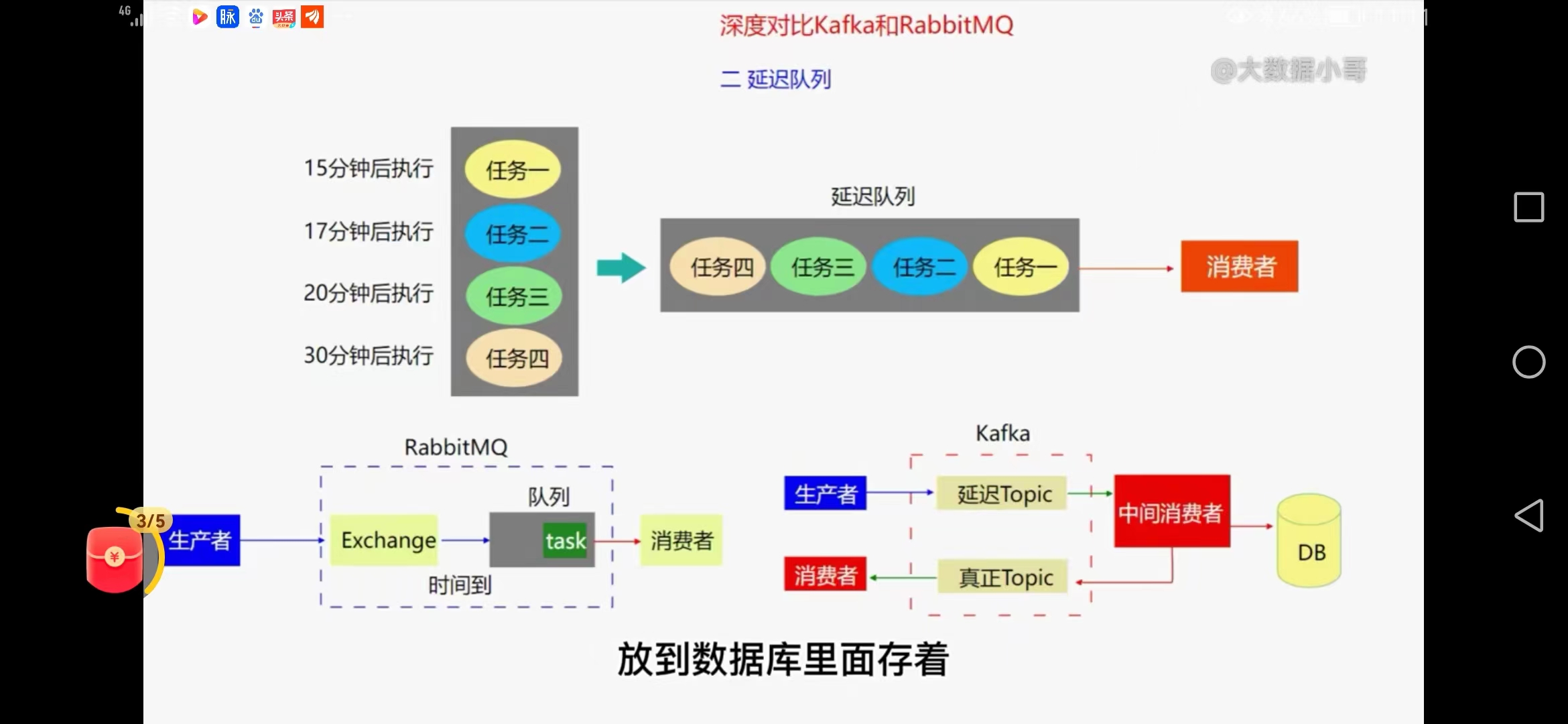
3、延迟队列
rabbitmq合适
有个ttl字段,可以设置消息在队列的时间,超时可以放到延迟队列,exchange在消息到时间才把消息放在真正队列并消费
kafka
实现延迟队列复杂,需要一个临时的topic,自己开发中间消费者,判断延时,可以放在数据库,到时间再放回去。
总结
rabbitmq 安全性可靠
消息的时序控制
高级路由策略实现
kafka 吞吐量大 不能保证多线程消费的顺序性
需要比较严格的顺序消费
消息吞吐量大的场景

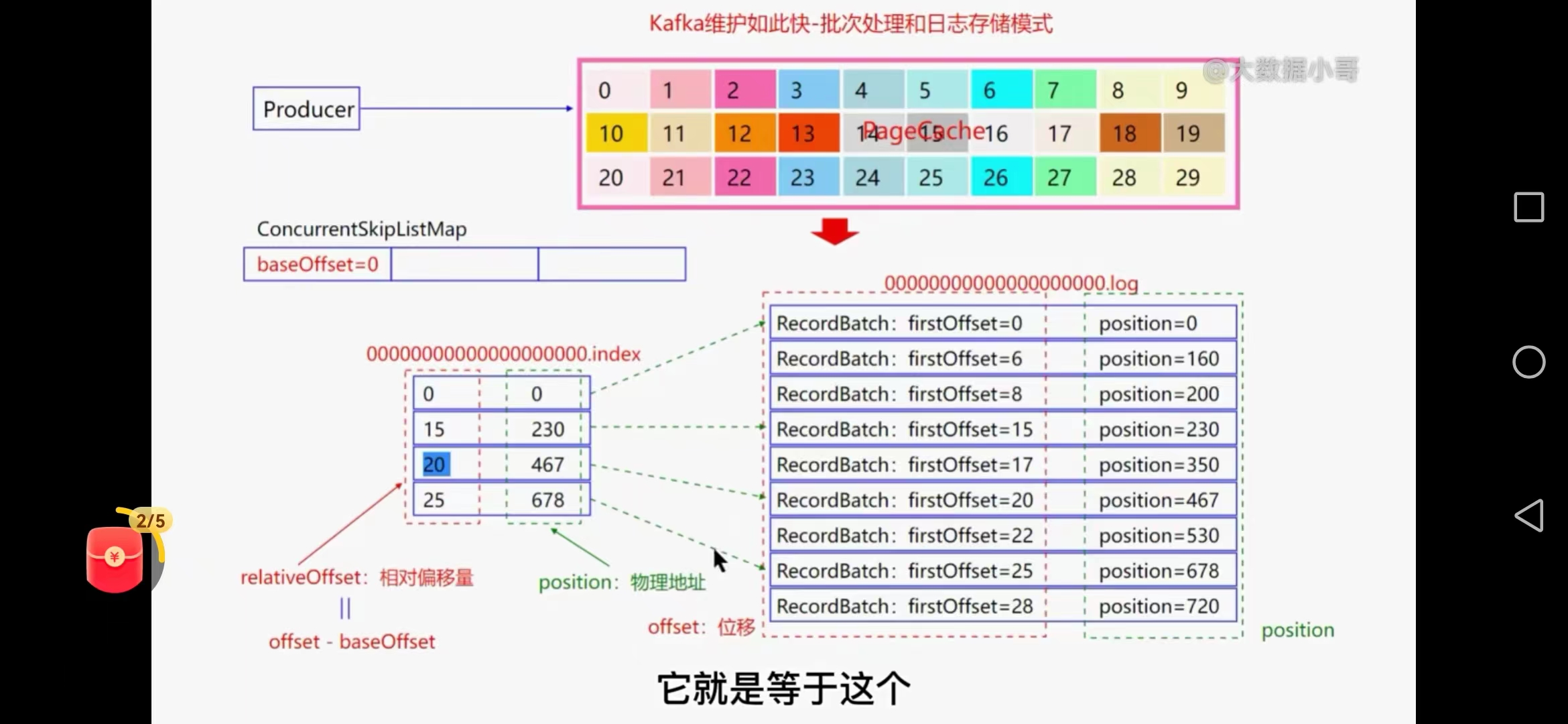
七、kafka批量处理数据和日志存储模式
1、生产者
消息经过拦截器、序列化器、过滤器后把消息写到pagecache中,
当pagecache数据达到10%的时候将会异步顺序追加的方式写入到磁盘中,
为提高吞吐量将一个topic分为多个partion,每个partion会对应一个磁盘的文件夹有数据文件和索引文件,默认1GB
log.segment.bytes=1G(数据文件)
log.index.size.max.bytes=10M(索引文件--内存中)
跳跃表baseoffset 00000.index 批量写入数据
数据文件和索引文件对应关系
八、生产环境大量消息挤压如何处理
加机器+加硬件
提高吞吐量
broker0-partion0-消息-本地缓存-消费者0(每个分区一个消费者)
拉取消息默认500条 max.pull.records=500
当broker0不够500会从其他分区筹齐500条返回数据
kafka只是从分区拉取500条并不会控制哪个分区,容易造成堆积
可以处理流量削峰
在消息加一个key,不同消息分区到一个线程,每个分区一个独立的线程池,通过key取模,保证一个
本地缓存到达一个量时候,可以暂停拉取。

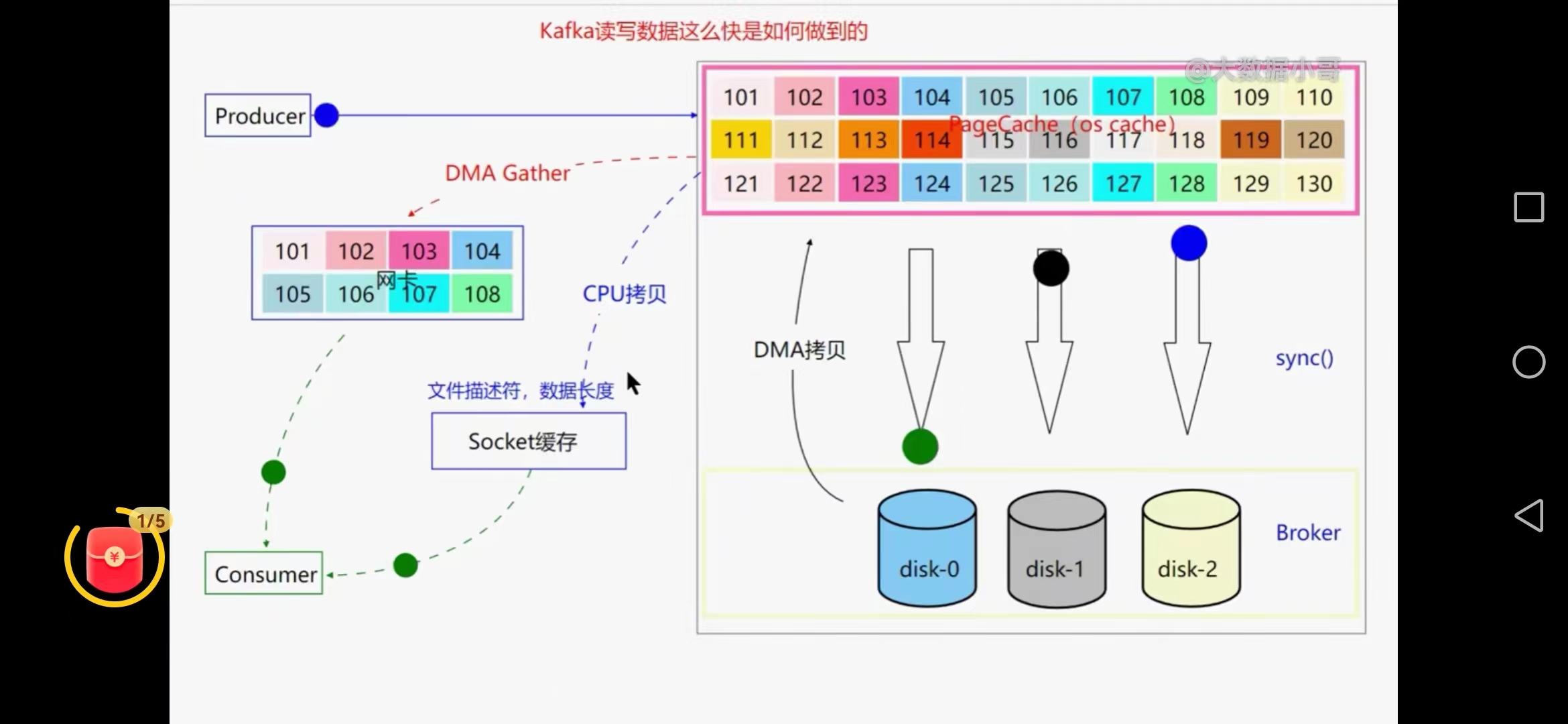
九、kafka读写数据为何这么快
磁盘顺序追加写,pagecache,0拷贝技术、批量发送消息、压缩技术
1、磁盘顺序追加写
顺序追加写,能达到50M每秒,随机磁盘写只能达到300k,减少了磁盘寻址时间及切换
2、pagecache内存空间
mmap内存映射的方式,利用操作系统pagecache异步写数据,操作系统自己管理的内存,
数据写入pagecache,当达到参数内存百分比10%就会批量写磁盘
vm.dirty_backgroud_ratio=10,后台的sync线程就会把数据同步到磁盘上
3、0拷贝技术
通过pagecache把数据拷贝到网卡上去,用户直接可以消费数据,避免了内核态和用户态的拷贝
已经到磁盘的数据采用DMA拷贝技术回到pagecache再同步到网卡(DMA gater)
cpu拷贝只是把文件描述符和数据长度拷贝到socket缓存
0拷贝并不是么有数据拷贝,只是省去了用户态和内核态的数据拷贝,没有cpu数据拷贝过程,但有cpu进行描述符和数据长度的拷贝过程
4、批量发送消息
先把消息堆积到kafka的池化内存中,再分批发送的pagecache中,生产者高吞吐量
5、压缩技术
两个地方用到压缩,生产者端和broker端
消费者解压缩,减少磁盘的带宽
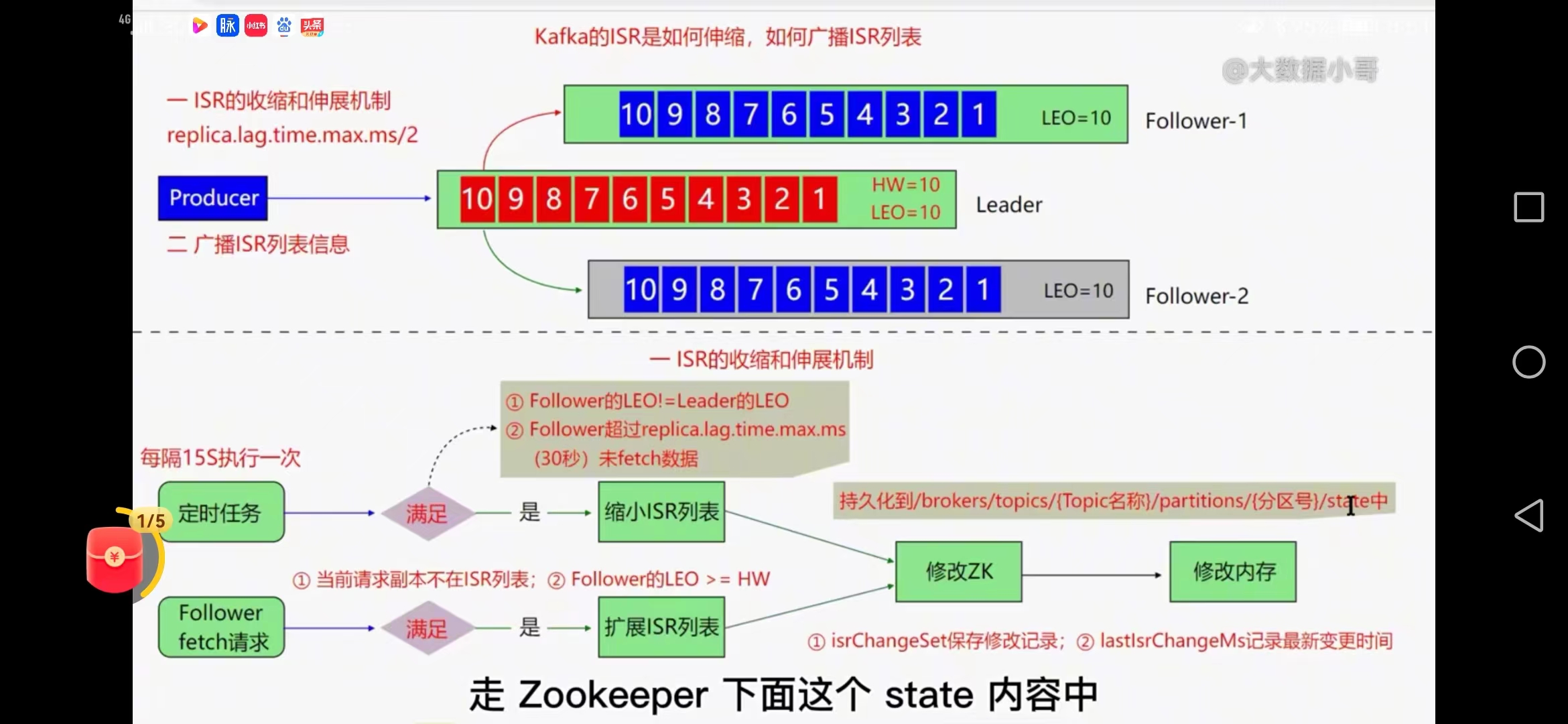
十、kafka的ISR是如何收缩广播
controller节点管理列表,kafka有一个副本管理器replicaManager
1、定时任务
ISR列表的收缩和伸展机制任务
replica.lag.time.max.ms/2(默认30秒)
如果某个节点在30秒follower还没有从leader同步数据会被剔除掉ISR列表
15秒执行一次,
1、检查follower和leader的LEO值是否相等,
2、follower超时时间30秒内未fetch数据
满足两条进行ISR列表收缩,把新的ISR列表同步到zk的持久化映射中
isrchangeset保存修改记录controller中
lastchangeMs记录变更时间controller中
扩展是通过follower节点fetch数据的时候发生
当follower的LEO =HW值就可以满足加入ISr列表中,需要封装isr列表信息
2、广播定时任务
每隔2500毫秒执行一次,满足两个条件进行广播
isrchangeset有变更&&(距离上次修改ISR列表时间超过5秒||距离上次广播时间超过60秒)
广播首先创建zk的永久节点存放isrchange系列号,读取两个内存对象,通过controller节点进行
controller监听isrchange系列号通过结果获取哪部分isr变更后的数据,写到controller自己的内存,广播到所有节点
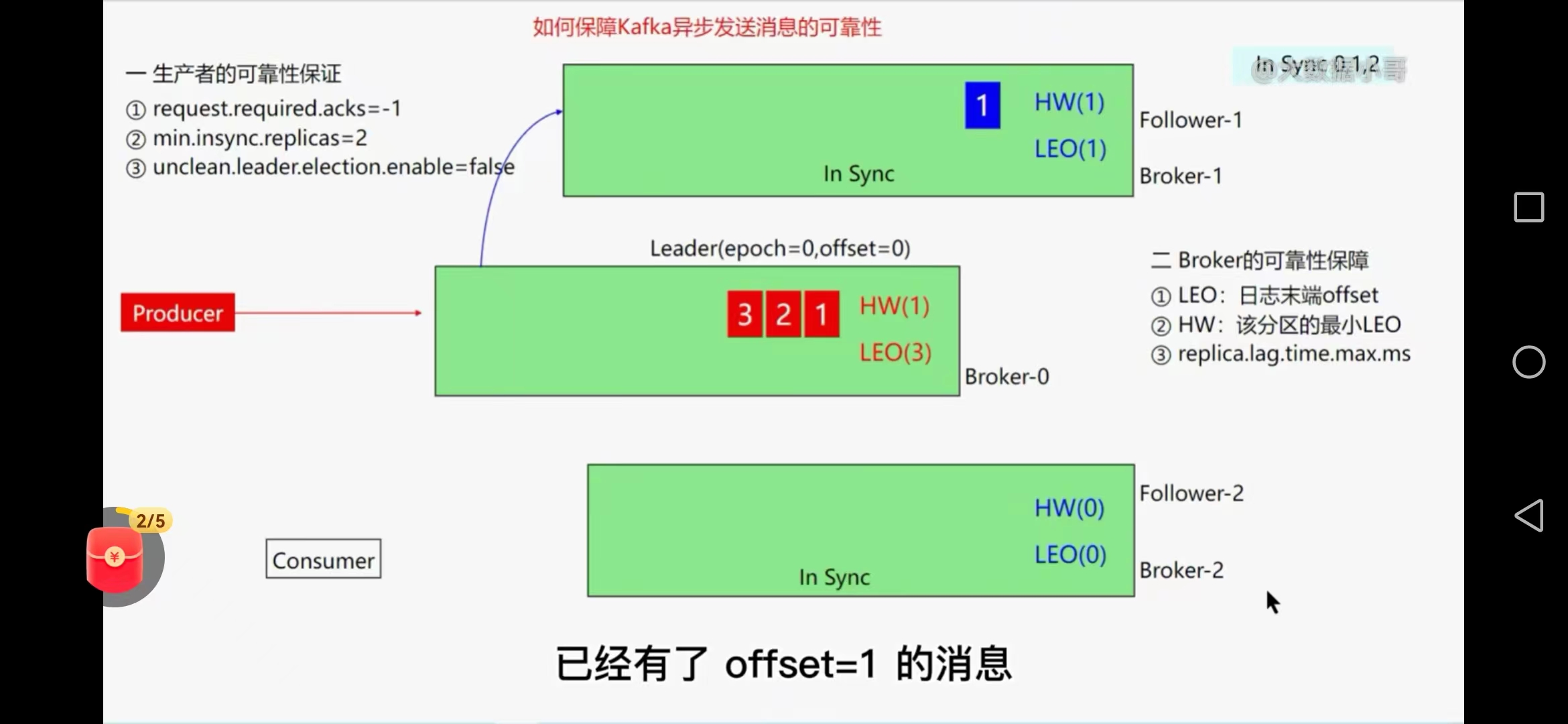
十一、kafka异步发送消息如何保证可靠性
1、生产者可靠性
request.required.acks=-1
所有follower副本从生产者同步信息后才返回ack确认信息
数据重复问题可以通过kafka的事物特性来解决
min.insync.replicas=2
最小同步副本数,当isr的副本数小于这个值时,整个分区就不可用了,通常设置为分区副本的半数以上
太大一个节点故障整个kafka分区不可用
unclean.leader.election.enable=false
客户端都是leader副本进行读写操作
2、broker可靠性保障
LEO 日志末端offset
HW 分区的最小leo值
replica.lag.time.max.ms=30s默认
Kafka优化提升的更多相关文章
- COCOS2DX 3.0 优化提升渲染速度 Auto-batching
COCOS2DX 3.0 优化提升渲染速度 Auto-batching 近期在看COCOS2DX 3.0的Auto-batching合批与Auto Culling动态缩减功能以下就来细致看看吧:整合好 ...
- Kafka性能调优 - Kafka优化的方法
今天,我们将讨论Kafka Performance Tuning.在本文“Kafka性能调优”中,我们将描述在设置集群配置时需要注意的配置.此外,我们将讨论Tuning Kafka Producers ...
- Apache Kafka: 优化部署的10个最佳实践
原文作者:Ben Bromhead 译者:江玮 原文地址:https://www.infoq.com/articles/apache-kafka-best-practices-to-opti ...
- 对JSP和Servlet性能优化,提升执行效率
你的J2EE应用是不是运行的很慢?它们能不能承受住不断上升的访问量?本文讲述了开发高性能.高弹性的JSP页面和Servlet的性能优化技术.其意思是建立尽可能快的并能适应数量增长的用户及其请求.在本文 ...
- 【Odoo】Odoo16-性能优化提升
上海序说科技,专注于基于Odoo项目实施,实现企业数智化,助力企业成长. 老韩头的开发日常,博客园分享(2022年前博文) 10月12日,Odoo16版本正式发布,本文将就Odoo官方在性能方面做的优 ...
- selenium 优化 提升性能
结果: 用时:7.200437545776367s用时:5.909301519393921s headless用时:4.924464702606201s headless\phone用时:4.9358 ...
- 如何利用Nginx的缓冲、缓存优化提升性能
使用缓冲释放后端服务器 反向代理的一个问题是代理大量用户时会增加服务器进程的性能冲击影响.在大多数情况下,可以很大程度上能通过利用Nginx的缓冲和缓存功能减轻. 当代理到另一台服务器,两个不同的连接 ...
- Java动态编译优化——提升编译速度(N倍)
一.前言 最近一直在研究Java8 的动态编译, 并且也被ZipFileIndex$Entry 内存泄漏所困扰,在无意中,看到一个第三方插件的动态编译.并且编译速度是原来的2-3倍.原本打算直接用这个 ...
- Ansible之优化提升执行效率
今天分享一下Ansible在工作环境中有那些可以优化的配置 环境介绍:以前在公司工作处理服务器问题,需要用批量操作都是用shell脚本编写的工具,后来发现Ansible这个自动化工具,安装简单,操作起 ...
- js优化提升访问速度
一.给JS文件减肥. 有的人为了给网站增加炫目效果,往往会使用一些JS效果代码,这在上个世纪似乎还很流行,对于现在来说,最好在用户体验确实需要的情况下,使用这些东西.至于希望给自己的JS文件减肥的童鞋 ...
随机推荐
- 【一步步开发AI运动小程序】六、人体骨骼图绘制
随着人工智能技术的不断发展,阿里体育等IT大厂,推出的"乐动力"."天天跳绳"AI运动APP,让云上运动会.线上运动会.健身打卡.AI体育指导等概念空前火热.那 ...
- npm报错error:0308010C:digital envelope routines::unsupported
error:0308010C:digital envelope routines::unsupported 出现这个错误是因为 node.js V17版本中最近发布的OpenSSL3.0, 而Open ...
- Apache+JK+Tomcat 负载平衡配置
网 上关于 Apache + JK + Tomcat 的集群配置例子很多,按着例子配置下来,基本都能运行,不过,在一些重要的地方却没有进一步的说明.这次公司一个产品就是采用Apache+JK+Tomc ...
- Spring的IOC容器创建过程深入剖析
前言 本次对于Spring的IOC容器的创建过程是基于其源码进行研究分析的,主要涉及BeanFactory的创建过程,Bean的解析与注册过程,Bean实例化的过程以及诸如ClassPathXmlAp ...
- JavaCC : Java Glossary
JavaCC Formerly known as Jack. JavaCC is a parser, like YACC (Yet Another Compiler Compiler), except ...
- 实现ELF文件解析,支持-h, -S, -s
ELF文件 编译和链接 ELF代表Executable and Linkable Format,是类Unix平台最通用的二进制文件格式.下面三种文件的格式都是ELF. 目标文件.o 动态库文件.so ...
- OSG开发笔记(三十七):OSG基于windows平台msvc2017x64编译器官方稳定版本OSG3.4.1搭建环境并移植Demo
前言 自行编译的osg版本插件比较多,如果对版本没有特定要求,但是对环境编译器有特定要求,可以反向融合编译器符合要求的osg版本. OSG下载过程 osg官网:http://www.osg ...
- rocketMQ集群部署
RocketMQ集群部署 RocketMQ是一款非常优秀的消息中间件,运用的场景也是非常丰富,且在各大公司运用中也非常广泛.但是它是如何进行部署的呢,以及它的高可用是如何实现的呢.那么就由我来为大家讲 ...
- sde解除锁定
在sde数据被锁定的情况下,编辑.创建featureclass或者注册版本的时候会报告:Lock request conflicts with an established lock. 方法一:多半情 ...
- ie浏览器设置允许跨域
前情 在访问测试搭建的测试环境的时候,发现接口因为跨域全部失败了,服务端又不想设置允许跨域,又急于使用,于是想到是不是可以使用跨域浏览器,上一次已解决chrome允许跨域,这一次来设置IE允许跨域 放 ...