用python做时间序列预测五:时间序列缺失值处理
有的时候,一些时刻或连续时间段内的值无法采集到,或者本身就没有值,本文将介绍如何处理这种情况。
一般而言,有以下几种方法:
- 对所有的缺失值用零填充。
- 前向填充:比如用周一的值填充缺失的周二的值
- 后向填充:比如用周二的值填充缺失的周一的值
- 采用n最近邻均值法填充:比如n取2,则用t-2,t-1,t+1,t+2时刻的平均值来填充缺失的t时刻的值。
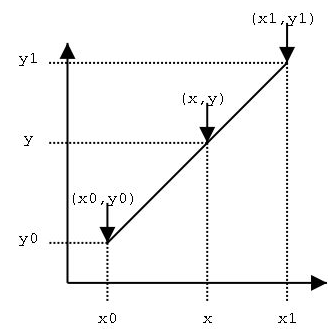
- 单线性插值:取某个缺失值的时间点,做一条垂线相较于左右时刻的值的连接线,得到的交点作为填充值。类似下图:
对应的python代码实现:
from sklearn.metrics import mean_squared_error
df_orig = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/a10.csv', parse_dates=['date'], index_col='date').head(100)
df = pd.read_csv('datasets/a10_missings.csv', parse_dates=['date'], index_col='date')
fig, axes = plt.subplots(7, 1, sharex=True, figsize=(10, 12))
plt.rcParams.update({'xtick.bottom' : False})
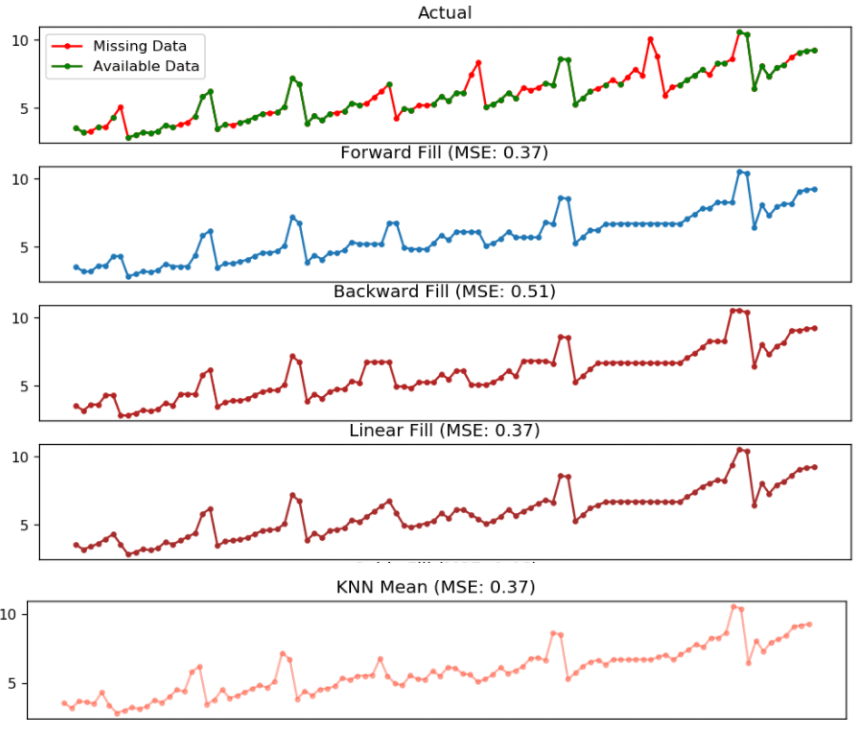
## 1. Actual -------------------------------
df_orig.plot(title='Actual', ax=axes[0], label='Actual', color='red', style=".-")
df.plot(title='Actual', ax=axes[0], label='Actual', color='green', style=".-")
axes[0].legend(["Missing Data", "Available Data"])
## 2. Forward Fill --------------------------
df_ffill = df.ffill()
error = np.round(mean_squared_error(df_orig['value'], df_ffill['value']), 2)
df_ffill['value'].plot(title='Forward Fill (MSE: ' + str(error) +")", ax=axes[1], label='Forward Fill', style=".-")
## 3. Backward Fill -------------------------
df_bfill = df.bfill()
error = np.round(mean_squared_error(df_orig['value'], df_bfill['value']), 2)
df_bfill['value'].plot(title="Backward Fill (MSE: " + str(error) +")", ax=axes[2], label='Back Fill', color='firebrick', style=".-")
## 4. Linear Interpolation ------------------
df['rownum'] = np.arange(df.shape[0])
df_nona = df.dropna(subset = ['value'])
f = interp1d(df_nona['rownum'], df_nona['value'])
df['linear_fill'] = f(df['rownum'])
error = np.round(mean_squared_error(df_orig['value'], df['linear_fill']), 2)
df['linear_fill'].plot(title="Linear Fill (MSE: " + str(error) +")", ax=axes[3], label='Cubic Fill', color='brown', style=".-")
## 5. Mean of 'n' Nearest Past Neighbors ------def knn_mean(ts, n):
out = np.copy(ts)
for i, val in enumerate(ts):
if np.isnan(val):
n_by_2 = np.ceil(n/2)
lower = np.max([0, int(i-n_by_2)])
upper = np.min([len(ts)+1, int(i+n_by_2)])
ts_near = np.concatenate([ts[lower:i], ts[i:upper]])
out[i] = np.nanmean(ts_near)
return out
df['knn_mean'] = knn_mean(df.value.values, 8)
error = np.round(mean_squared_error(df_orig['value'], df['knn_mean']), 2)
df['knn_mean'].plot(title="KNN Mean (MSE: " + str(error) +")", ax=axes[5], label='KNN Mean', color='tomato', alpha=0.5, style=".-")
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
用python做时间序列预测五:时间序列缺失值处理的更多相关文章
- python做中学(五)多线程的用法
多线程类似于同时执行多个不同程序,多线程运行有如下优点: 使用线程可以把占据长时间的程序中的任务放到后台去处理. 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条 ...
- 用python做时间序列预测一:初识概念
利用时间序列预测方法,我们可以基于历史的情况来预测未来的情况.比如共享单车每日租车数,食堂每日就餐人数等等,都是基于各自历史的情况来预测的. 什么是时间序列? 时间序列,是指同一个变量在连续且固定的时 ...
- 用python做时间序列预测九:ARIMA模型简介
本篇介绍时间序列预测常用的ARIMA模型,通过了解本篇内容,将可以使用ARIMA预测一个时间序列. 什么是ARIMA? ARIMA是'Auto Regressive Integrated Moving ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- facebook开源的prophet时间序列预测工具---识别多种周期性、趋势性(线性,logistic)、节假日效应,以及部分异常值
简单使用 代码如下 这是官网的quickstart的内容,csv文件也可以下到,这个入门以后后面调试加入其它参数就很简单了. import pandas as pd import numpy as n ...
- 腾讯技术工程 | 基于Prophet的时间序列预测
预测未来永远是一件让人兴奋而又神奇的事.为此,人们研究了许多时间序列预测模型.然而,大部分的时间序列模型都因为预测的问题过于复杂而效果不理想.这是因为时间序列预测不光需要大量的统计知识,更重要的是它需 ...
- Kesci: Keras 实现 LSTM——时间序列预测
博主之前参与的一个科研项目是用 LSTM 结合 Attention 机制依据作物生长期内气象环境因素预测作物产量.本篇博客将介绍如何用 keras 深度学习的框架搭建 LSTM 模型对时间序列做预测. ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- 上篇 | 使用 🤗 Transformers 进行概率时间序列预测
介绍 时间序列预测是一个重要的科学和商业问题,因此最近通过使用基于深度学习 而不是经典方法的模型也涌现出诸多创新.ARIMA 等经典方法与新颖的深度学习方法之间的一个重要区别如下. 概率预测 通常,经 ...
随机推荐
- .net core想到哪写道哪之hello world
今天,我们来创建一个helo world,讲一讲.Net 6最新的顶级语句的问题. 在.Net 6中最大的变化应该就是多了个顶级语句. 这玩意是个啥呢,它让C#看起来像个脚本语言了,一个Hello W ...
- Mysql8.0修改配置参数lower_case_table_names
现象 今天在配置一个环境的数据库,所使用的系统要求该数据库 lower_case_table_names = 1 (对数据库表明.列名大小写不敏感) 我看了一下,在 Windows 上,默认值为 1. ...
- 【并查集+dfs】codeforces 1833 E. Round Dance
题意 输入一个正整数 \(T(1 \leq T \leq 10^4)\),表示接下来输入 \(T\) 组测试用例,对于每一个测试用例: 第一行,输入一个正整数 \(n(2 \leq n \leq 2 ...
- GooseFS 在云端数据湖存储上的降本增效实践
| 导语 基于云端对象存储的大数据和数据湖存算分离场景已经被广泛铺开,计算节点的独立扩缩容极大地优化了系统的整体运行和维护成本,云端对象存储的无限容量与高吞吐也保证了计算任务的高效和稳定.然而,云 ...
- 数据湖加速器GooseFS,加速湖上数据分析性能
数据湖加速器 GooseFS 是由腾讯云推出的高性能.高可用.弹性的分布式缓存方案.依靠对象存储(Cloud Object Storage,COS)作为数据湖存储底座的成本优势,为数据湖生态中的计算应 ...
- 浅聊web前端性能测试
最近正好在做web前端的性能测试,这次就来聊聊关于这个的测试思路~ 首先从用户的思维去思考,关于web前端性能,用户最看重的是什么...... 其实就是下面三个点: 1. 加载性能(即页面加载时间+资 ...
- Linux新用户登录时出现“-bash-4.2$”的解决办法
Linux服务器新建的用户在登录时显示"-bash-4.2$",而不是"user@hostname"的显示方式,出现此问题的原因是在添加普通用户时,用户家目录下 ...
- NACOS MalformedInputException 无法读取中文配置问题
1. 问题描述 在windows平台中打包运行springboot jar包提示如下错误 在idea中运行正常 org.yaml.snakeyaml.error.YAMLException: java ...
- intellij idea 自动生成test单元测试
1. 创建测试类 打开IDEA,在任意类名,任意接口名上,按ctrl+shift+t选择Create New Test image 然后根据提示操作(默认即可),点击确认,就在项目的/test/j ...
- 管理员应了解的 SIEM解决方案七大功能 !
SIEM解决方案已成为企业网络安全武器库中不可或缺的一部分.但由于SIEM功能过于复杂且架构难以理解,企业往往SIEM的潜在功能.遗憾的是,他们忽视的潜在功能正是解开企业网络合规的重要部分. 例如, ...