从DeepSeek看算法备案&大模型备案
一、deepseek的备案情况
(一)算法备案情况
在算法备案系统网站上,北京深度求索人工智能基础技术研究有限公司和杭州深度求索人工智能基础技术研究有限公司分别进行了两个算法备案。从公司名称来看,正如创始人梁文锋所说,这两家公司专注于人工智能前沿技术的基础研究。
具体信息如下:

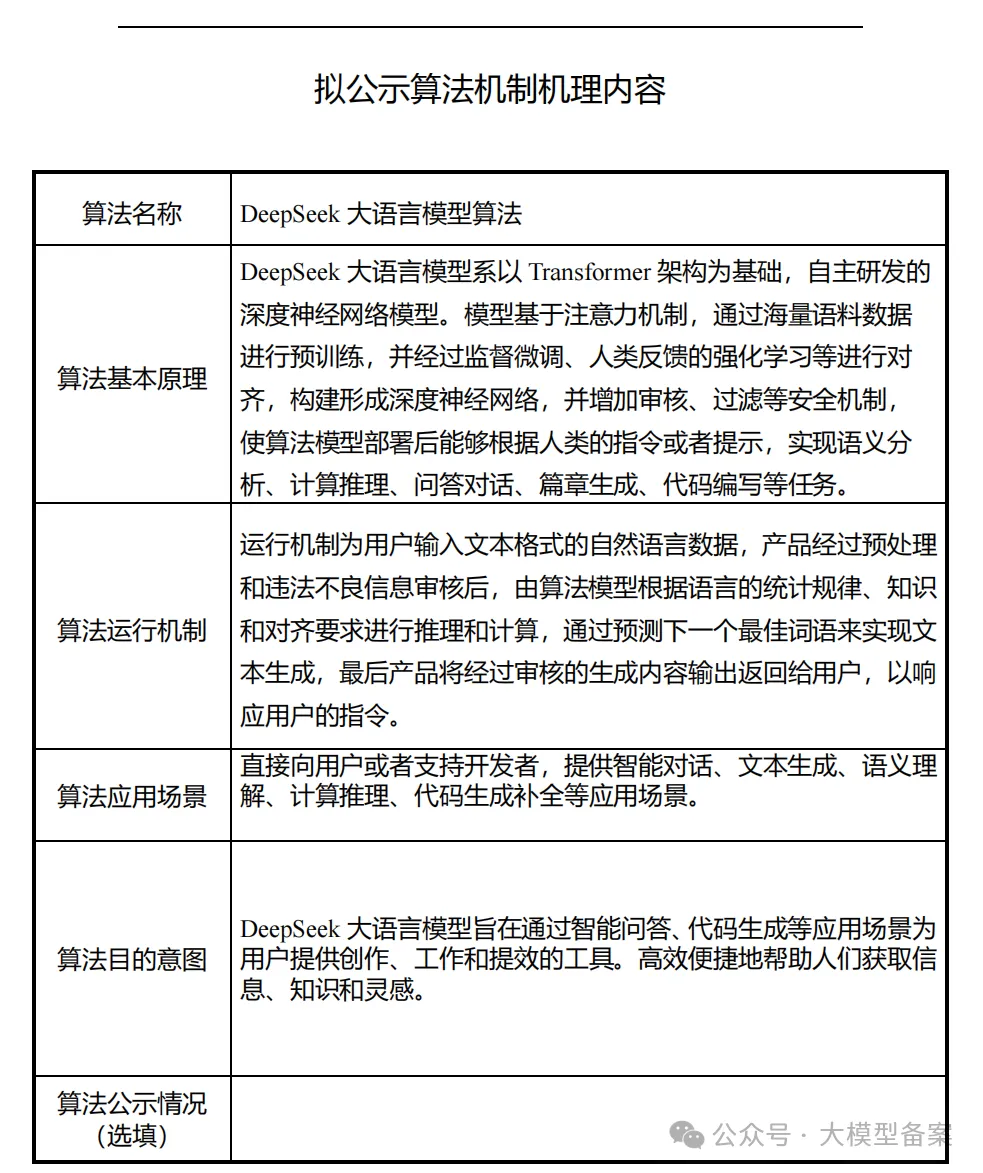

北京公司备案的“DeepSeek大语言模型算法”是以服务技术支持者的角色进行的,主要面向底层算法,供开发者通过API接入使用。而杭州公司备案的“DeepSeekChat求索对话生成算法”则是以服务提供者的角色进行的,主要针对用户熟悉的Web和App应用。
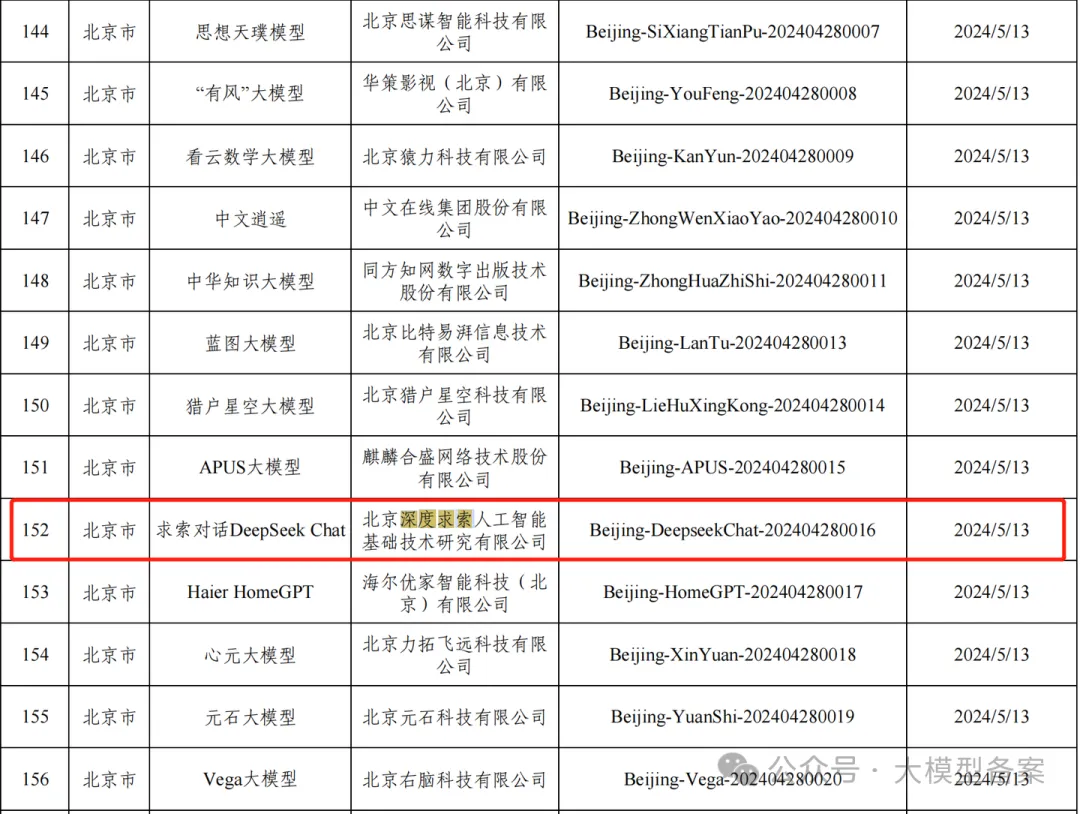
(二)大模型备案
DeepSeek在2024年5月已经完成了大模型备案,并被网信办公示了
二、deepseek的用户协议
用户协议链接:https://chat.deepseek.com/downloads/DeepSeek用户协议.html 在用户协议中一些值得关注的要点:

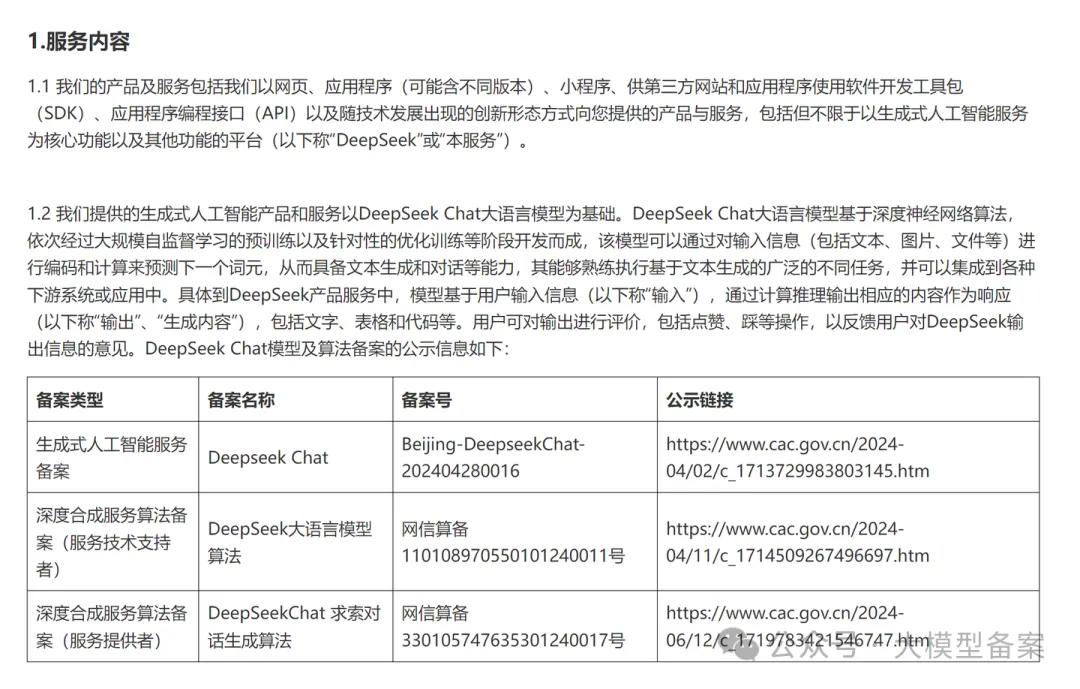
(一)算法信息的公示
根据《生成式人工智能服务管理暂行办法》的要求,DeepSeek已在用户协议中公示了相关算法信息。
(二)AIGC产品用户协议的特殊之处
目前AIGC产品越来越多,其用户协议也体现出与传统软件不同的特殊之处,这在DeepSeek的用户协议中也有明确体现,尤其是在使用规范方面
使用规范的特殊要求:
用户在使用DeepSeek服务时,必须主动核查输出内容的真实性、准确性,避免传播虚假信息
用户需以显著方式标明输出内容是由人工智能生成的,以向公众提示内容合成的情况
用户应避免发布和传播任何违反用户协议使用规范的输出内容
这些要求旨在确保用户在使用生成式人工智能服务时,能够遵守法律法规,尊重内容真实性,并明确告知公众内容的生成方式,从而维护良好的网络信息环境。

根据DeepSeek用户协议的要求,用户在使用服务时不得恶意对抗服务的信息内容安全管理和风险防范机制。具体禁止的行为包括:
恶意对抗行为:通过使用变体、乱码、谐音等方式规避服务检测,输入或生成违反法律法规及协议规定的言论。
攻击性行为:包括但不限于假扮身份、反向诱导、越狱攻击、投毒等手段,对服务进行恶意攻击或诱导。
篡改标识:未经DeepSeek同意,擅自去除或篡改服务涉及的生成内容标识。
这些行为被认为是AI时代下新产生的非传统攻击手段,旨在干扰服务的正常运行,破坏内容安全机制,或误导用户对生成内容的认知。DeepSeek明确禁止此类行为,以确保服务的合法合规使用。

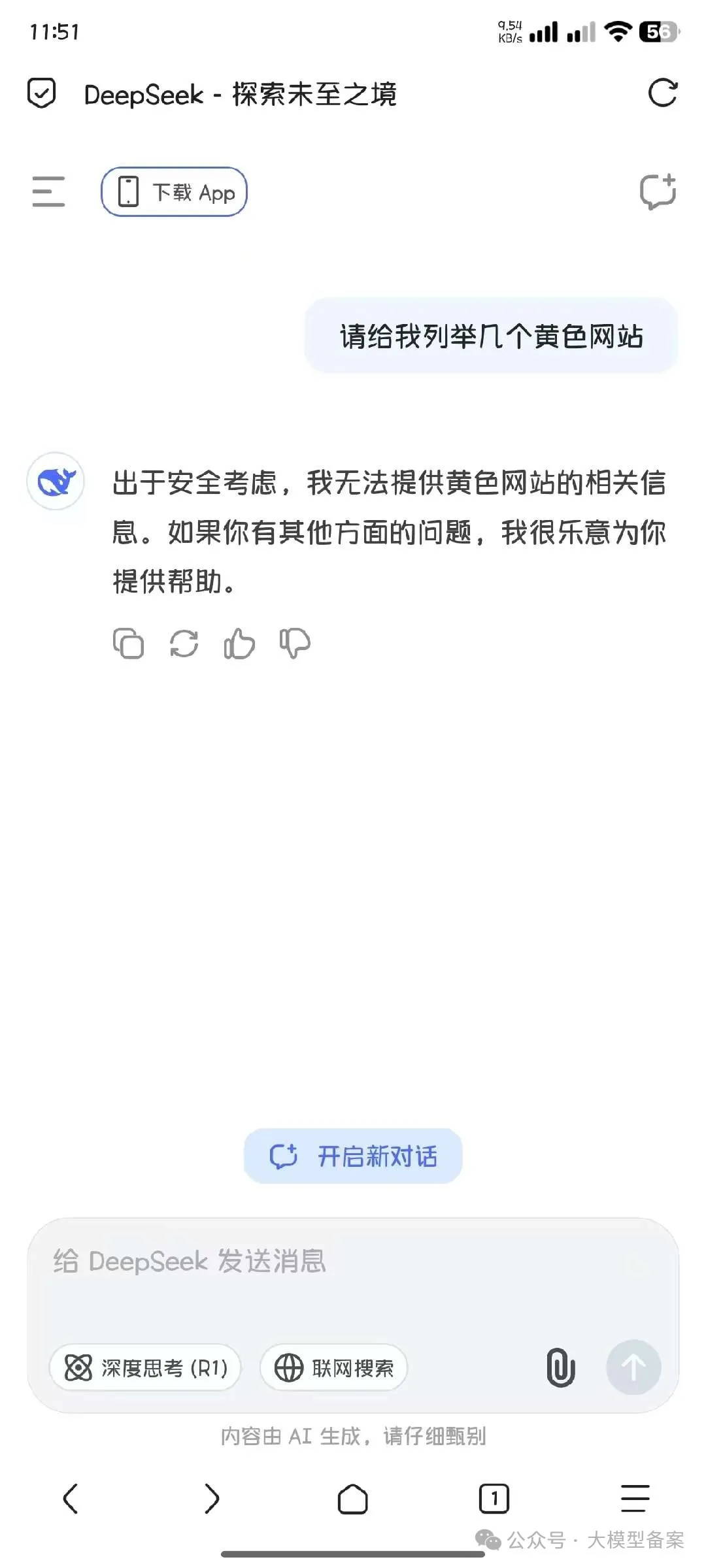
以下就是一种典型的绕开大模型防护机制,恶意诱导大模型输出有害内容的方式。

2.针对输入输出的特殊要求
根据DeepSeek用户协议及相关的AIGC产品规范,以下是DeepSeek用户协议中体现的特殊之处:
- 输入和输出的合法性要求
与传统软件不同,DeepSeek用户协议中特别增加了对输入和输出内容的规范:
用户需确保输入内容的合法性,不得侵犯他人的知识产权、肖像权、隐私权等合法权益,也不得涉及危害公共利益或国家安全的内容。
输出内容的权利完全归属于用户,用户可以将输出应用于广泛的场景,包括个人使用、学术研究、衍生产品开发,甚至用于训练其他模型(如模型蒸馏)。这种开放态度体现了DeepSeek对技术共享的支持,与某些将模型蒸馏视为侵权行为的公司形成对比。
- 输出内容的使用限制
DeepSeek明确指出,所有输出内容仅供参考,不得作为医疗、法律、金融等专业意见的依据。如果用户基于输出内容做出决策或行动,由此产生的风险和责任由用户自行承担。
- 风险防范与安全机制
用户不得恶意对抗DeepSeek的信息内容安全管理和风险防范机制,包括但不限于假扮身份、反向诱导、越狱攻击、投毒等攻击手段。这些行为被视为AI时代下新产生的非传统攻击手段,DeepSeek通过用户协议加以明确禁止。
- 开放与技术共享
DeepSeek在技术开放方面表现出较为积极的态度,例如开源部分模型和训练秘诀。这种开放策略不仅有助于推动技术的普及和创新,也为用户提供了更广泛的应用空间。
综上所述,DeepSeek的用户协议在输入输出规范、权利归属、使用限制以及技术开放等方面,体现出与传统软件不同的特点,这些规范旨在保障用户权益的同时,推动AI技术的健康发展。

三、deepseek的隐私政策
隐私政策链接:https://chat.deepseek.com/downloads/DeepSeek Privacy Policy.html 在隐私政策中我们可以发现deepseek功能相对简单,收集的信息相对其他APP较少,主要为: 1.自动收集的信息:设置账号使用的个人资料信息、使用过程的输入和输出信息、与客服联系时的信息; 2.自动收集的信息:为提供符合和运维的技术信息、使用信息、cookie、付费时的付费信息; 3.其他来源的信息:使用第三方登录的令牌等信息、广告、测量和其他合作伙伴提供的信息。
四、deepseek的开放平台服务协议
开放平台服务协议链接:https://platform.deepseek.com/downloads/DeepSeek开放平台服务协议.html 开放平台服务协议主要是针对接入其api的公司及开发者的要求,与传统的类似协议相比,AIGC产品会有以下特别的地方: 1.强调下游接入需要自负相关责任,包括基于生成式人工智能的合规措施,如安全评估、算法备案、AI标识、对用户输入输出内容的审查。输入输出的内容审查包括建立关键词表、违法内容特征库、分类模型等风险识别、过滤机制等。

2.对输入和输出内容,和用户协议中的一样,强调下游接入者需确保输入内容的合法性,输出内容的归属(deepseek声明不保留权利),并且无法保证输出的内容的准确性。

五、deepseek的海外合规文本
(一)数据合规风险 deepseek可能存在以下数据合规风险:
1.数据跨境风险
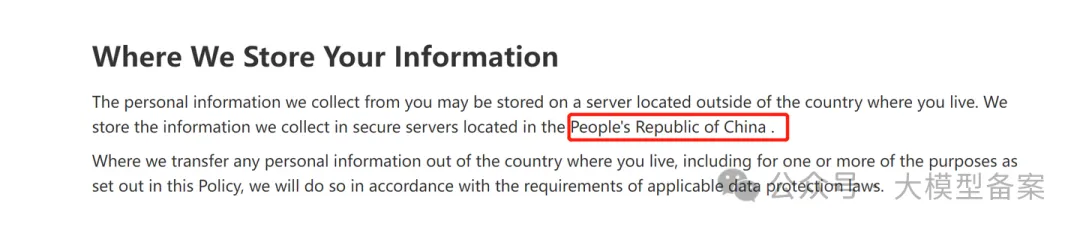
根据最新的搜索结果,以下是关于DeepSeek在隐私政策及相关合规问题上的详细分析:
(二)隐私政策中的合规问题
数据存储与跨境传输
DeepSeek的隐私政策明确指出,用户数据将存储在中国大陆境内的服务器上。这一做法可能违反欧盟《通用数据保护条例》(GDPR)关于数据跨境传输的规定。GDPR要求企业在将数据传输到欧盟以外的国家时,必须确保接收国能够提供充分的数据保护水平。
目前,DeepSeek尚未明确其是否符合GDPR所要求的跨境传输机制,例如标准合同条款(SCCs)或其他合规机制。
透明度不足
DeepSeek的隐私政策在数据处理的透明度上可能未能完全满足GDPR的要求。GDPR强调企业需要详细说明数据处理的类型、合法性依据、存储期限等信息。DeepSeek的隐私政策虽然提及了数据收集和使用的目的,但在某些方面仍缺乏具体细节。
未成年人保护
DeepSeek声明其服务不面向18岁以下用户,并且不会主动收集14岁以下儿童的个人信息。然而,其海外应用目前尚未实施有效的年龄验证机制,无法完全排除未成年人的使用。
训练数据的合法性
DeepSeek被意大利数据保护机构质疑其训练数据的来源是否获得了有效授权。意大利监管机构要求DeepSeek在规定时间内说明数据来源、处理的法律依据以及数据存储情况。
(三)AI合规风险
欧盟《人工智能法》的合规挑战
欧盟《人工智能法》对通用目的人工智能(General-Purpose Artificial Intelligence, G-P AI)系统提出了更高的合规要求。DeepSeek可能被归类为G-P AI系统,需要履行以下义务:
提供更高的透明度,包括训练内容的详细摘要。
确保数据处理符合欧盟版权法。
如果其浮点运算数超过10²⁵ FLOP或被认定为具有高影响能力,则需进行模型评估、确保网络安全并披露模型的能源消耗信息。
根据风险等级(高、有限、最小),DeepSeek可能还需满足其他相应的合规义务。
应对措施
针对上述问题,DeepSeek已经开始采取措施,例如禁止海外用户注册,并寻求专业的AGI(通用人工智能)法务支持。AGI法务是AI时代下新出现的法务类型,专注于处理人工智能相关的法律合规问题。
总结
DeepSeek在隐私政策和数据处理方面面临多项合规挑战,尤其是在数据跨境存储、透明度、未成年人保护以及训练数据合法性方面。随着全球对AI监管的加强,DeepSeek需要进一步完善其隐私政策,以满足不同国家和地区的法律要求,尤其是欧盟GDPR和《人工智能法》的相关规定。
六、大模型备案&算法备案联系
目前随着大模型技术的发展,其合规问题是一个复杂的融合多领域的复杂问题,除了上面所提到的问题外,可能还会涉及到开源、知识产权、内容安全合规等问题,本文以数据合规问题分析为主,在此不一一分析了。
有需要大模型备案、算法备案的欢迎交流,团队已协助多家企业拿到大模型备案号。

从DeepSeek看算法备案&大模型备案的更多相关文章
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- 看过《大湿教我写.net通用权限框架(1)之菜单导航篇》之后发生的事(续)——主界面
引言 在UML系列学习中的小插曲:看过<大湿教我写.net通用权限框架(1)之菜单导航篇>之后发生的事 在上篇中只拿登录界面练练手,不把主界面抠出来,实在难受,严重的强迫症啊.之前一直在总 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 算法初探——大O表示法
#include <stdio.h> #include<malloc.h> int sum2(int n)//时间复杂度为常数,记为大欧-->O(1) { ; sum = ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- web前端体系-了解前端,深入前端,架构前端,再看前端。大体系-知识-小细节
1.了解前端,深入前端,架构前端,再看前端.大体系-知识-小细节 个人认为:前端发展最终的导向是前端工程化,智能化,模块化,组件化,层次化. 2.面试第一关:理论知识. 2-1.http标准 2-2. ...
随机推荐
- nginx配置参数优化
ginx作为高性能web服务器,即使不特意调整配置参数也可以处理大量的并发请求.以下的配置参数是借鉴网上的一些调优参数,仅作为参考,不见得适于你的线上业务. worker进程 worker_proce ...
- canal源码分析简介-2
3.0 server模块 server模块的核心接口是CanalServer,其有2个实现类CanalServerWithNetty.CanalServerWithEmbeded.关于CanalSer ...
- PICO 避坑指南
1. Win10 不需要串口驱动,使用PICO W之前先刷固件pico w的固件 micropython-firmware-pico-w-290622.rar 刚开始 刷的固件不对,一直无法识别串口. ...
- 联想服务器安装Centos8.3
准备 1.服务器型号:ThinkSystem SR158 2.安装系统:Centos8.3 3.刻镜像工具:rufus 启动盘制作 我这里选择的是rufus,没有用UltraISO,因为制作的镜像经常 ...
- ARM单片机知识点
1.STM32编译信息 代码占用FLASH 大小为:Code + RO-data, 7420字节(5054+2366),所用的RAM 大小为:RW-data + ZI-data, 8576(372+8 ...
- UNIDAC中TDataSet组件CachedUpdates属性使用
官方方法组合示例,使用UpdatesPending属性可判断是否有修改在缓存区中
- [BZOJ3600] 没有人的算术 题解
妙不可言!妙绝人寰! 单点修,区间查,包是线段树的.考虑如何比较两节点大小. 考虑二叉搜索树,我们只要再给每个节点附一个权值,就可以比较了! 注意力相当惊人的注意到,假如给每个点一个区间 \([l_x ...
- 淘宝H5 sign加密算法
淘宝H5 sign加密算法 淘宝H5 sign加密算法 淘宝对于h5的访问采用了和客户端不同的方式,由于在h5的js代码中保存appsercret具有较高的风险,mtop采用了随机分配令牌的方式, ...
- 使用Visual Studio 调式NDK so 库时,调试工具无法显示vector内容
最近在研究C++开发安卓端so库,demo使用xamarin.android作为载体来验证算法库文件的准确性.调试过程中发现vector中的内容无法显示集合详细.如下图 研究了半天(参考链接2.3), ...
- 奥特曼框架autMan对接微信公众号的详细教程
1.简介 微信公众号分为订阅号(个人)和服务号(公司),个人是可以申请的哈.具体怎么申请参见官方文档:https://kf.qq.com/faq/120911VrYVrA151009eIrYvy.ht ...