CV中常用Backbone-2:ConvNeXt模型详解及其代码
之前介绍了CV常用Backbon:
CV中常用Backbone-1:Resnet/Unet/Vit系列/多模态系列等)以及代码
这里介绍新的一个Backbone:ConvNeXt,主要来自两篇比较老的来自Meta论文:
1、《A ConvNet for the 2020s》
arXiv:2201.03545
2、《ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders》
arXiv:2301.00808
两篇论文讲的都是一个模型:ConvNeXt。这也是证明一点:Vit效果好并不是attention本身而是因为transform的超大感受野和各种trick。因此作者也是不断借鉴Vit的操作(用斜体表示)
ConvNeXt v1
A ConvNet for the 2020s
⚙-官方代码:https://github.com/facebookresearch/ConvNeXt/blob/main/models/convnext.py
⚙-自己修改:https://www.big-yellow-j.top/code/ConvNeXt.py
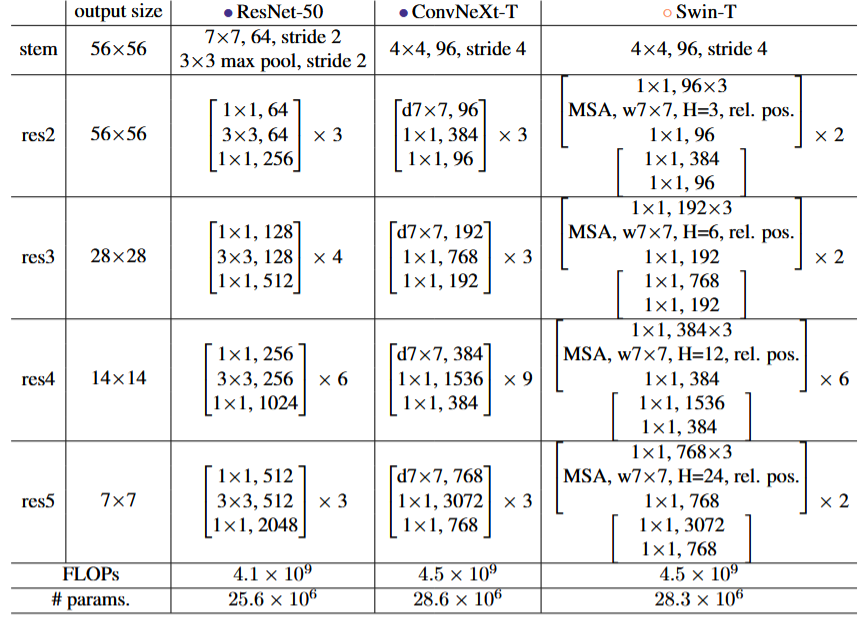
值得注意的一点是在 ConvNeXt 其实就是一个大型的模型调参(不断调节网络参数取得不错效果,于此同时作者对于模型为什么这么做也都是:对比其他模型做法而后而后借鉴到自己做法中),首先作者在论文中做了如下的一些对比(和采用 swin-transformer的resnet进行对比):
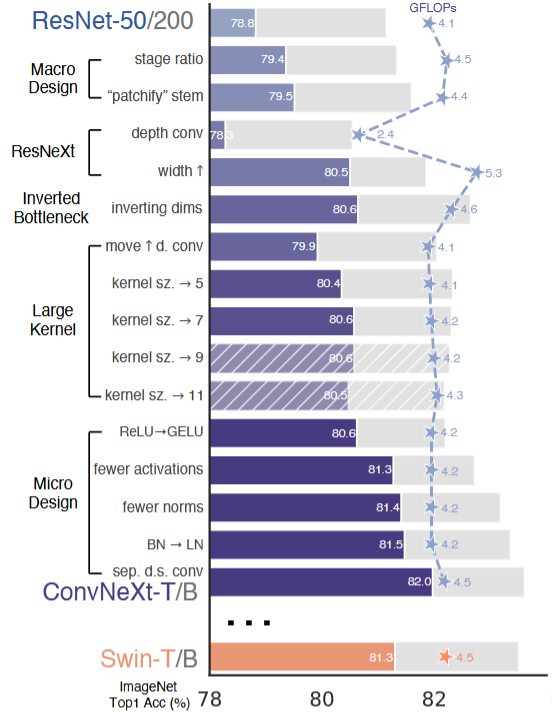
模型在改进上主要是如下几点:1、macro design;2、 ResNeXt;3、inverted bottleneck;4、large kernel size;5、various layer-wise micro designs。
- 1、Macro design
这一点主要是对模型的参数结构做了调整在准确率的提升上起到的效果还是比较有限的
在这里作者主要是做了如下几点修改:1、修改堆叠数量。将ResNet-50中的block堆叠数量从:\((3,4,6,3)\) 改为:\((3,3,9,3)\)。之所以这样设计作者对比 Swin Transformers中主要的比率 为:\((1,1,9,1)\) 通过这样调整对于准确率提升还是比较有限的(78.8%-->79.4%),resnet中堆叠数量
2、修改卷积核。这点没有过多解释直接使用:步长为4,大小也为4的卷积操作(这里是因为:在 Vit网络架构中通常使用一个步长为4,大小也为4的卷积 ),准确率有79.4%-->79.5%
除此之外作者还有一点修改就是将最初的 通道数由64调整成96和Swin Transformer保持一致 ,准确率:80.5%
- 2、Inverted bottleneck
上面第1点是做模型宏观参数(卷积核大小等)做修改,而在这里作者做得主要修改网络结构顺序
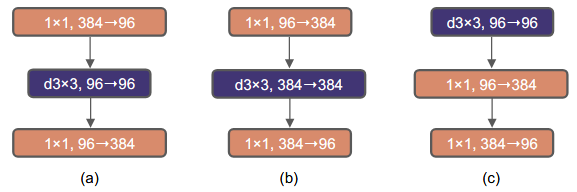
a:resnet;b:MobileNetV2;c:ConvNeXt
这里作者给出的解释是:在Vit中的MLP做的处理和上图中的(b)操作很相像(代码:⚙)
...
self.linear1 = nn.Linear(embed_dim, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, embed_dim)
...
src2 = self.linear2(self.dropout(F.relu(self.linear1(src2))))
因此作者给出的做法是:先降低后提高。在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。
- 3、Large Kernel Sizes
换成更加大的卷积核操作
这里就比较简单直接将最开始的3x3卷积核改为7x7卷积核,它将模型的准确率提升至80.6%
- 4、Micro Design
激活函数替换:将Relu改为GELU(对结果影响不是很大);
减少激活函数:之前网络结构可能对每一个卷积处理之后都会使用一个激活函数处理,这里的话只在 两个 \(1\times1\) 卷积后面添加一个激活函数进行处理;
减少归一化层:因此在ConvNeXt中也使用了更少的归一化操作,它仅在第一个\(1\times1\)卷积之前添加了一个BN
替换归一化层:像之前的描述最开始在卷积网络中都是用BN作为归一化层,这里作者使用LN也取得不错效果;
拆分采样层:在残差网络中,它通常使用的是步长为 2的3x3卷积或者1x1卷积来进行降采样,这使得降采样层和其它层保持了基本相同的计算策略。但是 Swin Transformer将降采样层从其它运算中剥离开来 ,即使用一个步长为2的2x2卷积插入到不同的Stage之间。ConvNeXt也是采用了这个策略,而且在降采样前后各加入了一个LN,而且在全局均值池化之后也加入了一个LN,这些归一化用来保持模型的稳定性。这个策略将模型的准确率提升至82.0%
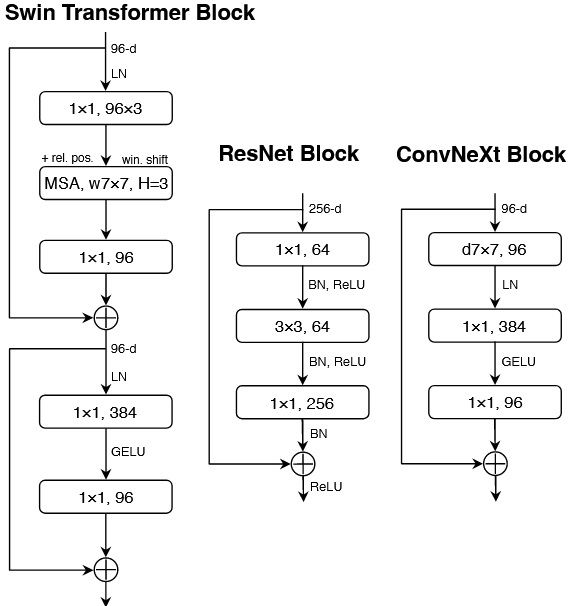
总的来说这篇论文主要还是集中在玄学调参:1、对于ResNet去修改他的堆叠数量(1,1,9,1);2、换更加大的卷积核(4x4,4);3、更加少的激活函数核归一化处理(都只在1x1卷积之后进行操作)。提供如下几种模型

其中C代表4个stage中输入的通道数,B代表每个stage重复堆叠block的次数
ConvNeXt v2
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
这篇文章主要就是两个内容:1、Masked Autoencoder(MAE);2、Global Response Normalization(GRN)。将这两个内容用到 ConvNeXt 中来。依次介绍这两个内容。
- 1、Masked Autoencoder
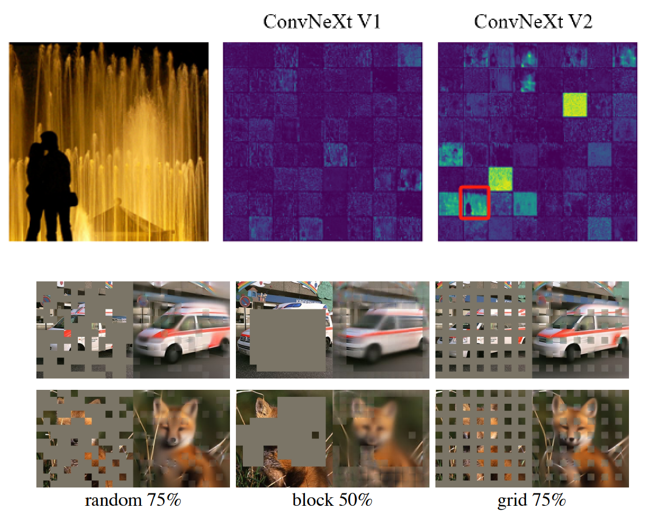
这点其实并不是很新早在 何凯明提出模型(MAE)以及提到过(详细描述:)在本文中也是:原始图片随机移除60%的32x32的patches。不过需要注意一点是:Vit的MAE和FCMAE(全卷积的MAE)有区别的前者是直接通过decoder将图像中被maske进行还原,而后者是“全局还原”,比如下图(上:ConvNeXt,下:Vit MAE):
- 2、Global Response Normalization
理解这个概念是作者在做FCMAE发现一个问题:有许多死亡或饱和的特征图,并且激活在各个通道之间变成了冗余。这种行为主要是在Convnext块中的Dimensive expantasion MLP层中观察到的
there are many dead or saturated feature maps and the activation becomes redundant across channels.This behavior was mainly observed in the dimensionexpansion MLP layers in a ConvNeXt block
还是用上面图像在ConvNeXt v1中很多处理后的图像“失真”(可以理解为decoder构建不出较好的图像全局特征)在使用 GRN时候就可以解决这个问题。计算公式为:

不过值得注意的是其和instance norm区别(虽然都是对channel来计算)用一个例子描述:
假设输入是一个 H×W×C 的特征图(比如 56×56×64):
GRN:计算所有64个通道在 56×56 空间上的全局平方和,作为归一化分母。每个通道的每个像素都被这个全局值标准化,通道间相互影响。
InstanceNorm:对每个通道单独计算 56×56 的均值和方差。每个通道的像素只根据自己的统计量标准化,64个通道互不干扰
总结
提到的论文中可能在学术上可以提供的参考意义不大,毕竟都是拿来主义,先不管他为什么这样只要能够起到好的作用那他就是好的模型(),另外一点值得注意的是在convNeXt论文出发点是:通过实验来证明Vit效果好的原因不是因为attention本身,而是因为transform的超大感受野和各种trick(我在卷积上使用Vit的操作,结果也可以实现这个效果,卷积不输你Vit!)。
CV中常用Backbone-2:ConvNeXt模型详解及其代码的更多相关文章
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- webRTC中语音降噪模块ANS细节详解(四)
上篇(webRTC中语音降噪模块ANS细节详解(三))讲了噪声的初始估计方法以及怎么算先验SNR和后验SNR. 本篇开始讲基于带噪语音和特征的语音和噪声的概率计算方法和噪声估计更新以及基于维纳滤波的降 ...
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- CSS中的ul与li样式详解
CSS中的ul与li样式详解ul和li列表是使用CSS布局页面时常用的元素.在CSS中,有专门控制列表表现的属性,常用的有list-style-type属性.list-style-image属性.li ...
- Nginx 常用全局变量 及Rewrite规则详解
每次都很容易忘记Nginx的变量,下面列出来了一些常用 $remote_addr //获取客户端ip $binary_remote_addr //客户端ip(二进制) $remote_port //客 ...
- 教程-Delphi中Spcomm使用属性及用法详解
Delphi中Spcomm使用属性及用法详解 Delphi是一种具有 功能强大.简便易用和代码执行速度快等优点的可视化快速应用开发工具,它在构架企业信息系统方面发挥着越来越重要的作用,许多程序员愿意选 ...
- mysqldump的常用语句及各参数详解
mysqldump的常用语句及各参数详解 分类: MySQL 2011-01-11 17:55 1368人阅读 评论(0) 收藏 举报 数据库mysql服务器tableinsertdatabase m ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- Android 中各种权限深入体验及详解
Android 中各种权限深入体验及详解 分类: Android2012-07-15 19:27 2822人阅读 评论(0) 收藏 举报 androidpermissionsinstallersyst ...
- java中List的用法和实例详解
java中List的用法和实例详解 List的用法List包括List接口以及List接口的所有实现类.因为List接口实现了Collection接口,所以List接口拥有Collection接口提供 ...
随机推荐
- [阿里DIN] 从论文源码梳理深度学习几个概念
[阿里DIN] 从论文源码梳理深度学习几个概念 目录 [阿里DIN] 从论文源码梳理深度学习几个概念 0x00 摘要 0x01 全连接层 1.1 全连接层作用 1.2 CNN 1.3 RNN 1.4 ...
- VsCode 配置python开发环境
一.配置环境 1.选择python解释器版本 输入:Command+shift+P 搜索:Python: Select Interpreter 2.安装包 指定版本: pip install PyHi ...
- Java连接数据库 CreateStatement 和 PrepareStatement 的区别与优劣
一.简介 先说下CreateStatement 和 PrepareStatement 这俩到底是干啥的吧. 作用:其实这俩干的活儿都一样,就是创建了一个对象然后去通过对象调用executeQuery方 ...
- Atcoder ABC390F Double Sum 3 题解 [ 绿 ] [ 贡献思维 ] [ 计数 ]
Double Sum 3:简单计数题. 思路 首先考虑单个区间的 \(f\) 值如何计算,显然等于值域上连续段的个数.那么我们进一步观察值域上连续段的性质,发现一个连续段的开头一定满足比开头小 \(1 ...
- Luogu P1784 数独 [ 模板 ] / P1074 靶形数独 题解 [ 蓝 ] [ 深搜 ] [ 剪枝 ] [ 卡常 ]
数独模板 , 靶形数独 卡了 2h ,再也不想写数独了. 普通数独 思路 显然是对每个格子进行枚举,类似八皇后的方法去做,朴素方法是由 \((1,1)\) 到 \((9,9)\) 遍历过去. 优化 我 ...
- Tensorflow 安装和测试(Anaconda4.7.10+windows10)
一. 软件下载 二. 配置相关 1. 修改 Jupyter notebook 默认工作路径 (1)打开 Anaconda Prompt ,输入 jupyter notebook --generate- ...
- 川崎机器人维修kasawaki维护注意事项
为确保川崎机械臂的正确安全操作.防止人员伤害和财产损失,请遵守下述方框符号表达的安全信息. --注意事项 在进行Kasawaki川崎机器人维修操作前,请注意如下事项以确保安全. 1. 在开始检查之前, ...
- MySQL Q&A - [01] root密码忘记了怎么办
题记部分 Windows 场景下 1.先使用管理员身份打开两个命令提示符窗口(winA和winB) 2.在命令提示符窗口winA中将MySQL服务停掉net stop mysql Microsoft ...
- antd+vue 中select组件的自定义后缀图标不显示问题记录
根据项目需求,需要使用select组件,并自定义后缀图标,但是设置了没的效果,这是我的代码和效果图 后来查看代码发现需要给select组件加上showArrow属性,然后实现了效果,看效果图 这里记录 ...
- Pydantic字段级校验:解锁@validator的12种应用
title: Pydantic字段级校验:解锁@validator的12种应用 date: 2025/3/23 updated: 2025/3/23 author: cmdragon excerpt: ...