88、使用tensorboard进行可视化学习,查看具体使用时间,训练轮数,使用内存大小
'''
Created on 2017年5月23日 @author: weizhen
'''
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# minist_inference中定义的常量和前向传播的函数不需要改变,
# 因为前向传播已经通过tf.variable_scope实现了计算节点按照网络结构的划分
import mnist_inference
from mnist_train import MOVING_AVERAGE_DECAY, REGULARAZTION_RATE, \
LEARNING_RATE_BASE, BATCH_SIZE, LEARNING_RATE_DECAY, TRAINING_STEPS, MODEL_SAVE_PATH, MODEL_NAME
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
def train(mnist):
# 将处理输入数据集的计算都放在名子为"input"的命名空间下
with tf.name_scope("input"):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-cinput')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False) # 将滑动平均相关的计算都放在名为moving_average的命名空间下
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables()) # 将计算损失函数相关的计算都放在名为loss_function的命名空间下
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses')) # 将定义学习率、优化方法以及每一轮训练需要执行的操作都放在名子为"train_step"的命名空间下
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,
global_step,
mnist.train._num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train') # 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE) if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
writer = tf.summary.FileWriter("/log/modified_mnist_train.log", tf.get_default_graph())
writer.add_run_metadata(run_metadata, "stop%03d" % i)
writer.close()
print("After %d training steps(s),loss on training batch is %g."%(step,loss_value))
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
# 初始化Tensorflow持久化类
# saver = tf.train.Saver()
# with tf.Session() as sess:
# tf.global_variables_initializer().run()
#
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成
# for i in range(TRAINING_STEPS):
# xs, ys = mnist.train.next_batch(BATCH_SIZE)
# _, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x:xs, y_:ys}) # 每1000轮保存一次模型
# if i % 1000 == 0:
# 输出当前训练情况。这里只输出了模型在当前训练batch上的损失函数大小
# 通过损失函数的大小可以大概了解训练的情况。在验证数据集上的正确率信息
# 会有一个单独的程序来生成
# print("After %d training step(s),loss on training batch is %g" % (step, loss_value)) # 保存当前的模型。注意这里给出了global_step参数,这样可以让每个被保存模型的文件末尾加上训练的轮数
# 比如"model.ckpt-1000"表示训练1000轮之后得到的模型
# saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) # 将当前的计算图输出到TensorBoard日志文件
# writer=tf.summary.FileWriter("/path/to/log",tf.get_default_graph())
# writer.close() def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data", one_hot=True)
train(mnist) if __name__ == '__main__':
tf.app.run()
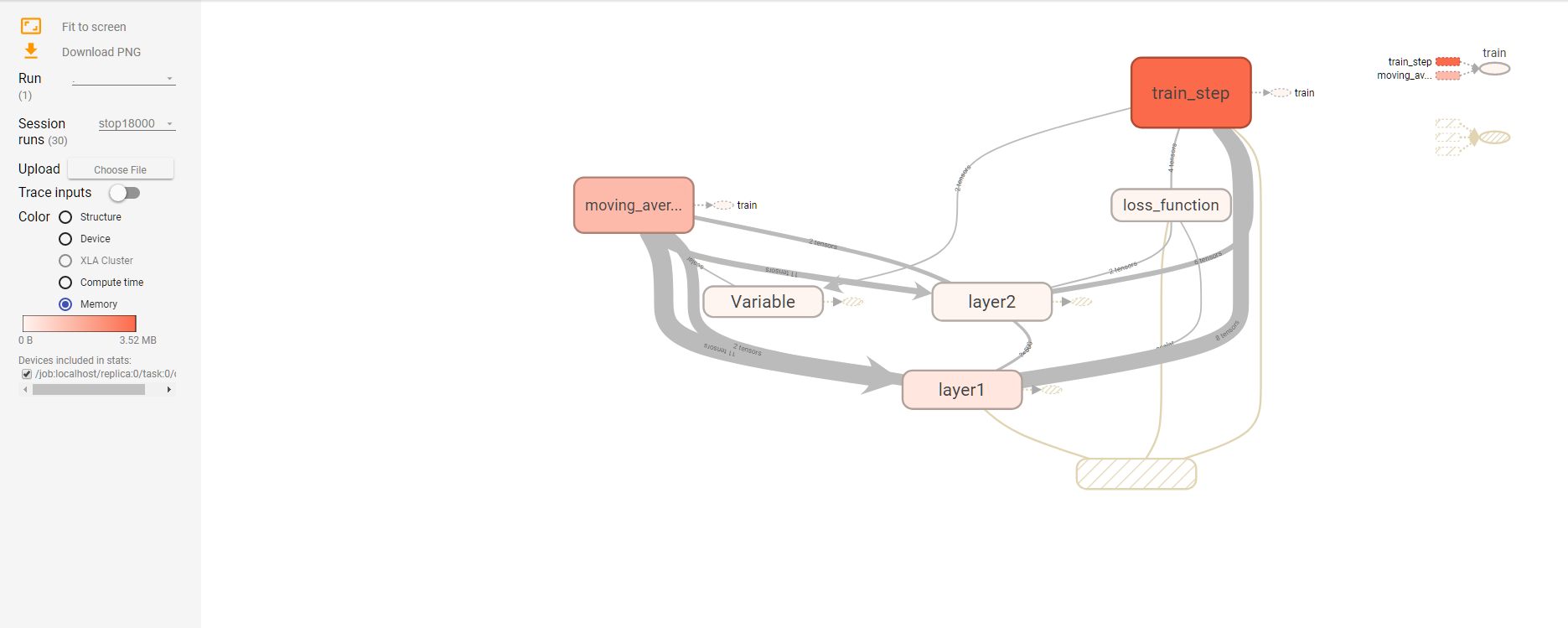
88、使用tensorboard进行可视化学习,查看具体使用时间,训练轮数,使用内存大小的更多相关文章
- 87、使用TensorBoard进行可视化学习
1.还是以手写识别为类,至于为什么一直用手写识别这个例子,原因很简单,因为书上只给出了这个类子呀,哈哈哈,好神奇 下面是可视化学习的标准函数 ''' Created on 2017年5月23日 @au ...
- linux学习--查看操作系统版本及cpu及内存信息
查看版本当前操作系统内核信息 uname -a 查看当前操作系统版本信息 cat /proc/version 查看物理cpu个数: cat /proc/cpuinfo| grep "phy ...
- 可视化学习Tensorboard
可视化学习Tensorboard TensorBoard 涉及到的运算,通常是在训练庞大的深度神经网络中出现的复杂而又难以理解的运算.为了更方便 TensorFlow 程序的理解.调试与优化,发布了一 ...
- TensorBoard:可视化学习
数据序列化 TensorBoard 通过读取 TensorFlow 的事件文件来运行.TensorFlow 的事件文件包括了你会在 TensorFlow 运行中涉及到的主要数据.下面是 TensorB ...
- Tensorflow学习笔记3:TensorBoard可视化学习
TensorBoard简介 Tensorflow发布包中提供了TensorBoard,用于展示Tensorflow任务在计算过程中的Graph.定量指标图以及附加数据.大致的效果如下所示, Tenso ...
- Pytorch在colab和kaggle中使用TensorBoard/TensorboardX可视化
在colab和kaggle内核的Jupyter notebook中如何可视化深度学习模型的参数对于我们分析模型具有很大的意义,相比tensorflow, pytorch缺乏一些的可视化生态包,但是幸好 ...
- 使用 TensorBoard 可视化模型、数据和训练
使用 TensorBoard 可视化模型.数据和训练 在 60 Minutes Blitz 中,我们展示了如何加载数据,并把数据送到我们继承 nn.Module 类的模型,在训练数据上训练模型,并在测 ...
- R语言可视化学习笔记之添加p-value和显著性标记
R语言可视化学习笔记之添加p-value和显著性标记 http://www.jianshu.com/p/b7274afff14f?from=timeline 上篇文章中提了一下如何通过ggpubr ...
- Tensorflow搭建神经网络及使用Tensorboard进行可视化
创建神经网络模型 1.构建神经网络结构,并进行模型训练 import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt ...
随机推荐
- MySQL的limit分页性能测试加优化
日常我们分页时会用到MySQL的limit字段去处理,那么使用limit时,有什么需要优化的地方吗?我们来做一个试验来看看limit的效率问题:环境:CentOS 6 & MySQL 5.71 ...
- git配置密钥(私钥、ssh、公钥)
参照: https://blog.csdn.net/weixin_42063071/article/details/80999690 经常帮人配置git的私钥,来总结一下简单的流程真心希望对大家有所帮 ...
- jenkins配置到gitlab拉代码
参照: jenkins 从git拉取代码-简明扼要 https://www.cnblogs.com/jwentest/p/7065783.html 持续集成①安装部署jenkins从git获取代码-超 ...
- OSX 创建 randisk(或称 tmpfs)
创建步骤: #!/bin/bash ramdisk_size_in_mb= mount_point=/private/tmp ramdisk_size_in_sectors=$((${ramdisk_ ...
- Java数据访问对象模式
数据访问对象模式或DAO模式用于将低级数据访问API或操作与高级业务服务分离. 以下是数据访问对象模式的参与者. 数据访问对象接口 - 此接口定义要对模型对象执行的标准操作. 数据访问对象具体类 - ...
- Java并发AtomicLongArray类
java.util.concurrent.atomic.AtomicLongArray类提供了可以原子读取和写入的底层long类型数组的操作,并且还包含高级原子操作. AtomicLongArray支 ...
- 第6章 RPC之道
6.1 认识RPC 分布式.微服务的架构思维中都不能缺少 RPC 的影子 RPC(Remote Procedure Call)远程过程调用.通过网络在跨进程的两台服务器之间传输信息,我们使用的时候不用 ...
- vue证明题四,使用组件
vue的开发方式,基本上是以组件为主的,至于为啥,我也不好去论述,网上看别人的 所谓渐进式开发,也是源自于单页面应用这一说,而注册一个域名以后,指定了首页,爬虫爬取链接都是从首页开始的 如果一个网址, ...
- mongedb主从
1.mongodb安装 1.将mongodb上传到linux系统 1.解压 tar -zxvf mongodb-linux-x86_64- -C /usr/local/ 这里默认安装到usr/loca ...
- Codeforces 360E 贪心 最短路
题意及思路:https://blog.csdn.net/huanghongxun/article/details/49846927 在假设所有边都是最大值的情况下,如果第一个人能比第二个人先到,那就缩 ...