Hadoop实战内容摘记
Hadoop 开源分布式计算平台,前身是:Apache Nutch(爬虫),Lucene(中文搜索引擎)子项目之一。
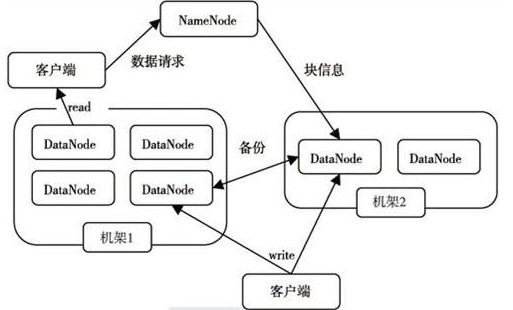
以Hadoop分布式计算文件系统(Hadoop Distributed File System HDFS)和MapReduce(Google MapReduce的开源实现)为核心 的Hadoop基础架构。
HDFS的高容错性、搞伸缩性等优点可以将Hadoop部署在廉价版的硬件上,形成分布式系统;
MapReduce分布式编程模型,利用这种模型软件开发者可以轻松地编写出分布式并行程序。
优势:
1、高可靠性:按位储存和处理数据的能力指的信赖。
2、高扩展性:在可用的计算机集簇间分配数据完成计算任务,这些集簇可以扩展到数以千计的节点中。
3、高效性:能够在节点之间动态的移动数据,已保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性:Hadoop能够自动保存数据的多分副本,并且能够自动将失败的任务重新分配。
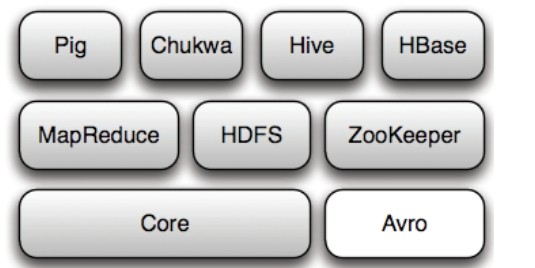
Hadoop项目极其结构
hadoop核心是MapReduce(编程模型)和HDFS(计算系统)

Hadoop实战内容摘记的更多相关文章
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下: Ubuntu:12.04 LTS Master: 1.5G RAM,奔腾 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- 【VS开发】【智能语音处理】MATLAB 与 音频处理 相关内容摘记
MATLAB 与 音频处理 相关内容摘记 MATLAB 与 音频处理 相关内容摘记 1 MATLAB 音频相关函数 1 MATLAB 处理音频信号的流程 2 音量标准化 2 声道分离合并与组合 3 数 ...
随机推荐
- js工厂函数创建对象与对象构造函数的理解
工厂函数,顾名思义,就是通过一个"工厂的加工" 来创建一个对象的函数 //工厂函数 function createPerson(name,sex){ sex = sex == '男' ? '女' : ...
- Tomcat编译jsp生成Servlet文件的存放位置
转自:http://www.cnblogs.com/Leon5/archive/2010/12/07/1899300.html Tomcat将jsp编译成servlet后的文件存放在\work\Cat ...
- 图像描点标注-labelme的安装及使用
1.直接使用pip安装lebelme pip install labelme 2.labelme的使用 找到labelme的安装路径,先找到python的安装路径如我的,C:\Users\Think\ ...
- grandson定理
用处:求解同余线性方程组 inv:逆元 一堆物品 3个3个分剩2个 5个5个分剩3个 7个7个分剩2个 问这个物品有多少个 5*7*inv(5*7, 3) % 3 = 1 3*7*inv(3*7 ...
- java File获取字节流
/*文件64位编码*/ public static void main(String[] args) { byte[] fileByte = toByteArray(newFile); String ...
- 大数据学习笔记之初识Hadoop
1.Hadoop概述 1.1 Hadoop名字的由来 Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名 Hadoop的官网:http://hadoop.apache.org . 1.2 ...
- celery在项目中的使用
1 关于celery是一个处理异步耗时任务的框架 由 worker 和broker 和store 3部分组成 worker是来处理消息的工人 broker是来存储请求消息的仓库 store是用来存储结 ...
- PHP入门培训教程 PHP 数据类型
PHP 支持八种原始类型(type),下面兄弟连PHP培训 小编来给大家列出:. 四种标量类型: string(字符串) integer(整型) float(浮点型,也作 double ) boole ...
- php array_push()函数 语法
php array_push()函数 语法 作用:向第一个参数的数组尾部添加一个或多个元素(入栈),然后返回新数组的长度.博智达 语法:array_push(array,value1,value2.. ...
- Apache主要配置文件http.conf
1.基本概念 Define SRVROOT "/Apache24" ServerRoot "${SRVROOT}" #Apache安装的根路径 #Listen ...