Hadoop实战内容摘记
Hadoop 开源分布式计算平台,前身是:Apache Nutch(爬虫),Lucene(中文搜索引擎)子项目之一。
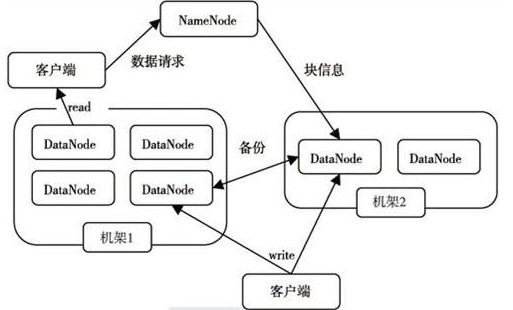
以Hadoop分布式计算文件系统(Hadoop Distributed File System HDFS)和MapReduce(Google MapReduce的开源实现)为核心 的Hadoop基础架构。
HDFS的高容错性、搞伸缩性等优点可以将Hadoop部署在廉价版的硬件上,形成分布式系统;
MapReduce分布式编程模型,利用这种模型软件开发者可以轻松地编写出分布式并行程序。
优势:
1、高可靠性:按位储存和处理数据的能力指的信赖。
2、高扩展性:在可用的计算机集簇间分配数据完成计算任务,这些集簇可以扩展到数以千计的节点中。
3、高效性:能够在节点之间动态的移动数据,已保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性:Hadoop能够自动保存数据的多分副本,并且能够自动将失败的任务重新分配。
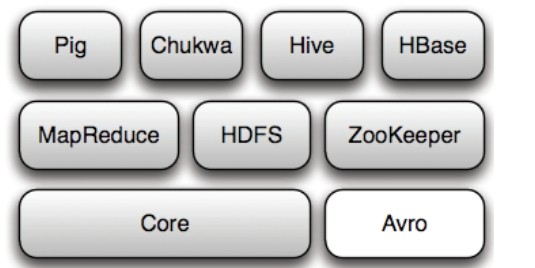
Hadoop项目极其结构
hadoop核心是MapReduce(编程模型)和HDFS(计算系统)

Hadoop实战内容摘记的更多相关文章
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下: Ubuntu:12.04 LTS Master: 1.5G RAM,奔腾 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- 【VS开发】【智能语音处理】MATLAB 与 音频处理 相关内容摘记
MATLAB 与 音频处理 相关内容摘记 MATLAB 与 音频处理 相关内容摘记 1 MATLAB 音频相关函数 1 MATLAB 处理音频信号的流程 2 音量标准化 2 声道分离合并与组合 3 数 ...
随机推荐
- 毛玻璃效果 css
毛玻璃效果 <style> .container{ width: 287px; height: 285px; background-image: url(img/background.pn ...
- Hive内部表,外部表和分区表
外部表和内部表的区别 内部表也称之为managed_table: 默认存储在/user/hive/warehouse下,也可以通过location指定: 删除表事,会删除表数据以及元数据: 外部表称之 ...
- Cockpit- Linux 服务器管理接口
Cockpit- Linux 服务器管理接口 功能 它包含 systemd 服务管理器. 有一个用于故障排除和日志分析的 Journal 日志查看器. 包括 LVM 在内的存储配置比以前任何时候都要简 ...
- 已知链表头结点指针head,写一个函数把这个链表逆序
Node* ReverseList ( Node *head ) { if ( head == NULL || head->next == NULL ) return head; Node *p ...
- Matlab 2019a 下载和安装步骤
目录 1. 安装包下载 + 多套数学建模视频教程 2. 安装步骤 1. 安装包下载 + 多套数学建模视频教程 参考:https://blog.csdn.net/COCO56/article/detai ...
- LOAD - 装载或重载一个共享库文件
SYNOPSIS LOAD 'filename' DESCRIPTION 描述 这个命令装载一个共享库文件到PostgreSQL服务器的地址空间. 一旦一个文件被装载,如果该文件前面曾经装载过,那么服 ...
- Codeforces Round #426 (Div. 2) - B
题目链接:http://codeforces.com/contest/834/problem/B 题意:一共有26个门(A-Z表示),然后现在有n个人要走的门和k个守卫.每当有人要经过某个门时,门要一 ...
- CSS3边框 阴影 box-shadow
box-shadow是向盒子添加阴影.支持添加一个或者多个. box-shadow: X轴偏移量 Y轴偏移量 [阴影模糊半径] [阴影扩展半径] [阴影颜色] [投影方式]; 参数介绍: box-sh ...
- Zookeeper学习笔记(下)
这是ZK学习笔记的下篇, 主要希望可以分享一些 ZK 的应用以及其应用原理 我本人的学习告一段落, 不过还遗留了一些ZK相关的任务开发和性能测试的任务, 留待以后完成之后再通过其他文章来进行分享了 Z ...
- python如何导入自定义文件和模块$PYTHONHOME$\Lib\site-packages 方法
python 中如何引用自己创建的源文件(*.py)呢? 也就是所谓的模块. 假如,你有一个自定义的源文件,文件名:saySomething.py .里面有个函数,函数名:sayHello.如下图: ...