08: mysql主从原理
1.1 mysql主从同步
参考博客:https://www.cnblogs.com/kevingrace/p/6256603.html
1、mysql主从同步(复制)概念
1. 将Mysql某一台主机数据复制到其它主机(slaves)上,并重新执行一遍来实现的。
2. 复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。
3. 主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。
4. 当一个从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。
5. 从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
binlog:是二进制日志文件,用于记录mysql的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据)
2、Mysql支持哪些复制
1. 基于语句的复制: 在主服务器执行SQL语句,在从服务器执行同样语句。
注:MySQL默认采用基于语句的复制,效率较高。一旦发现没法精确复制时, 会自动选基于行的复制。
2. 基于行的复制: 把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
3. 混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
3、Mysql主从复制原理
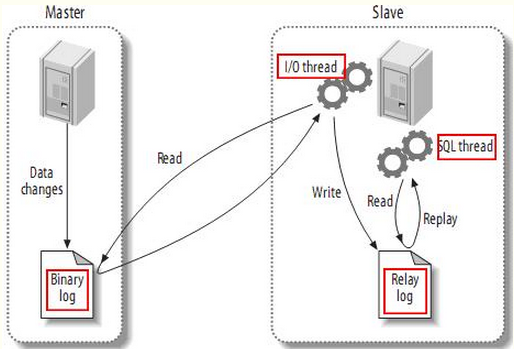
1. master服务器将数据的改变都记录到二进制binlog日志中,只要master上的数据发生改变,则将其改变写入二进制日志;
2. salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件
3. 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中
4. 从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致
5. 最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒。
需要理解:
1)从库会生成两个线程,一个I/O线程,一个SQL线程;
2)I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
3)主库会生成一个log dump线程,用来给从库I/O线程传binlog;
4)SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
4、Mysql复制流程图
1. master将操作语句记录到binlog日志中
2. salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变
3. salave开启两个线程:IO线程和SQL线程
1)IO线程:负责读取master的binlog内容到中继日志relay log里;
2)SQL线程:负责从relay log日志里读出binlog内容,并更新到slave的数据库里(保证数据一致)
1.2 MySQL同步延迟问题
1、造成mysql同步延迟常见原因
1)网络:如主机或者从机的带宽打满、主从之间网络延迟很大,导致主上的binlog没有全量传输到从机,造成延迟。
2)机器性能:从机使用了烂机器?比如主机使用SSD而从机还是使用的SATA。
3)从机高负载:有很多业务会在从机上做统计,把从机服务器搞成高负载,从而造成从机延迟很大的情况
4)大事务:比如在RBR模式下,执行带有大量的delete操作,这种通过查看processlist相关信息以及使用mysqlbinlog查看binlog中的SQL就能快速进行确认
5)锁: 锁冲突问题也可能导致从机的SQL线程执行慢,比如从机上有一些select .... for update的SQL,或者使用了MyISAM引擎等。
2、硬件方面(优化)
1.采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
2.存储用ssd或者盘阵或者san,提升随机写的性能。
3.主从间保证处在同一个交换机下面,并且是万兆环境。
总结:硬件强劲,延迟自然会变小。一句话,缩小延迟的解决方案就是花钱和花时间。
3、mysql主从同步加速
1)sync_binlog在slave端设置为0
当事务提交后,Mysql仅仅是将binlog_cache中的数据写入Binlog文件,但不执行fsync之类的磁盘 同步指令通知文件系统将缓存刷新到磁盘
而让Filesystem自行决定什么时候来做同步,这个是性能最好的。
2)slave端 innodb_flush_log_at_trx_commit = 2
每次事务提交时MySQL都会把log buffer的数据写入log file,但是flush(刷到磁盘)操作并不会同时进行。
该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
3)–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
4)直接禁用slave端的binlog
1111111111111
08: mysql主从原理的更多相关文章
- Mysql主从原理
MySQL的Replication(英文为复制)是一个多MySQL数据库做主从同步的方案,特点是异步复制,广泛用在各种对mysql有更高性能.更高可靠性要求的场合.与之对应的是另一个同步技术是MySQ ...
- mysql主从原理及配置
一.mysql集群架构: 1.一主一从 2.双主 3.一主多从(扩展mysql的读性能) 4.多主一从(5.7开始支持) 5.联机复制 关系图: 二.配置主从用途及条件 2.1用途 1.保障可用性,故 ...
- centos MySQL主从配置 ntsysv chkconfig setup命令 配置MySQL 主从 子shell MySQL备份 kill命令 pid文件 discuz!论坛数据库读写分离 双主搭建 mysql.history 第二十九节课
centos MySQL主从配置 ntsysv chkconfig setup命令 配置MySQL 主从 子shell MySQL备份 kill命令 pid文件 discuz!论坛数 ...
- 部署和调优 2.7 mysql主从配置-1
MySQL 主从(MySQL Replication),主要用于 MySQL 的时时备份或者读写分离.在配置之前先做一下准备工作,配置两台 mysql 服务器,如果你的机器不能同时跑两台 Linux虚 ...
- MySQL主从配置详解
一.mysql主从原理 1. 基本介绍 MySQL 内建的复制功能是构建大型,高性能应用程序的基础.将 MySQL 的 数亿分布到到多个系统上去,这种分步的机制,是通过将 MySQL 的某一台主机的数 ...
- MySQL 主从复制原理及过程讲解
mysql主从原理描述,摘自老男孩. 下面简 单描述下 MySQL Replication 复制的原理及过程 . 1.在 Slave 服务器上执行 start slave 命令开启主从复制开关,主从复 ...
- MySQL主从同步原理 部署【转】
一.主从的作用:1.可以当做一种备份方式2.用来实现读写分离,缓解一个数据库的压力二.MySQL主从备份原理master 上提供binlog ,slave 通过 I/O线程从 master拿取 bin ...
- 学一点 mysql 双机异地热备份----快速理解mysql主从,主主备份原理及实践
双机热备的概念简单说一下,就是要保持两个数据库的状态 自动同步.对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致. 这样做的好处多. 1. 可以做灾备,其中一个坏了可以切换 ...
- MYSQL 主从服务器配置工作原理
一. 主从配置的原理: Mysql的 Replication 是一个异步的复制过程,从一个 Mysql instace(我们称之为 Master)复制到另一个 Mysql instanc ...
随机推荐
- vue项目中监听sessionStorage值发生变化
首先在main.js中给Vue.protorype注册一个全局方法, 其中,我们约定好了想要监听的sessionStorage的key值为’watchStorage’, 然后创建一个StorageEv ...
- java文件分片上传,断点续传
文件夹数据库处理逻辑 publicclass DbFolder { JSONObject root; public DbFolder() { this.root = new JSONObject(); ...
- Codeforces 950E Data Center Maintenance ( 思维 && 强连通分量缩点 )
题意 : 给出 n 个点,每个点有一个维护时间 a[i].m 个条件,每个条件有2个点(x,y)且 a[x] != a[y].选择最少的 k (最少一个)个点,使其值加1后,m个条件仍成立. 分析 : ...
- Redis、Nginx加入启动命令
1.redis加入系统启动命令 vim /etc/init.d/redis #!/bin/sh #chkconfig: 2345 80 90 # Simple Redis init.d script ...
- NOIP2002-字串变换【双向BFS】
NOIP2002-字串变换 Description 已知有两个字串A,BA,B及一组字串变换的规则(至多66个规则): A_1A1 ->B_1B1 A_2A2 -> B_2B2 规 ...
- Bootstrap Table 的X-editable插件怎么用
在准备使用X-editable来做Bootstrap Table 的行内编辑的时候,根据http://www.cnblogs.com/landea... 的文章,我不能将全部效果重复实现,网上也搜索了 ...
- for aws associate exam
Topics which I read based on the previous forum discussions Amazon DynamoDB January 2016 Day at the ...
- c/c++运算符
1.算术运算符(+ - / * %) 2.移位运算符 移运算符:操作数必须是整形,>>,逻辑左移左边移入的位用0填充,算数左移左边移入的的位用符号位补齐.(无符号数为逻辑左移,对于 ...
- LeetCode_001.两数之和
LeetCode_001 LeetCode-001.两数之和 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标. 你可以假设每种输 ...
- leetcode 134 加油站问题
leetcode 134 解析 在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升. 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 co ...