如何将Numpy加速700倍?用 CuPy 呀
如何将Numpy加速700倍?用 CuPy 呀
作为 Python 语言的一个扩展程序库,Numpy 支持大量的维度数组与矩阵运算,为 Python 社区带来了很多帮助。借助于 Numpy,数据科学家、机器学习实践者和统计学家能够以一种简单高效的方式处理大量的矩阵数据。那么 Numpy 速度还能提升吗?本文介绍了如何利用 CuPy 库来加速 Numpy 运算速度。
选自towardsdatascience,作者:George Seif,机器之心编译,参与:杜伟、张倩。
就其自身来说,Numpy 的速度已经较 Python 有了很大的提升。当你发现 Python 代码运行较慢,尤其出现大量的 for-loops 循环时,通常可以将数据处理移入 Numpy 并实现其向量化最高速度处理。
但有一点,上述 Numpy 加速只是在 CPU 上实现的。由于消费级 CPU 通常只有 8 个核心或更少,所以并行处理数量以及可以实现的加速是有限的。
这就催生了新的加速工具——CuPy 库。
何为 CuPy?

CuPy 是一个借助 CUDA GPU 库在英伟达 GPU 上实现 Numpy 数组的库。基于 Numpy 数组的实现,GPU 自身具有的多个 CUDA 核心可以促成更好的并行加速。
CuPy 接口是 Numpy 的一个镜像,并且在大多情况下,它可以直接替换 Numpy 使用。只要用兼容的 CuPy 代码替换 Numpy 代码,用户就可以实现 GPU 加速。
CuPy 支持 Numpy 的大多数数组运算,包括索引、广播、数组数学以及各种矩阵变换。
如果遇到一些不支持的特殊情况,用户也可以编写自定义 Python 代码,这些代码会利用到 CUDA 和 GPU 加速。整个过程只需要 C++格式的一小段代码,然后 CuPy 就可以自动进行 GPU 转换,这与使用 Cython 非常相似。
在开始使用 CuPy 之前,用户可以通过 pip 安装 CuPy 库:
pip install cupy
使用 CuPy 在 GPU 上运行
为符合相应基准测试,PC 配置如下:
- i7–8700k CPU
- 1080 Ti GPU
- 32 GB of DDR4 3000MHz RAM
- CUDA 9.0
CuPy 安装之后,用户可以像导入 Numpy 一样导入 CuPy:
import numpy as np
import cupy as cp
import time
在接下来的编码中,Numpy 和 CuPy 之间的切换就像用 CuPy 的 cp 替换 Numpy 的 np 一样简单。如下代码为 Numpy 和 CuPy 创建了一个具有 10 亿 1』s 的 3D 数组。为了测量创建数组的速度,用户可以使用 Python 的原生 time 库:
### Numpy and CPU
s = time.time()
*x_cpu = np.ones((1000,1000,1000))*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu = cp.ones((1000,1000,1000))*
e = time.time()
print(e - s)
这很简单!
令人难以置信的是,即使以上只是创建了一个数组,CuPy 的速度依然快得多。Numpy 创建一个具有 10 亿 1』s 的数组用了 1.68 秒,而 CuPy 仅用了 0.16 秒,实现了 10.5 倍的加速。
但 CuPy 能做到的还不止于此。
比如在数组中做一些数学运算。这次将整个数组乘以 5,并再次检查 Numpy 和 CuPy 的速度。
### Numpy and CPU
s = time.time()
*x_cpu *= 5*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5*
e = time.time()
print(e - s)
果不其然,CuPy 再次胜过 Numpy。Numpy 用了 0.507 秒,而 CuPy 仅用了 0.000710 秒,速度整整提升了 714.1 倍。
现在尝试使用更多数组并执行以下三种运算:
- 数组乘以 5
- 数组本身相乘
- 数组添加到其自身
### Numpy and CPU
s = time.time()
*x_cpu *= 5
x_cpu *= x_cpu
x_cpu += x_cpu*
e = time.time()
print(e - s)### CuPy and GPU
s = time.time()
*x_gpu *= 5
x_gpu *= x_gpu
x_gpu += x_gpu*
e = time.time()
print(e - s)
结果显示,Numpy 在 CPU 上执行整个运算过程用了 1.49 秒,而 CuPy 在 GPU 上仅用了 0.0922 秒,速度提升了 16.16 倍。
数组大小(数据点)达到 1000 万,运算速度大幅度提升
使用 CuPy 能够在 GPU 上实现 Numpy 和矩阵运算的多倍加速。值得注意的是,用户所能实现的加速高度依赖于自身正在处理的数组大小。下表显示了不同数组大小(数据点)的加速差异:
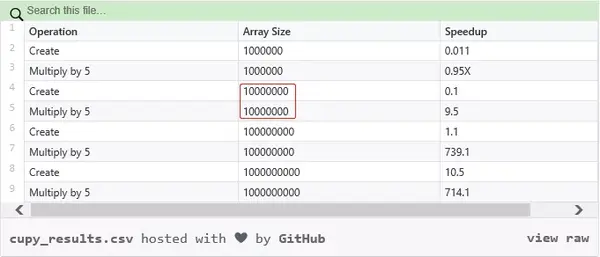
数据点一旦达到 1000 万,速度将会猛然提升;超过 1 亿,速度提升极为明显。Numpy 在数据点低于 1000 万时实际运行更快。此外,GPU 内存越大,处理的数据也就更多。所以用户应当注意,GPU 内存是否足以应对 CuPy 所需要处理的数据。
如何将Numpy加速700倍?用 CuPy 呀的更多相关文章
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- numpy 加速 以及 ipython
先安装openblas, 然后用pip 安装numpy sudo ln -s /usr/lib64/libopenblas-r0.2.14.so /usr/lib64/libopenblas.so 为 ...
- python 多协程异步IO爬取网页加速3倍。
from urllib import request import gevent,time from gevent import monkey#该模块让当前程序所有io操作单独标记,进行异步操作. m ...
- 基于numpy.einsum的张量网络计算
张量与张量网络 张量(Tensor)可以理解为广义的矩阵,其主要特点在于将数字化的矩阵用图形化的方式来表示,这就使得我们可以将一个大型的矩阵运算抽象化成一个具有良好性质的张量图.由一个个张量所共同构成 ...
- 使用numba加速python科学计算
技术背景 python作为一门编程语言,有非常大的生态优势,但是其执行效率一直被人诟病.纯粹的python代码跑起来速度会非常的缓慢,因此很多对性能要求比较高的python库,需要用C++或者Fort ...
- kmplayer加速播放视频(转)
转自微博:http://blog.sina.com.cn/shaguazhu1213 KMPlayer控制播放速度的快捷方式 (2011-11-12 10:51:56) 标签: 杂谈 分类: 编程之旅 ...
- 50倍时空算力提升,阿里云RDS PostgreSQL GPU版本上线
2019年3月19日,阿里云RDS PostgreSQL数据库GPU规格版本正式上线,开启了RDS异构计算并行加速之路.该版本在RDS(关系型数据库服务)的云基础设施层面首次完成了与阿里云异构计算产品 ...
- intel windows caffe加速
网址: https://github.com/BeFreeRoad/intel_caffe_windows 将intel caffe从linux平台移植到windows平台. 性能: 在虚拟机上测试可 ...
- Fluid + GooseFS 助力云原生数据编排与加速快速落地
前言 Fluid 作为基于 Kubernetes 开发的面向云原生存算分离场景下的数据调度和编排加速框架,已于近期完成了 v0.6.0 版本的正式发布.腾讯云容器 TKE 团队一直致力于参与 Flui ...
随机推荐
- Codeforces Round #560 Div. 3
题目链接:戳我 于是...风浔凌弱菜又去写了一场div.3 总的来说,真的是比较简单.......就是.......不开long long见祖宗 贴上题解-- A 给定一个数,为01串,每次可以翻转一 ...
- [LOJ6433][PKUSC2018]最大前缀和:状压DP
分析 我们让每个数列在第一个取到最大前缀和的位置被统计到. 假设一个数列在\(pos\)处第一次取到最大前缀和,分析性质,有: 下标在\([1,pos]\)之间的数形成的数列的每个后缀和(不包括整个数 ...
- 工具类-ApplicationContextUtil
package com.zhouyy.netBank.util; import org.springframework.beans.BeansException; import org.springf ...
- JS框架_(Bootstrap.js)实现简单的轮播图
Bootstrap框架中 轮播(Carousel)插件是一种灵活的响应式的向站点添加滑块的方式 轮播图效果: <!DOCTYPE html> <html> <head&g ...
- Spring boot之使用thymeleaf
操作步骤 (1)在pom.xml中引入thymeleaf; (2)如何关闭thymeleaf缓存 (3)编写模板文件.html (4)编写访问模板文件controller 在pom.xml中引入thy ...
- Ubuntu 16.04配置SSL免费证书
主要参考地址为:https://blog.csdn.net/setoy/article/details/78441613 本篇主要以Apache这个web服务器来讲解,所以前提必须要安装好apache ...
- 使用 vuetron 调试 mpvue 项目
简介 由于小程序开发工具的封闭,我们无法通过安装 chrome 插件来方便地使用 vue-devtools 调试我们的 mpvue 项目.vuetron 是一个 vue.js 的项目调试工具, 同时支 ...
- vue中bus.$on事件被多次绑定
问题描述:只要页面没有强制刷新,存在组件切换,bus.$on方法会被多次绑定,造成事件多次触发 解决办法一:在每次调用方法前先解绑事件( bus.$off ),然后在重新绑定( bus.$on ) b ...
- latexdiff中的大坑:字符编码问题
最近用latex写文章,要用到修订模式,于是采用latexdiff命令生成修订版pdf.这原本是一个非常简单方便的方法,却隐藏着字符编码的问题,初次用可能会遇到意想不到的问题,让人很烦,比如,生成出来 ...
- Sqlserver实现故障转移 — 域控(1)
一 .实现目的:实现两台sqlserver数据库服务器的实时备份及故障转移:即:其中一台数据库服务器宕机后,应用程序可自动连接到另一台数据库服务器继续运行. 二.域控:域控制器是指在“域”模式下,至 ...