Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function
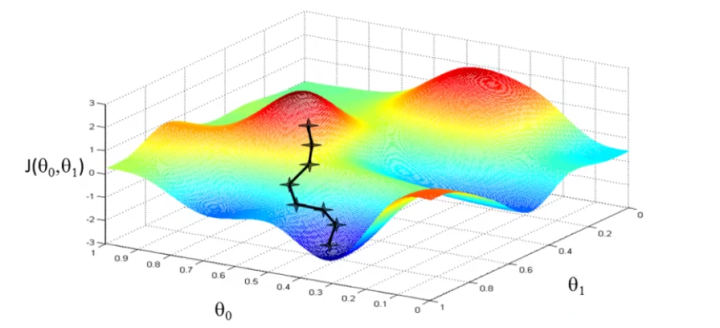
From the initial state, we probably have a really poor system (may be only output zero). By using X and Y to train, we try to derive a better parameter θ. The training process (learning process) may be time-consuming, because the algorithm updates parameters only a little on every training step.
2. Cost Function?
Suppose driving from somewhere to Toronto: it is easy to know the coordinates of Toronto, but it is more important to know where we are now! Cost function is the tool giving us how different between Hypothesis and label Y, so that we can drive to the target. For regression problem, we use MSE as the cost function.
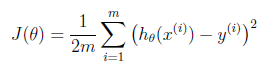
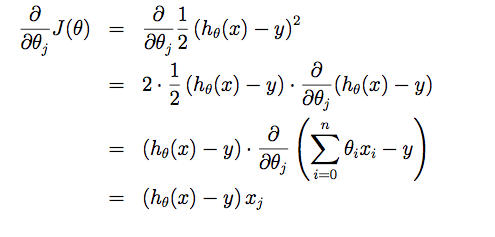

Linear Regression and Gradient Descent (English version)的更多相关文章
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Linear Regression and Gradient Descent
随着所学算法的增多,加之使用次数的增多,不时对之前所学的算法有新的理解.这篇博文是在2018年4月17日再次编辑,将之前的3篇博文合并为一篇. 1.Problem and Loss Function ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- flink 批量梯度下降算法线性回归参数求解(Linear Regression with BGD(batch gradient descent) )
1.线性回归 假设线性函数如下: 假设我们有10个样本x1,y1),(x2,y2).....(x10,y10),求解目标就是根据多个样本求解theta0和theta1的最优值. 什么样的θ最好的呢?最 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
随机推荐
- 在Lua中进行运算符重载
在C++里面运算符是可以重载的,这一点也是C++比较方便的一个地方.在Lua中其实也是可以模拟出运算符的重载的. 在Lua中table中元素的运算都是和一个叫做元表有关的,在一个table型的变量上都 ...
- java_第一年_JavaWeb(5)
HttpServletRequest对象 通过HttpServletRequest对象可获取客户端在访问服务器时,请求的所有信息 获取客户机的信息 getRequestURL:返回客户端发出请求时的完 ...
- python 列表总结大全
1定义 names=[] names=[1,2,1,1,1,] names=[1.'10'.[1,1]] 2添加元素 names.append() names.insert(0,10) names.e ...
- P3826 [NOI2017]蔬菜
传送门 注意每一单位蔬菜的变质时间是固定的,不随销售发生变化 固定的...... 就是每一个单位的蔬菜在哪一天变质是早就定好了的 发现从第一天推到最后一天很不好搞 考虑反过来,从最后一天推到第一天,这 ...
- C#面试 笔试题 五
1.什么是受管制的代码? 答:unsafe:非托管代码.不经过CLR运行. 2.net Remoting 的工作原理是什么? 答:服务器端向客户端发送一个进程编号,一个程序域编号,以确定对象的位置. ...
- 金蝶云k3 cloud采购入库单校验日期不通过
新增采购入库单的时候提示单据日期必须大于等于货主组织在核算系统最后关账日期 解决办法:库存系统和存货核算系统的反关账
- Linux学习笔记2-CentOS7安装tomcat8
1.下载tomcat:apache-tomcat-8.5.16.tar.gz 下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat ...
- 自定义的最简单的可回调的线程任务CallbackableFeatureTask(模仿google的ListenableFutureTask)
1.使该Task继承Callable,Runable import java.util.concurrent.Callable; import java.util.function.Consumer; ...
- sort - 对文本文件的行排序
SYNOPSIS(总览) ../src/sort [OPTION]... [FILE]... DESCRIPTION(描述) ?谡舛砑尤魏胃郊拥拿枋鲂畔? 将排序好的所有文件串写到标准输出上. +P ...
- git 报错
-bash: git: command not found export PATH=$PATH:/usr/local/git/bin 使用git clone出现 fatal: unable to ac ...