Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function
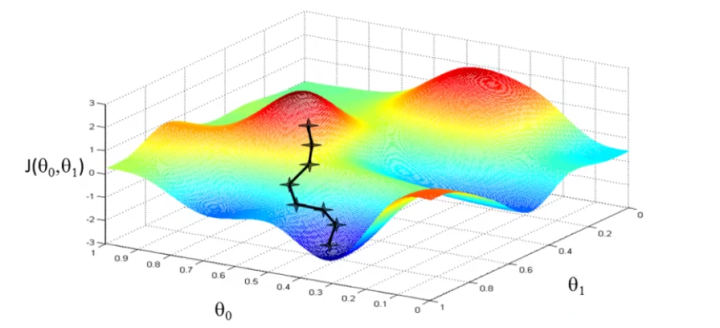
From the initial state, we probably have a really poor system (may be only output zero). By using X and Y to train, we try to derive a better parameter θ. The training process (learning process) may be time-consuming, because the algorithm updates parameters only a little on every training step.
2. Cost Function?
Suppose driving from somewhere to Toronto: it is easy to know the coordinates of Toronto, but it is more important to know where we are now! Cost function is the tool giving us how different between Hypothesis and label Y, so that we can drive to the target. For regression problem, we use MSE as the cost function.
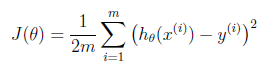
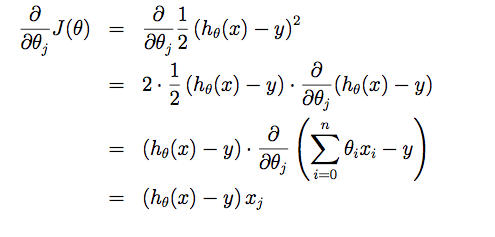

Linear Regression and Gradient Descent (English version)的更多相关文章
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Linear Regression and Gradient Descent
随着所学算法的增多,加之使用次数的增多,不时对之前所学的算法有新的理解.这篇博文是在2018年4月17日再次编辑,将之前的3篇博文合并为一篇. 1.Problem and Loss Function ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- flink 批量梯度下降算法线性回归参数求解(Linear Regression with BGD(batch gradient descent) )
1.线性回归 假设线性函数如下: 假设我们有10个样本x1,y1),(x2,y2).....(x10,y10),求解目标就是根据多个样本求解theta0和theta1的最优值. 什么样的θ最好的呢?最 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
随机推荐
- python的小介绍
Python简介 龟叔 优美.清晰.简单 主要应用领域: 云计算 WEB开发 科学技术.人工智能 系统运维 爬虫 金融量化分析 图形GUI 游戏 Python发展史 1989年,Guido开始写Pyt ...
- Zookeeper——启动闪退
Zookeeper好久不启动了,昨天项目要用Zookeeper了,我昨天突然启动它,调皮的zk居然害羞不让我看见它,启动不了,一启动就闪退,为啥呢?其实是因为报错了,有错zk启动时就会报错,所以昨 ...
- docker镜像源设置
由于docker默认镜像源为国外官方源,下载速度较慢.设置国内镜像源可加速 修改文件 /etc/docker/daemon.json vi /etc/docker/daemon.json 添加以下内容 ...
- MySQL --12 备份的分类
目录 物理备份(Xtrabackup) 1.全量备份 2.增量备份及恢复 3.差异备份及恢复 4.实战:企业级增量恢复实战 物理备份(Xtrabackup) Xtrabackup安装 #下载epel源 ...
- ELKStack之操作深入(中)
ELKStack之操作深入(中) 链接:https://pan.baidu.com/s/1V2aYpB86ZzxL21Hf-AF1rA 提取码:7izv 复制这段内容后打开百度网盘手机App,操作更方 ...
- weblogic下载
1.网址 https://edelivery.oracle.com/osdc/faces/SoftwareDelivery 2.信息
- git兼容svn与hg功能
本地.git库 远程:push 提交以后push才可以到远程库
- 前端学习(三十五)模块化es6(笔记)
RequireJs:一.安装.下载 官网: requirejs.org Npm: npm i requirejs二.使用 以前的开发方式的问题: 1).js 是阻塞加 ...
- MongoDB 存储引擎选择
MongoDB存储引擎选择 MongoDB存储引擎构架 插件式存储引擎, MongoDB 3.0引入了插件式存储引擎API,为第三方的存储引擎厂商加入MongoDB提供了方便,这一变化无疑参考了MyS ...
- python 图像处理中二值化方法归纳总结
python图像处理二值化方法 1. opencv 简单阈值 cv2.threshold 2. opencv 自适应阈值 cv2.adaptiveThreshold 3. Otsu's 二值化 例子: ...