ES之四、Elasticsearch集群和索引常用命令
REST API用途
elasticsearch支持多种通讯,其中包括http请求响应服务,因此通过curl命令,可以发送http请求,并得到json返回内容。
ES提供了很多全面的API,常用的REST请求大致可以分成如下几种:
1 检查集群、节点、索引的健康情况
2 管理集群、节点,索引数据、元数据
3 执行CRUD,创建、读取、更新、删除 以及 查询
4 执行高级的查询操作,比如分页、排序、脚本、聚合等
Query DSL(领域专用语言)
Query DSL 是 elasticsearch 的核心,搜索方面的项目大部分时间都耗费在对查询结果的调优上。因此对 Query DSL 的理解越深入,越能节省项目时间,并给用户好的体验。
这门语言刚开始比较难理解,因此通过几个简单的例子开始:
下面的命令,可以搜索全部的文档:
{
"query": { "match_all": {} }
}
query定义了查询,match_all声明了查询的类型。还有其他的参数可以控制返回的结果:
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} },
"size": 1
}'
上面的命令返回了所有文档数据中的第一条文档。如果size不指定,那么默认返回10条。
概要
Elasticsearch 提供了一个完整的 query DSL,并且是 JSON 形式的。它和 AST 比较类似,并且包含两种类型的语句:
- 叶子查询语句(Leaf Query):用于查询某个特定的字段,如 match , term 或 range 等
- 复合查询语句 (Compound query clauses):用于合并其他的叶查询或复合查询语句,也就是说复合语句之间可以嵌套,用来表示一个复杂的单一查询
DSL (domain-specific language),领域特定语言指的是专注于某个应用程序领域的计算机语言,又译作领域专用语言。不同于普通的跨领域通用计算机语言(GPL),领域特定语言只用在某些特定的领域。
AST(abstract syntax tree), 抽象语法树是源代码的抽象语法结构的树形表现形式。树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于if-condition-then这样的条件跳转语句,可以使用带有两个分支的节点来表示。
Query and filter context
一个查询语句究竟具有什么样的行为和得到什么结果,主要取决于它到底是处于查询上下文(Query Context) 还是过滤上下文(Filter Context)。两者有很大区别,我们来看下:
- Query context 查询上下文:这种语句在执行时既要计算文档是否匹配,还要计算文档相对于其他文档的匹配度有多高,匹配度越高,*_score* 分数就越高
- Filter context 过滤上下文:过滤上下文中的语句在执行时只关心文档是否和查询匹配,不会计算匹配度,也就是不计算得分(不对文档进行评分)。所以过滤器比Query context更简单查询也更快。
过滤器和缓存(Filters and Caching)
过滤器是用来实现缓存的很好的办法. 因为缓存这些过滤结果并不需要太多的内存, 而且其它的查询可以重用这些过滤(注意是同样参数哦),所以速度是刷刷的.
某些过滤产生的结果是很易于缓存的,有关缓存与否的区别在于是否将过滤结果存放到缓存中,像如下过滤器如 term, terms, prefix, 和 range 默认就是会进行缓存的, 并且建议使用这些过滤条件而不使用同等效果的查询.
其它过滤器,一般会将字段数据加载到内存中来工作, 默认是不缓存结果的. 这些过滤操作的速度其实已经非常快了,如果将它们的结果缓存需要做额外的操作来使它们能够被其它查询使用,这些查询,包括地理位置的(geo), numeric_range, 和 script 默认是没有缓存结果的.
最后一个过滤器的类型是过滤器之间的组合, and, not 和 or ,这些过滤器是没有缓存结果的,因为它们主要是操作内联的过滤器,所以不需要过滤.
所有的过滤器都允许设置 _cache 元素来显式的控制缓存与否. 并且允许设置一个 _cache_key 用来当作缓存的主键. 这个在过滤大集合的情况下非常有用 (如包含很多元素的 terms filter).
举个例子说明Query context与filter context的区别:
GET/_search
{
"query": {
"bool": {
"must": [{
"match": {
"title": "Search"
}
},
{
"match": {
"content": "Elasticsearch"
}
}],
"filter": [{
"term": {
"status": "published"
}
},
{
"range": {
"publish_date": {
"gte": "2015-01-01"
}
}
}]
}
}
}
对上面的例子分析下:
1、query 参数表示整个语句是处于 query context 中
2、bool 和 match 语句被用在 query context 中,也就是说它们会计算每个文档的匹配度(_score)
3、filter 参数则表示这个子查询处于 filter context 中
4、filter 语句中的 term 和 range 语句用在 filter context 中,它们只起到过滤的作用,并不会计算文档的得分。
Match All Query
这个查询最简单,所有的 _score 都是 1.0。
GET /_search{"query": {"match_all": {} }}
它的反面就是 Match None Query, 匹配不到任何文档(不知道用它来做什么……)
GET /_search{"query": {"match_none": {} }}
全文查询 Full text queries
全文本查询的使用场合主要是在出现大量文字的场合,例如 email body 或者文章中搜寻出特定的内容。
全文查询主要分为下面几种(此处列表中的链接为官方文档链接,后续将各部分讲解后,会替换为讲解链接):
match query
全文查询中最主要的查询,包括模糊查询(fuzzy matching) 或者临近查询(proximity queries)。
match_phrase query
和 match 查询比较类似,但是它会保留包含所有搜索词项,且位置与搜索词项相同的文档。
match_phrase_prefix query
是一种输入即搜索(search-as-you-type) 的查询,它和 match_phrase 比较类似,区别就是会将查询字符串的最后一个词作为前缀来使用。
multi_match query
多字段版本的 match query
common terms query(常用术语查询)
该common术语查询是一个现代的替代提高了精确度和搜索结果的召回(采取禁用词进去),在不牺牲性能的禁用词。
问题
查询中的每个术语都有成本。搜索"The brown fox" 需要三个术语查询,每个查询一个"the","brown"并且 "fox"所有查询都针对索引中的所有文档执行。查询"the"可能与许多文档匹配,因此对相关性的影响比其他两个术语小得多。
以前,这个问题的解决方案是忽略高频率的术语。通过将其"the"视为停用词,我们减少了索引大小并减少了需要执行的术语查询的数量。
这种方法的问题在于,虽然停用词对相关性的影响很小,但它们仍然很重要。如果我们删除了停用词,我们就会失去精确度(例如,我们无法区分"happy" 和"not happy"),并且我们会失去回忆(例如,文本在索引中"The The"或者 "To be or not to be"根本不存在)。
解决方案
该common术语的查询将所述查询术语分为两组:更重要(即低频率而言)和不太重要的(即,高频率而言这将先前已停用词)。
首先,它搜索与更重要的术语匹配的文档。这些术语出现在较少的文档中,对相关性有较大影响。
然后,它对不太重要的术语执行第二次查询 - 这些术语经常出现并且对相关性的影响很小。但是,它不是计算所有匹配文档的相关性分数,而是仅计算_score已经与第一个查询匹配的文档。通过这种方式,高频项可以改善相关性计算,而无需支付性能不佳的成本。
如果查询仅包含高频术语,则单个查询将作为AND(连接)查询执行,换句话说,所有术语都是必需的。即使每个单独的术语与许多文档匹配,术语组合也会将结果集缩小到最相关的范围。单个查询也可以作为OR特定的 查询执行minimum_should_match,在这种情况下,应该使用足够高的值。
根据条件将术语分配给高频或低频组 cutoff_frequency,可以将其指定为绝对频率(>=1)或相对频率(0.0 .. 1.0)。(请记住,文档频率是按照每个分片级别计算的,如博客文章中所述, 相关性已被破坏。)
也许这个查询最有趣的属性是它自动适应域特定的停用词。例如,在视频托管网站上,常见的术语如"clip"或"video"将自动表现为停用词而无需维护手动列表。
示例说明见:https://blog.csdn.net/ctwy291314/article/details/82836514
query_string query
支持复杂的 Lucene query String 语法,除非你是专家用户,否则不推荐使用。
simple_query_string query
简化版的 query_string ,语法更适合用户操作。
ES请求及返回数据的数据结构
搜索API
ES提供了两种搜索的方式:请求参数方式 和 请求体方式。
请求参数方式
curl 'localhost:9200/bank/_search?q=*&pretty'
其中bank是查询的索引名称,q后面跟着搜索的条件:q=*表示查询所有的内容
请求体方式(推荐这种方式)
curl -XPOST 'localhost:9200/bank/_search?pretty' -d '
{
"query": { "match_all": {} }
}'
这种方式会把查询的内容放入body中,会造成一定的开销,但是易于理解。在平时的练习中,推荐这种方式。
返回:
{
"took" : 26,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1000,
"max_score" : 1.0,
"hits" : [ {
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : 1.0, "_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, {
"_index" : "bank",
"_type" : "account",
"_id" : "6",
"_score" : 1.0, "_source" : {"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
},....
返回的内容大致可以如下讲解:
- took:是查询花费的时间,毫秒单位
- time_out:标识查询是否超时
- _shards:描述了查询分片的信息,查询了多少个分片、成功的分片数量、失败的分片数量等
- hits:搜索的结果,total是全部的满足的文档数目,hits是返回的实际数目(默认是10)
- _score是文档的分数信息,与排名相关度有关,参考各大搜索引擎的搜索结果,就容易理解。
由于ES是一次性返回所有的数据,因此理解返回的内容是很必要的。它不像传统的SQL是先返回数据的一个子集,再通过数据库端的游标不断的返回数据(由于对传统的数据库理解的不深,这里有错还望指正)。
ES中的查询帮助命令
Elasticsearch中信息很多,如果单凭肉眼来寻找复杂数据之间的关系,是很困难的。因此cat命令应运而生,它帮助开发者快速查询Elasticsearch的相关信息。
_cat命令
通过使用_cat可以查看支持的命令:
$ curl localhost:9200/_cat(GET /_cat?pretty)
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
pretty
在任意的查询字符串中增加pretty参数,会让Elasticsearch美化输出(pretty-print)JSON响应以便更加容易阅读。
_source字段不会被美化,它的样子与我们输入的一致。
verbose
每个命令都支持使用?v参数,来显示详细的信息:
$ curl localhost:9200/_cat/master?v
id host ip node
QG6QrX32QSi8C3-xQmrSoA 127.0.0.1 127.0.0.1 Manslaughter
help
每个命令都支持使用help参数,来输出可以显示的列:
$ curl localhost:9200/_cat/master?help
id | | node id
host | h | host name
ip | | ip address
node | n | node name
headers
通过h参数,可以指定输出的字段:
$ curl localhost:9200/_cat/master?v
id host ip node
QG6QrX32QSi8C3-xQmrSoA 127.0.0.1 127.0.0.1 Manslaughter
$ curl localhost:9200/_cat/master?h=host,ip,node
127.0.0.1 127.0.0.1 Manslaughter
数字类型的格式化
很多的命令都支持返回可读性的大小数字,比如使用mb或者kb来表示。
$ curl localhost:9200/_cat/indices?v
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open test 5 1 3 0 9.2kb 9.2kb常见命令示例
1、查看集群状态
可以通过CURL命令发送REST命令,查询集群的健康状态:
curl 'localhost:9200/_cat/health?v'
Localhost是主机的地址,9200是监听的端口号,ES默认监听的端口号就是9200.
这里需要注意的是,windows下安装的CURL有可能不支持单引号,如果有报错,还请改成双引号,内部使用转义字符转义。
得到的相应结果。

结果说明:
可以看到集群的名字是默认的"elasticsearch",集群的状态时"green"。这个颜色之前也有说过:
1 绿色,最健康的状态,代表所有的分片包括备份都可用
2 黄色,基本的分片可用,但是备份不可用(也可能是没有备份)
3 红色,部分的分片可用,表明分片有一部分损坏。此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好。
上面的结果还可以看到,目前有一个节点,但是没有分片,这是因为我们的ES中还没有数据,一次也就没有分片。
当使用elasticsearch作为集群名字时,会使用单播,查询本机上是否还运行着其他的节点。如果有,则组成一个集群。
(如果使用其他的名字作为集群名字,那么就可能采用多播了!这个在工作中,经常会遇到,大家使用的是一个集群名字,分片总是被搞在一起,导致有人的机器下线后,自己的也无法使用)
查看节点信息
通过下面的命令,可以查询节点的列表:
curl 'localhost:9200/_cat/nodes?v'

ElasticSearch查看节点信息命令:
- 主节点:
curl 'localhost:9200/_cat/master?v' - 所有节点:
curl 'localhost:9200/_cat/nodes?v'
2、查看所有的索引
在ES中索引有两个意思:
1 动词的索引,表示把数据存储到ES中,提供搜索的过程;这期间可能正在执行一个创建搜索的过程。
2 名字的索引,它是ES中的一个存储类型,与数据库类似,内部包含type字段,type中包含各种文档。
通过下面的命令可以查看所有的索引:(indices:英 [ˈɪndɪsiːz] index 的复数形式之一)
curl 'localhost:9200/_cat/indices?v'
得到的结果如下:

由于集群中没有任何的数据,上面的结果中也就只包含列的信息了。
pri.store.size为primary store size,即主分片的数据大小;
pri为分片个数,rep为副本个数。
查看索引分片情况
ElasticSearch查看索引分片情况命令:
curl 'localhost:9200/_cat/shards?v'

可以看到例子中有两个索引分别是:people和product,他们各有一个主分片和一个尚未分配的副分片。
2、创建索引
创建索引
curl -XPUT localhost:9200/索引名/类型/id -d {//JSON格式的body体}
查询索引
curl -XGET localhost:9200/索引名/类型/id
下面是创建索引,以及查询索引的例子:
curl -XPUT 'localhost:9200/testindex/orders/2?pretty' -d '{
"zone_id": "1",
"user_id": "100008",
"try_deliver_times": 102,
"trade_status": "TRADE_FINISHED",
"trade_no": "xiaomi.21142736250938334726",
"trade_currency": "CNY",
"total_fee": 100,
"status": "paid",
"sdk_user_id": "69272363",
"sdk": "xiaomi",
"price": 1,
"platform": "android",
"paid_channel": "unknown",
"paid_at": 1427370289,
"market": "unknown",
"location": "local",
"last_try_deliver_at": 1427856948,
"is_guest": 0,
"id": "fa6044d2fddb15681ea2637335f3ae6b7f8e76fef53bd805108a032cb3eb54cd",
"goods_name": "一小堆元宝",
"goods_id": "ID_001",
"goods_count": "1",
"expires_in": 2592000,
"delivered_at": 0,
"debug_mode": true,
"created_at": 1427362509,
"cp_result": "exception encountered",
"cp_order_id": "cp.order.id.test",
"client_id": "9c98152c6b42c7cb3f41b53f18a0d868",
"app_user_id": "fvu100006"
}'
看结果:
[sfapp@cmos1 ekfile]$ curl -XGET 'localhost:9200/testindex/orders/2?pretty'
{
"_index" : "testindex",
"_type" : "orders",
"_id" : "2",
"_version" : 1,
"found" : true,
"_source" : {
"zone_id" : "1",
"user_id" : "100008",
"try_deliver_times" : 102,
"trade_status" : "TRADE_FINISHED",
"trade_no" : "xiaomi.21142736250938334726",
"trade_currency" : "CNY",
"total_fee" : 100,
"status" : "paid",
"sdk_user_id" : "69272363",
"sdk" : "xiaomi",
"price" : 1,
"platform" : "android",
"paid_channel" : "unknown",
"paid_at" : 1427370289,
"market" : "unknown",
"location" : "local",
"last_try_deliver_at" : 1427856948,
"is_guest" : 0,
"id" : "fa6044d2fddb15681ea2637335f3ae6b7f8e76fef53bd805108a032cb3eb54cd",
"goods_name" : "一小堆元宝",
"goods_id" : "ID_001",
"goods_count" : "1",
"expires_in" : 2592000,
"delivered_at" : 0,
"debug_mode" : true,
"created_at" : 1427362509,
"cp_result" : "exception encountered",
"cp_order_id" : "cp.order.id.test",
"client_id" : "9c98152c6b42c7cb3f41b53f18a0d868",
"app_user_id" : "fvu100006"
}
}
[sfapp@cmos1 ekfile]$
上面的结果中,customer索引的状态是yellow,这是因为此时虽然有5个主分片和一个备份。但是由于只是单个节点,我们的分片还在运行中,无法动态的修改。因此当有其他的节点加入到集群中,备份的节点会被拷贝到另一个节点中,状态就会变成green。
3、索引和搜索文档
之前说过,索引里面还有类型的概念,在索引文档之前要先设置类型type。
执行的命令如下:
curl -XPUT 'localhost:9200/customer/external/1?pretty' -d '
{
"name": "John Doe"
}'
执行成功后会得到如下的信息:
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"created" : true
}
注意2.0版本的ES在同一索引下,不同的类型,相同的字段名字,是不允许字段类型不一致的。
上面的例子中,为我们创建了一个文档,并且id自动设置为1.
ES不需要再索引文档前,不需要明确的创建索引,如果执行上面的命令,索引不存在,也会自动的创建索引。
执行下面的命令查询,返回信息也如下:
[sfapp@cmos1 ~]$ curl -XGET 'localhost:9200/customer/external/1?pretty'
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name" : "John Doe"
}
}
[sfapp@cmos1 ~]$
这里会新增两个字段:
1 found 描述了请求信息
2 _source 为之前索引时的数据
4、删除索引
语法:
curl -XDELETE localhost:9200/索引名
执行下面的命令就可以删除索引:
curl -XDELETE 'localhost:9200/customer?pretty'
返回结果:
{
"acknowledged": true
}
总结
总结上面涉及到的命令大致如下:
curl -XPUT 'localhost:9200/customer'//创建索引
//插入数据
curl -XPUT 'localhost:9200/customer/external/1'-d '
{
"name": "John Doe"
}'
curl 'localhost:9200/customer/external/1'//查询数据
curl -XDELETE 'localhost:9200/customer'//删除索引
5、ES 使用bulk 添加数据(批量增加)(bulk [bʌlk] n.主体;大部分;(大)体积;大(量);巨大的体重(或重量、形状、身体等))
使用bulk命令,添加json文件中的数据。Bulk顾名思义,把多个单条的记录合并成一个大数组统一提交,这样避免一条条发送的header解析,索引频繁更新,indexing速度大大提高
1.新建json文件accounts.json,定义json数据格式,其中每个数据格式都是如下:

{
"index":{"_id":"1"}
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}
2.执行命令,批量添加:
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary "@accounts.json"
3.查询索引
curl 'localhost:9200/_cat/indices?v'
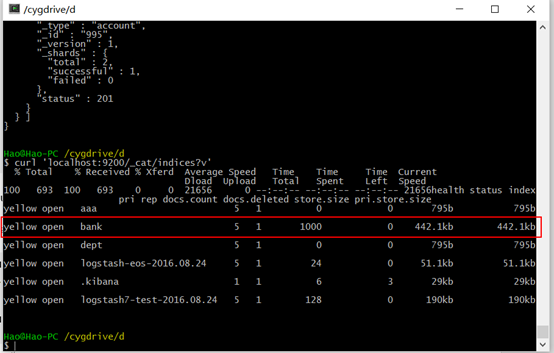
表示我们已经成功批量导入1000条数据索引到bank索引中。
Count根据POST的json,返回命中范围内的总条数。当然没POST时就直接返回该index的总条数了。
Search根据POST的json或者GET的args,返回命中范围内的数据。这是最重要的部分了。下面说说常用的search
6、ES aliases
ES的aliases相关的操作见下一篇文章:《ES之七:elasticsearch之Index Aliases》
7、ES index相关
7.1、Create index API:创建索引
Request
PUT /<index>
示例:创建一个duan的索引,指定mapping,如下:(7.1.1上运行)
PUT duan?include_type_name=true
{
"mappings": {
"duan": {
"properties": {
"amount": {
"type": "long"
},
"event_time": {
"type": "date",
"format": ["yyyy-MM-dd HH:mm:ss"]
},
"member_id": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
}
7.2、Add index alias API:Creates or updates an index alias.
Request
PUT /<index>/_alias/<alias>
POST /<index>/_alias/<alias>
PUT /<index>/_aliases/<alias>
POST /<index>/_aliases/<alias>
示例:PUT /duan/_alias/tong
{
"acknowledged" : true
}
7.3、Get index API:返回index的相关信息
Request
GET /<index>
示例:GET /duan
{
"duan" : {
"aliases" : {
"tong" : { }
},
"mappings" : {
"properties" : {
"amount" : {
"type" : "long"
},
"event_time" : {
"type" : "date",
"format" : "[yyyy-MM-dd HH:mm:ss]"
},
"member_id" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"settings" : {
"index" : {
"creation_date" : "1588469254017",
"number_of_shards" : "1",
"number_of_replicas" : "0",
"uuid" : "30T7HThtRPq-gYtKqiJqnQ",
"version" : {
"created" : "7000099"
},
"provided_name" : "duan"
}
}
}
}
7.4、Get index alias API:查询index的别名信息(Returns information about one or more index aliases.)
Request
GET /_alias
GET /_alias/<alias>
GET /<index>/_alias/<alias>
示例:GET /duan/_alias/tong
{
"duan" : {
"aliases" : {
"tong" : { }
}
}
}
7.5、Put mapping API:为已经存在的index增加字段
Request
PUT /<index>/_mapping
PUT /_mapping
示例:
PUT /publications/_mapping
{
"properties": {
"title": { "type": "text"}
}
}
7.6、Close index API:关闭索引
Request
POST /<index>/_close
7.7、Open index API 打开索引
Request
POST /<index>/_open
针对部分索引,我们暂时不需要对其进行读写,可以临时关闭索引,以减少es服务器的开销.
7.8、Delete index API:Deletes an existing index.
Request
DELETE /<index>
参考:https://www.jianshu.com/p/37a96c532fa7
参考:https://blog.csdn.net/ctwy291314/java/article/details/82836514
- elasticsearch了解多少,说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些
调优手段 。elasticsearch的倒排索引是什么。
- elasticsearch 索引数据多了怎么办,如何调优,部署。
- elasticsearch是如何实现master选举的。
- 详细描述一下Elasticsearch索引文档的过程。
- 详细描述一下Elasticsearch搜索的过程。
- Elasticsearch在部署时,对Linux的设置有哪些优化方法?
- lucence内部结构是什么。
ES之四、Elasticsearch集群和索引常用命令的更多相关文章
- Elasticsearch集群和索引常用命令
https://www.cnblogs.com/pilihaotian/p/5846173.html REST API用途 ES提供了很多全面的API,大致可以分成如下几种: 1 检查集群.节点.索引 ...
- Elasticsearch 集群和索引健康状态及常见错误说明
之前在IDC机房线上环境部署了一套ELK日志集中分析系统, 这里简单总结下ELK中Elasticsearch健康状态相关问题, Elasticsearch的索引状态和集群状态传达着不同的意思. 一. ...
- 实验室 Linux 集群的管理常用命令
实验室有一个Linux集群,本文做一下记录. SSH相关命令 通过SSH登录集群中的其他机器上的操作系统(或虚拟机中的操作系统).操作系统之间已经设置免密码登录. 1. 无选项参数运行 SSH 通常使 ...
- Zookeeper--0200--安装与集群搭建、常用命令、客户端工具
看这里,http://www.cnblogs.com/lihaoyang/p/8358153.html 1,先使用可视化客户端软件 ZooInspector 连接上集群中的一个节点,看下zk的结构: ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- Elasticsearch集群中处理大型日志流的几个常用概念
之前对于CDN的日志处理模型是从logstash agent==>>redis==>>logstash index==>>elasticsearch==>&g ...
- elasticsearch 集群、节点、索引、分片、副本概念
原文链接: https://www.jianshu.com/p/297e13045605 集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分 节点(node): 单个 ...
- ElasticSearch 集群基本概念及常用操作汇总(建议收藏)
内容来源于本人的印象笔记,简单汇总后发布到博客上,供大家需要时参考使用. 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 目录: Elas ...
- 【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
本章其实是ELK第二章的插入章节. 本章ES集群的多节点是docker启动在同一个虚拟机上 ====================================================== ...
随机推荐
- Image合并添加文字内容
场景:将一个头像.二维码.文字信息添加到一张背景图片中,将这些信息合成一张图片. 代码已经测试验证.代码中图片自己随意找几张测试即可. 代码: import com.sun.image.codec.j ...
- Java内存分析1 - 从两个程序说起
这次看一些关于JVM内存分析的内容. 两个程序 程序一 首先来看两个程序,这里是程序一:JVMStackTest,看下代码: package com.zhyea.robin.jvm; public c ...
- scala学习手记24 - 多参数函数值
上一节的函数值只有一个参数.函数值当然也是可以有多个参数的.看一下下面的inject方法: def inject(arr: Array[Int], initial: Int, operation: ( ...
- ActiveMQ_01
http://shhyuhan.iteye.com/blog/1278103http://www.cnblogs.com/blsong/archive/2012/09/26/2704337.htmlh ...
- 学习mybatis时出现了java.io.IOException: Could not find resource EmployeeMapper.xml
使用mybatis时出现了Could not find resource EmployeeMapper.xml和Could not find resource mybatis-config.xml两种 ...
- java中的char类型所占空间
java中统一使用unicode编码,所以每个字符都是2个字节16位.unicode包括中文,所以对String类计算长度的时候,一个中文和一个英文都是一个长度.String voice = &quo ...
- Selenium with Python 004 - 页面元素操作
毫无疑问,首先需要导入webdriver from selenium import webdriver 清除文本 driver.find_element_by_id('kw').clear() 文本输 ...
- Tiny210用户手册笔记
核心板 CPU 处理器: Samsung S5PV210,基于 CortexTM-A8,运行主频 1GHz 内置 P ...
- poj2446
题解: 二分图匹配 看看是否能达到目标 代码: #include<cstdio> #include<cstring> #include<algorithm> #in ...
- 版本工具管理之----git
如何查看隐藏文件夹: 如果你看不到.git目录,你需要让隐藏的文件可见.具体做法就是打开一个Terminal窗口,输入以下命令: defaults write com.apple.finder App ...