Hadoop2.5.2集群部署(完全分布式)
环境介绍
硬件环境
软件环境
Hadoop:hadoop2.5.2 64位
JDK: JDK 1.8.0_91
主机配置规划
设置主机名
如果没有足够的权限,可以切换用户为root
三台机器统一增加以下host配置:

配置免密码登录SSH
ssh-keygen -t rsa
2)将id_dsa.pub(公钥)追加到授权key中:
3)将认证文件复制到另外两台DataNode节点上:
scp ~/.ssh/authorized_keys 172.16.1.157:~/.ssh/
scp ~/.ssh/authorized_keys 172.16.1.158:~/.ssh/
3)测试:
各节点安装JDK
查看目前安装openjdk信息:rpm -qa|grep java

卸载以上三个文件(需要root权限,登录root权限卸载)
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
rpm -e --nodeps tzdata-java-2013g-1.el6.noarch


(4)重命名jdk为jdk1.8(用mv命令)

(5) 配置环境变量:vi /etc/profile加入以下三行
(7)执行Java –version查看jdk版本,验证是否成功
(8)将hadoop01机器上安装好JDK复制到另外两台节点上


Hadoop安装
每台节点都要安装
Hadoop。
上传
hadoop-2.5.2.tar.gz
到用户
/home/hadoop/software
目录下。
解压
添加环境变量
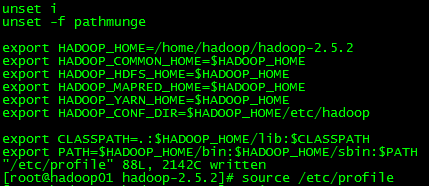
设置环境变量立即生效
配置Hadoop文件
(2)hdfs-site.xml
:9001</value>
/dfs/name</value>
<description>namenode上存储hdfs元数据</description>
/dfs/data</value>
<description>datanode上数据块物理存储位置</description>
(3)mapred-site.xml
(4)yarn-site.xml
:8032</value>
(5)修改slaves文件,添加datanode节点hostname到slaves文件中
如果已经配置了JAVA_HOME环境变量,hadoop-env.sh与yarn-env.sh这两个文件不用修改,因为里面配置就是:
export JAVA_HOME=${JAVA_HOME}
如果没有配置JAVA_HOME环境变量,需要分别在hadoop-env.sh和yarn-env.sh中
手动添加
JAVA_HOME export JAVA_HOME= /home/hadoop/jdk1.8最后,将整个hadoop-2.5.2文件夹及其子文件夹使用scp复制到两台Slave相同目录中:


运行Hadoop
格式化

启动Hadoop
停止Hadoop
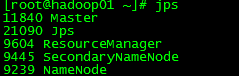
JPS查看进程

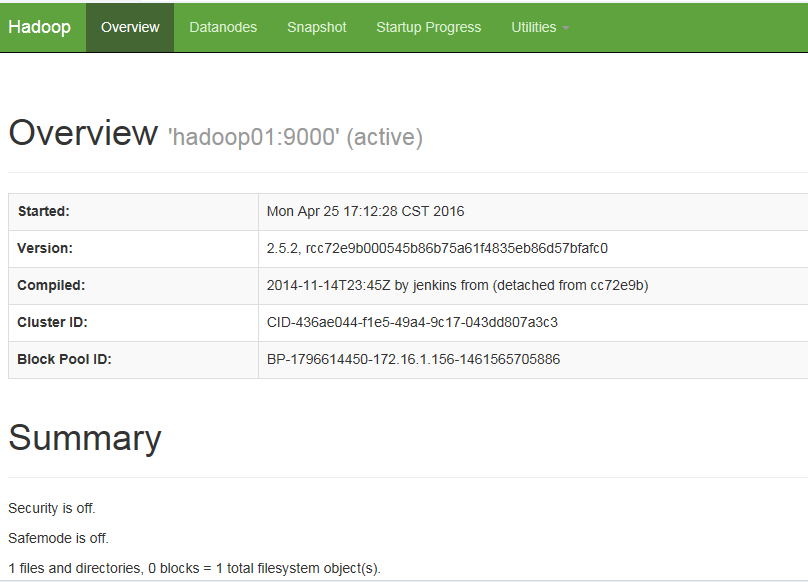
通过浏览器查看集群运行状态
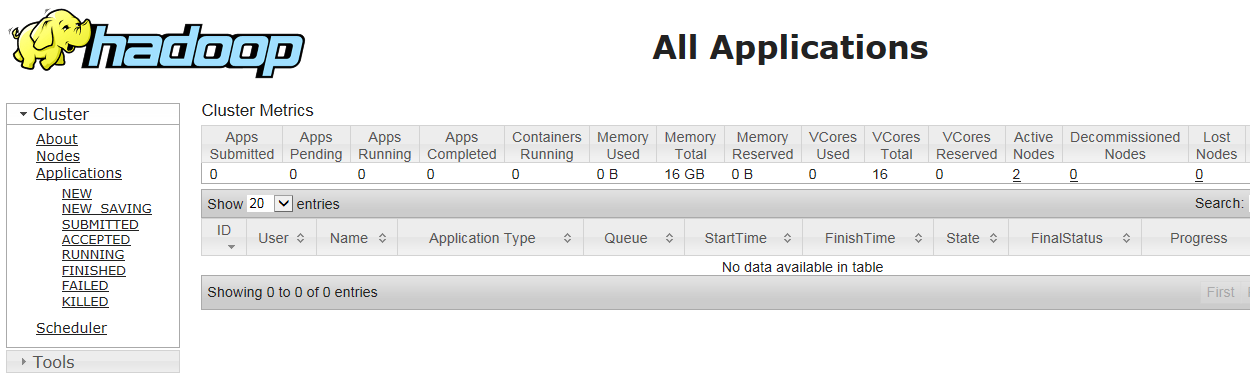

测试Hadoop
vi wordcount.txt
输入内容为:
hello you
hello me
hello everyone
2)建立目录
hadoop fs -mkdir /data/wordcount
hadoop fs –mkdir /output/
3)上传文件
hadoop fs -put wordcount.txt/data/wordcount/
4)执行wordcount程序
hadoop jar usr/local/program/Hadoop-2.5.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.1.jar wordcount /data/wordcount /output/wordcount/
5)查看结果
hadoop fs -text /output/wordcount/part-r-00000
搭建中遇到问题总结
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
问题二:
注:nodemanager启动后要通过心跳机制定期与RM通信,否则RM会认为NM死掉,会停止NM服务。
开启: service iptables start
关闭: service iptables stop
Hadoop2.5.2集群部署(完全分布式)的更多相关文章
- Ubuntu下用hadoop2.4搭建集群(伪分布式)
要真正的学习hadoop,就必需要使用集群,可是对于普通开发人员来说,没有大规模的集群用来測试,所以仅仅能使用伪分布式了.以下介绍怎样搭建一个伪分布式集群. 为了节省时间和篇幅,前面一些步骤不再叙述. ...
- 关于Linux单机、集群部署FastDFS分布式文件系统的步骤。
集群部署:2台tarcker服务器,2台storage服务器. 192.168.201.86 ---------(trackerd+storage+nginx) 192.168.201.87 ...
- Hadoop-2.2.0集群部署时live nodes数目不对的问题
关于防火墙,hadoop本身配置都确定没任何问题,集群启动不报错,但打开50070页面,始终live nodes数目不对,于是我尝试/etc/hosts文件配置是否存在逻辑的错误: 127.0.0.1 ...
- 配置MapReduce插件时,弹窗报错org/apache/hadoop/eclipse/preferences/MapReducePreferencePage : Unsupported major.minor version 51.0(Hadoop2.7.3集群部署)
原因: hadoop-eclipse-plugin-2.7.3.jar 编译的jdk版本和eclipse启动使用的jdk版本不一致导致. 解决方案一: 修改myeclipse.ini文件即可解决. ...
- 分布式Hbase-0.98.4在Hadoop-2.2.0集群上的部署
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3898991.html Hbase 是Apache Hadoop的数据库,能够对大数据提 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
- 基于Hadoop2.7.3集群数据仓库Hive1.2.2的部署及使用
基于Hadoop2.7.3集群数据仓库Hive1.2.2的部署及使用 HBase是一种分布式.面向列的NoSQL数据库,基于HDFS存储,以表的形式存储数据,表由行和列组成,列划分到列族中.HBase ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
随机推荐
- 【洛谷P4568】[JLOI2011]飞行路线
飞行路线 题目链接 今天上午模拟考试考了原题,然而数组开小了,爆了4个点. 据王♂强dalao说这是一道分层图SPFA的裸题 dis[i][j]表示到点i用k个医疗包的最小消耗,dis[u][j]+e ...
- HDFS副本存放读取
HDFS作为Hadoop中 的一个分布式文件系统,而且是专门为它的MapReduce设计,所以HDFS除了必须满足自己作为分布式文件系统的高可靠性外,还必须为 MapReduce提供高效的读写性能,那 ...
- Entity Framework 一
本篇主要介绍:EntityFramework简介, 实体框架架构图, EF版本 实体框架: 编写和管理数据访问的ADO.Net代码是一件单调乏味的工作.微软已经提供了一个名为“实体框架”的O / RM ...
- 数据库——MySQL——存储引擎
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等.数据库中的表也应该有不同的类型,表的类型不同,会对 ...
- 21.Shiro在springboot与vue前后端分离项目里的session管理
1.前言 当决定前端与后端代码分开部署时,发现shiro自带的session不起作用了. 然后通过对请求head的分析,然后在网上查找一部分解决方案. 最终就是,登录成功之后,前端接收到后端传回来的s ...
- HTML简介及基本标记
HTML简介 HTML是Hypertext Markup Language的英文缩写,即超文本标记语言 使用 HTML 语言可以: 控制页面和内容的外观 插入的链接检索联机信息 创建表单,收集用户的信 ...
- 不再手写import - VSCode自动引入Vue组件和Js模块
:first-child{margin-top:0!important}.markdown-body>:last-child{margin-bottom:0!important}.markdow ...
- 【TOJ 1743】集合运算(set并、交、差集)
Description 给定两个集合A和B的所有元素,计算它们的交.并.差集. Input 输入数据有多组,第一行为数据的组数T,接下来有2T行,每组数据占2行,每行有若干个整数,第一行的所有整数构成 ...
- 使用Vscode写python
在python官网下载好python2.x 或者 3.x, 然后在vscode 下载python插件. 写一个python程序, 运行, vscode会自动提示你配置python执行路径,并帮你创建好 ...
- android 自定义滑动按钮
第一接触公司项目就让我画页面,而且还涉及到我最讨厌的自定义view 但是没办法,讨厌也必须要做啊,经过百度上资源的查找,终于写出了一个滑动控件.废话不多说,上代码. package com.eton ...