elasticsearch cluster 详解
上一篇通过clusterservice对cluster做了一个简单的概述, 应该能够给大家一个初步认识。本篇将对cluster的代码组成进行详细分析,力求能够对cluster做一个更清晰的描述。cluster作为多个节点的协同工作机制,它需要节点,节点间通信,各个节点的状态及各个节点上的数据(index)状态。因此这一部分代码包括了上述的几个部分。
首先是节点(DiscoveryNode),这里的节点不同于之前所说的node,只是集群上一个逻辑意义上的节点,只是一个实际节点的描述信息。它实现了Streamable接口和 serializable接口,可以在物理节点上传输。下图是它的field:
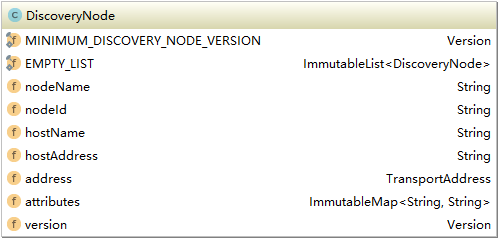
可以看到它只是一个节点的信息描述。在集群中每个节点会被抽象成一个DiscoveryNode,这些DiscoveryNode被封装到DiscoveryNodes中,同时提供一下操作如查找,连接等。这样集群维护所有节点的信息,同时可以根据集群状态进行节点的操作。
集群还需要有一个机制就是集群阻塞,因为处于不同状态的集群能够进行的操作不同,如没有master节点的时候,所有的master操作都要停止,当前的任务是选举master,此时一个block就会引发,通知集群所有节点。不同于同一个jvm中的同步,不同的节点处在不同的jvm中,jvm的同步机制无法使用,因此只能使用这种阻塞机制进行节点间的协调。它的部分代码如下所示:
public class ClusterBlock implements Serializable, Streamable, ToXContent {
private int id;
private String description;
private EnumSet<ClusterBlockLevel> levels;
private boolean retryable;
private boolean disableStatePersistence = false;
private RestStatus status;
ClusterBlock() {
}
public ClusterBlock(int id, String description, boolean retryable, boolean disableStatePersistence, RestStatus status, EnumSet<ClusterBlockLevel> levels) {
this.id = id;
this.description = description;
this.retryable = retryable;
this.disableStatePersistence = disableStatePersistence;
this.status = status;
this.levels = levels;
}
}
阻塞主要由三部分组成,描述(description),阻塞级别(READ(0),WRITE(1), METADATA(2)),及restful状态码RestStatus构成。阻塞级别主要用于节点间对于index的操作的阻塞,如某个index在进行恢复过程时,它的状态是MATEDATA级别,此时不能够对其进行任何读写操作。 RestStatus主要用于restful请求的阻塞。最后要说的就是ack机制,集群的很多操作都需要节点响应。因此cluster定义了ack的请求和响应接口。所有需要ack的请求通过实现此ack接口都能够实现。另外集群还涉及matedata和routing,这两部分其实都是针对数据(index),如matedata主要是mapping,index, alias的相关元数据,因此这两部分会在分析数据功能时在做分析。
说完了DiscoveryNode和block,接下来通过clusterService接口,它的作用主要是提供对外调用。这个接口主要提供Listener,block的add和remove及cluster状态的更新提交。cluster只是一个理论上的实体,其实并不存在,所有功能都是由各个节点来完成的。因此clusterService接口主要方法是集群状态监听器的操作。它的类图:

这里着重说一下submitStateUpdateTask的实现。对于节点来说,如果它探测到集群状态的更新,如果它是master则它需要向其它节点发布。代码如下:
public void submitStateUpdateTask(final String source, Priority priority, final ClusterStateUpdateTask updateTask) {
if (!lifecycle.started()) {
return;
}
try {
//封装成updateTask
final UpdateTask task = new UpdateTask(source, priority, updateTask);
//会超时的任务
if (updateTask instanceof TimeoutClusterStateUpdateTask) {
final TimeoutClusterStateUpdateTask timeoutUpdateTask = (TimeoutClusterStateUpdateTask) updateTask;
updateTasksExecutor.execute(task, threadPool.scheduler(), timeoutUpdateTask.timeout(), new Runnable() {
@Override
public void run() {
threadPool.generic().execute(new Runnable() {
@Override
public void run() {
timeoutUpdateTask.onFailure(task.source(), new ProcessClusterEventTimeoutException(timeoutUpdateTask.timeout(), task.source()));
}
});
}
});
} else {
updateTasksExecutor.execute(task);
}
} catch (EsRejectedExecutionException e) {
// ignore cases where we are shutting down..., there is really nothing interesting
// to be done here...
if (!lifecycle.stoppedOrClosed()) {
throw e;
}
}
}
上面的代码逻辑很简单,对于提交的task进行封装然后运行。这里运行的是ClusterStateUpdateTask, 它的实现很多,无法一一说明。但是它的方法说明了一切,它的类图如下所示:
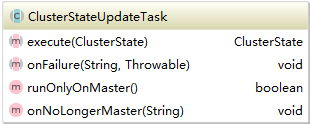
子类的主要逻辑实现都在execute方法中,比如ZenDiscovery中handleMasterGone中的实现,master丢失后会进行master选举或者是试图加入新组成的集群。这些在后面的分析中可以看到。
总结一下,cluster是由很多功能组成的,如DiscoveryNode,block等。这一部分的主要代码是提供一些集群状态更新及监听的接口。集群状态的更新发布master独有的功能,但是监听集群状态变得时每个节点都需要的。这些功能的具体实现在后面的分析中会逐步分析。
elasticsearch cluster 详解的更多相关文章
- Elasticsearch配置详解、文档元数据
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.Elasticsearch配置文件详解 a. 在上面博客中,我们已经安装并且成功 ...
- 搜索引擎框架之ElasticSearch基础详解(非原创)
文章大纲 一.搜索引擎框架基础介绍二.ElasticSearch的简介三.ElasticSearch安装(Windows版本)四.ElasticSearch操作客户端工具--Kibana五.ES的常用 ...
- elasticsearch配置详解
一.说明 使用的是新版本5.1,直接从官网下载rpm包进行安装,https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5 ...
- 分布式搜索elasticsearch配置文件详解
elasticsearch的config文件夹里面有两个配置文件:elasticsearch.yml和logging.yml,第一个是es的基本配置文件,第二个是日志配置文件,es也是使用log4j来 ...
- Elasticsearch安装详解
本文只介绍在windows上的安装和配置,其他安装和配置请参见官方文档 ES在windows上安装需下载zip安装包,解压后bin目录下有个 elasticsearch-service.bat 文件. ...
- elasticsearch配置文件详解
来自:http://www.searchtech.pro/articles/2013/02/18/1361194291548.html elasticsearch的config文件夹里面有两个配置文 ...
- elasticsearch配置文件(elasticsearch.yml)详解
来自:http://www.searchtech.pro/articles/2013/02/18/1361194291548.html elasticsearch的config文件夹里面有两个配置文 ...
- ElasticSearch 配置详解
配置文件位于es根目录的config目录下面,有elasticsearch.yml和logging.yml两个配置,主配置文件是elasticsearch.yml,日志配置文件是logging.yml ...
- 配置文件elasticsearch.yml详解
在es根目录下的config目录中有elasticsearch.yml配置文件,es加载使用的yml格式配置 17行:cluster.name: 自定义集群名称(强烈推荐默认名称elasticsear ...
随机推荐
- 快速架设OpenStack云基础平台
通常在linux下手工安装openstack比较麻烦,StackOps是一个可以快速安装的Openstack解决方案,首先我们下载StackOps的iso文件(stackops-0.5-b1312-d ...
- Android控件-ViewPager(仿微信引导界面)
什么是ViewPager? ViewPager是安卓3.0之后提供的新特性,继承自ViewGroup,专门用以实现左右滑动切换View的效果. 如果想向下兼容就必须要android-support-v ...
- Oracle 审计初步使用
新增一个表空间用于存储审计日志 SQL> CREATE tablespace audit_data datafile '/data/oradata/orcl/audit01.dbf' SIZE ...
- Ubuntu16.04进入挂起或休眠状态时按任何键都无法唤醒问题解决办法
挂起(待机)计算机将目前的运行状态等数据存放在内存,关闭硬盘.外设等设备,进入等待状态.此时内存仍然需要电力维持其数据,但整机耗电很少.恢复时计算机从内存读 出数据,回到挂起前的状态,恢复速度较快.一 ...
- Django_高级扩展
- jquery正则匹配URL地址
JQuery代码: var regexp = /((http|ftp|https|file):\/\/([\w\-]+\.)+[\w\-]+(\/[\w\u4e00-\u9fa5\-\.\/?\@\% ...
- microsoft SQL server,错误2
大二下開始学习数据库,一開始就把数据库装了,结果数据库第一节实验课就是教我们装数据库,而且要在自己机子上装,还要实验报告和截图.老师叫我把原本的卸载掉, 于是对着网上一系列的操作卸载server删除目 ...
- Multidex实现简要分析
1.Multidex的产生 在android5.0之前,每一个android应用中只会含有一个dex文件,但是因为Android系统本身的BUG,使得这个dex的方法数量被限制在65535之内,这就是 ...
- Java: 数据类型
核心:对事物的某种规范 前提: 1.JAVA:JAVA程序的运行是以堆栈的操作来完成的 堆栈以帧为单位保存线程的状态. JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作. 理解 ...
- command---调用指定的指令并执行
command命令调用指定的指令并执行,命令执行时不查询shell函数.command命令只能够执行shell内部的命令. 语法 command(参数) 参数 指令:需要调用的指令及参数. 实例 使用 ...