BP网络中的反向传播
本文的主要参考:How the backpropagation algorithm works
下面是BP网络的参数结构示意图
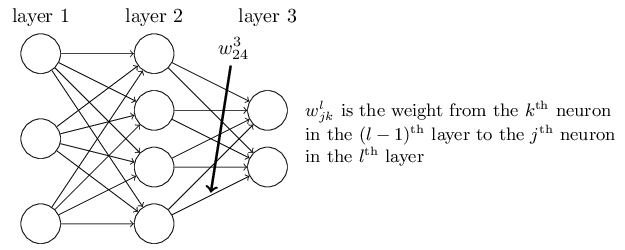
首先定义第l层网络第j个神经元的输出(activation)

为了表示简便,令

则有alj=σ(zlj),其中σ是激活函数
定义网络的cost function,其中的n是训练样本的个数。

下面主要介绍使用反向传播来求取cost function相对于权重wij和偏置项bij的导数。
显然,当输入已知时,cost function只是权值w和偏置项b的函数。这里为了方便推倒,首先计算出∂C/∂zlj,令
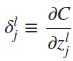
由于alj=σ(zlj),所以显然有
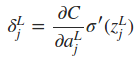
式中的L表示最后一层网络,即输出层。如果只考虑一个训练样本,则cost function可表示为
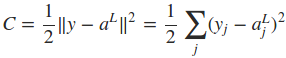
如果将输出层的所有输出看成一个列向量,则δjL可以写成下式,Θ表示向量的点乘

下面最关键的问题来了,如何同过δl+1求取δl。这里就用到了∂C/∂zlj这一重要的中间表达,推倒过程如下
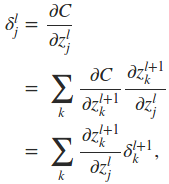

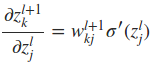
因此,最终有
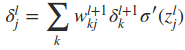
写成向量的形式为
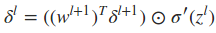
利用与上面类似的推倒,可以得到

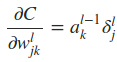
将上面重要的公式用矩阵乘法形式再表达一遍

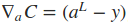

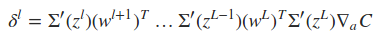
式中Σ'(zL)是主对角线上的元素为σ'(zLj)的对角矩阵。求取了cost function相对于权重wij和偏置项bij的导数之后,便可以使用一些基于梯度的优化算法对网络的权值进行更新。下面是一个2输入2输出的一个BP网络的代码示例,实现的是对输入的每个元素进行逻辑取反操作。
import numpy as np def tanh(x):
return np.tanh(x) def tanh_prime(x):
x = np.tanh(x)
return 1.0 - x ** 2 class Network(object): def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
# self.biases is a column vector
# self.weights' structure is the same as in the book: http://neuralnetworksanddeeplearning.com/chap2.html
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])] def feedforward(self, a):
"""Return the output of the network if "a" is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a) + b)
return a def update_mini_batch(self, mini_batch, learning_rate = 0.2):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)"."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights] # delta_nabla_b is dC/db, delta_nabla_w is dC/dw
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w - (learning_rate/len(mini_batch)) * nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b - (learning_rate/len(mini_batch)) * nb
for b, nb in zip(self.biases, nabla_b)] def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer # After this loop, activations = [a0, a1, ..., aL], zs = [z1, z2, ..., zL]
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation) + b
zs.append(z)
activation = sigmoid(z)
activations.append(activation) # backward pass
# delta = deltaL .* sigma'(zL)
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1]) # dC/dbL = delta
# dC/dwL = deltaL * a(L-1)^T
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose()) '''Note that the variable l in the loop below is used a little
differently to the notation in Chapter 2 of the book. Here,
l = 1 means the last layer of neurons, l = 2 is the
second-last layer, and so on. It's a renumbering of the
scheme in the book, used here to take advantage of the fact
that Python can use negative indices in lists.'''
# z = z(L-l+1), here, l start from 2, end with self.num_layers-1, namely, L-1
# delta = delta(L-l+1) = w(L-l+2)^T * delta(L-l+2) .* z(L-l+1)
# nabla_b[L-l+1] = delta(L-l+1)
# nabla_w[L-l+1] = delta(L-l+1) * a(L-l)^T
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return (nabla_b, nabla_w) def evaluate(self, test_data):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = self.feedforward(test_data)
return test_results def cost_derivative(self, output_activations, y):
return (output_activations - y) #### Miscellaneous functions
def sigmoid(z):
return 1.0/(1.0 + np.exp(-z)) # derivative of the sigmoid function
def sigmoid_prime(z):
return sigmoid(z) * (1 - sigmoid(z)) if __name__ == '__main__': nn = Network([2, 2, 2]) X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]]) y = np.array([[1, 1],
[1, 0],
[0, 1],
[0, 0]]) for k in range(40000):
if k % 10000 == 0:
print 'epochs:', k
# Randomly select a sample.
i = np.random.randint(X.shape[0])
nn.update_mini_batch(zip([np.atleast_2d(X[i]).T], [np.atleast_2d(y[i]).T])) for e in X:
print(e, nn.evaluate(np.atleast_2d(e).T))
运行结果
epochs:
epochs:
epochs:
epochs:
(array([, ]), array([[ 0.98389328],
[ 0.97490859]]))
(array([, ]), array([[ 0.97694707],
[ 0.01646559]]))
(array([, ]), array([[ 0.03149928],
[ 0.97737158]]))
(array([, ]), array([[ 0.01347963],
[ 0.02383405]]))
BP网络中的反向传播的更多相关文章
- 神经网络中的反向传播法--bp【转载】
from: 作者:Charlotte77 出处:http://www.cnblogs.com/charlotte77/ 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学 ...
- 一文弄懂神经网络中的反向传播法——BackPropagation【转】
本文转载自:https://www.cnblogs.com/charlotte77/p/5629865.html 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学习 ...
- 一文弄懂神经网络中的反向传播法——BackPropagation
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进 ...
- [转] 一文弄懂神经网络中的反向传播法——BackPropagation
在看CNN和RNN的相关算法TF实现,总感觉有些细枝末节理解不到位,浮在表面.那么就一点点扣细节吧. 这个作者讲方向传播也是没谁了,666- 原文地址:https://www.cnblogs.com/ ...
- PyTorch中在反向传播前为什么要手动将梯度清零?
对于torch中训练时,反向传播前将梯度手动清零的理解 简单的理由是因为PyTorch默认会对梯度进行累加.至于为什么PyTorch有这样的特点,在网上找到的解释是说由于PyTorch的动态图和aut ...
- 一文弄懂神经网络中的反向传播法(Backpropagation algorithm)
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进 ...
- 【机器学习】反向传播算法 BP
知识回顾 1:首先引入一些便于稍后讨论的新标记方法: 假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络的层数,S表示每层输入的神经元的个数,SL代表最后一层中处理的单元 ...
- 反向传播(BP)算法理解以及Python实现
全文参考<机器学习>-周志华中的5.3节-误差逆传播算法:整体思路一致,叙述方式有所不同: 使用如上图所示的三层网络来讲述反向传播算法: 首先需要明确一些概念, 假设数据集\(X=\{x^ ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
随机推荐
- MySQL主从复制和读写分离
我们知道应用对数据库的訪问通常情况下大部分都是读操作,写仅仅占非常少一部分.因此读写分离(read-write-splitting)能有效减少主库压力,从而解决站点发展过程中遇到的第一次数据库瓶颈. ...
- 兼容chrome和ie的音乐播放
兼容chrome和ie的音乐播放(Ie7 Ie8 Ie9 均測试过 ) <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitiona ...
- Linux USB 驱动开发(一)—— USB设备基础概念【转】
本文转载自:http://blog.csdn.net/zqixiao_09/article/details/50984074 在终端用户看来,USB设备为主机提供了多种多样的附加功能,如文件传输,声音 ...
- contest hunter5105 Cookies
神题 先按贪婪值大到小排序,根据贪心的思想g[i]越大a[i]也越大(这个微扰可以证,给个提示,a>b且c<d 则 (a-b)(c-d)<0 则 ac+bd<ad+bc) DP ...
- jumpserver install
本文来源jumpserver官网 一步一步安装 环境 系统: CentOS 7 IP: 192.168.244.144 关闭 selinux 和防火墙 # CentOS 7 $ setenforce ...
- VS2015启动显示无法访问此网站
之前启动项目发生过几次,也忘了怎么解决了,今天记录一下:将应用文件夹下的vs目录删除,重新生成解决方案后,程序正常启动. 原文链接:https://blog.csdn.net/upi2u/articl ...
- url 域名 主机名
1. url = 协议//主机名(包括服务器的计算机名+域名)/路径 https:// i. cnblogs.com /index.html .com是顶级域名,从右向左,每碰到一个".&q ...
- nodejs -- crypto MD5签名
MD5使用方法: const crypto = require('crypto'); var obj = crypto.createHash('md5'); // 可多次调用 update obj.u ...
- vue-cli 安装
1 node 下载 http://nodejs.cn/download/ 安装 2 npm install vue-cli -g 3 vue init <template-n ...
- [转] 利用git钩子,使用python语言获取提交的文件列表
项目有个需求,需要获取push到远程版本库的文件列表,并对文件进行特定分析.很自然的想到,要利用git钩子来触发一个脚本,实现获取文件列表的功能.比较着急使用该功能,就用python配合一些git命令 ...