SkipList跳表(一)基本原理
一直听说跳表这个数据结构,说要学一下的,懒癌犯了,是该治治了
为什么选择跳表
目前经常使用的平衡数据结构有:B树、红黑树,AVL树,Splay Tree(这个树好像还没有听说过),Treep(也没有听说过)等。
想象一下,给你一张草稿纸,一支笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树出来吗?
不好意思,我tmd连冒泡都实现不了......
很难吧,这需要时间,需要考虑很多细节,需要参考一堆算法与数据结构之类的书,还需要参考网上的代码,比较麻烦
用跳表吧,跳表是一种随机化的数据结构,目前开源软件Redis和LevelDB(这是个啥)都有用到它。
他的效率和红黑树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个SkipList。
有序表的搜索
考虑一个有序表

从该表中搜索元素<23,43,59>,需要比较的次数分别为<2,4,6>,总共比较的次数为
2+4+6=12次。有没有优化的算法么?链表是有序的,但不能使用二分查找。
类似二叉搜索树,我们可以把一些节点提取出来,作为索引。得到如下结构:

这里我们把<14,34,50,72>提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。
我们还可以再从一级索引中提取一些元素出来,作为二级索引,变成如下结构:
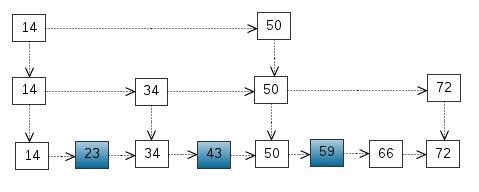
这里元素不多体现不出优势来,如果元素足够多,这种索引结构就能体现出优势来了。
跳表
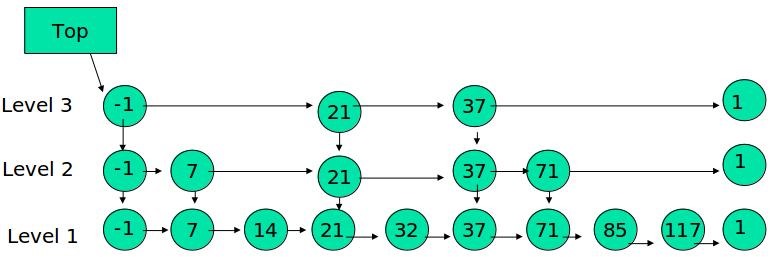
下面的结构就是跳表:
其中-1表示INT_MIN,链表的最小值,1表示INT_MAX,链表的最大值。
跳表具有如下性质:
1. 由很多层结构组成
2. 每一层都是一个有序的链表
3. 最底层(Level 1)的链表包含了所有元素
4. 如果一个元素出现在Level i的链表中,则它在Level i之下的链表也都会出现
5. 每个节点包含了2个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
跳表的搜索
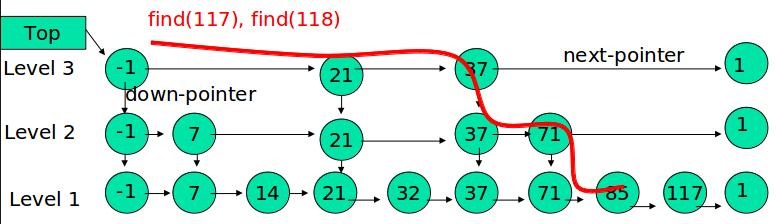
图中搜索117的过程用红色线画出来的,从上到下已经很明显了,在此不赘述
具体的搜索算法如下:
/* 如果存在x,返回x所在的节点,否则返回x的后继节点 */
find(x) {
p = top;
while (l) {
while (p->next->key < x)
p = p->next;
if (p->down == NULL)
return p->next;
p = p->down;
}
}
跳表的插入
先确定该元素要占据的层数K(采用丢硬币的方式,这完全是随机的)
然后再Level 1 ...... Level K各个层的链表都插入元素
例如,插入119,K=2
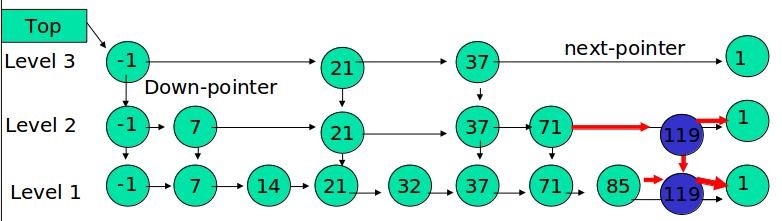
如果K大于链表的层数,则要添加新的层。
例如,插入119,K=4
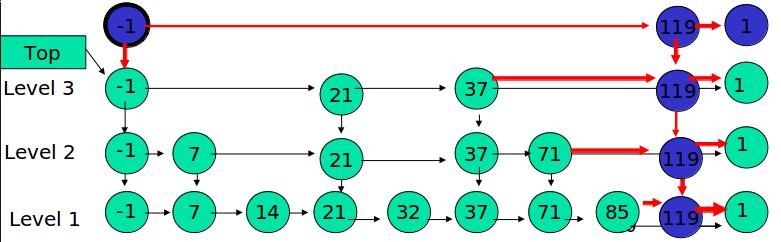
丢硬币决定K
插入元素的时候,元素所占据的层数完全是随机的,通过以下随机算法:
int random_level() {
K = 1;
while (random(0, 1))
K++;
return K;
}
相当于做了一次丢硬币的实验,如果遇到正面,继续丢,遇到反面则停止,】
用实验中丢硬币的次数K作为元素占有的层数。显然随机变量K满足p=1/2的几何分布,K的期望值是E[K] = 1/p = 2。
也就是说,各个元素的层数,期望值是2层。
跳表的高度
n个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数K,跳表的高度等于这n次实验中产生的最大K。
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度是2,一个大小为n的跳表,其节点数目的期望是2n。
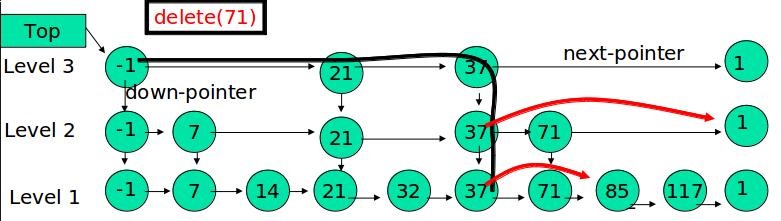
跳表的删除
在各个层中找到包含x的节点,使用标准的delete from list方法删除。
SkipList跳表(一)基本原理的更多相关文章
- skiplist 跳表(2)-----细心学习
快速了解skiplist请看:skiplist 跳表(1) http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非 ...
- skiplist 跳表(1)
最近学习中遇到一种新的数据结构,很实用,搬过来学习. 原文地址:skiplist 跳表 为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等. ...
- 利用skipList(跳表)来实现排序(待补充)
用于排名的数据结构 一般排序为利用堆排序(二叉树)和利用skipList(跳表)的方式 redis中SortedSet利用skipList(跳表)来实现排序,复杂度为O(logn),利用空间换时间,类 ...
- skiplist(跳表)的原理及JAVA实现
前记 最近在看Redis,之间就尝试用sortedSet用在实现排行榜的项目,那么sortedSet底层是什么结构呢? "Redis sorted set的内部使用HashMap和跳跃表(S ...
- SkipList跳表基本原理
为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等. 想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树 出来吗 ...
- 【转】SkipList跳表基本原理
增加了向前指针的链表叫作跳表.跳表全称叫做跳跃表,简称跳表.跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表.跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找.跳表不仅 ...
- JAVA SkipList 跳表 的原理和使用例子
跳跃表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好. 关于跳跃表的具体介绍可以参考MIT的公开课:跳跃表 跳跃表的应 ...
- SkipList 跳表
1.定义描述 跳跃列表(也称跳表)是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间). 基本上,跳跃列表是对有序的链表增加 ...
- 转:SkipList跳表
http://kenby.iteye.com/blog/1187303 相关概念: 1.几何分布 http://baike.baidu.com/link?url=DdtNq6pCWIvr7onVBtE ...
随机推荐
- EasySlider-最简洁的JQuery滚动插件 可控制滚动
原文发布时间为:2010-05-05 -- 来源于本人的百度文章 [由搬家工具导入] Easy Silder是由Alen Grakalic开发的基于JQuery的滚动插件,它支持以下功能: 1.自动滚 ...
- UART接口介绍
1. 简介 UART, Universal Asynchronous Receiver-Transmitter, 通用异步收发传输器 UART协议规定了通信双方所遵守的规定,属于数据链路层RS232接 ...
- DNS解析过程详解【转】
转自:http://blog.chinaunix.net/uid-28216282-id-3757849.html 先说一下DNS的几个基本概念: 一. 根域 就是所谓的“.”,其实我们的网址www. ...
- C 语言调用python 脚本函数
刚好几个月前做过,C++ 函数里面先加载python 脚本,再调用 里面的 def 函数,我把代码贴出来,你在main 函数里面,调用getDataByScript 函数,另外相同目录下放一个 fuc ...
- Python学习杂记_9_集合操作
集合集合是由花括号括起来的一组数据,特点是“数据不重复”,“无序”,“类型不统一”.其中数据不重复是它最重要的特点,常常用于“去重”操作,Set(list)方法可以把列表强制转换成集合. 集合的一些操 ...
- C#Qrcode生成二维码支持中文,带图片,带文字
C#Qrcode生成二维码支持中文带图片的操作请看二楼的帖子,当然开始需要下载一下C#Qrcode的源码 下载地址 : http://www.codeproject.com/Articles/2057 ...
- Color.FromArgb()方法详解
关于颜色值的表示 常用的颜色值表示方式有两种,一种是10进制的RGB值表示,如(0,113,255),三个值分别表示(红,绿,蓝):一种是16进制的颜色码表示,如#ff3212.这两种形式在编程中都可 ...
- 查看windows进程,并删除
1. 通过[任务管理器]可以查看windows进程. 有些进程不在[任务管理器]中. 2. 通过tasklist命令查看进程. 杀掉进程: epmd 进程,在停止.卸载后rabbitmq服务还在. 通 ...
- 【原创】SSO-Javascript模拟IE登录,不让IIS弹出登录窗口
解决方案: 用JS模拟IE用户登录,再跳转到对应的系统. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN&q ...
- vue.js移动端app实战2
貌似有部分人要求写的更详细,这里多写一点vuel-cli基础的配置 什么是vue-cli? 官方的解释是:A simple CLI for scaffolding Vue.js projects,简单 ...