第1节 flume:11、flume的failover机制实现高可用
1.4 高可用Flum-NG配置案例failover
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:
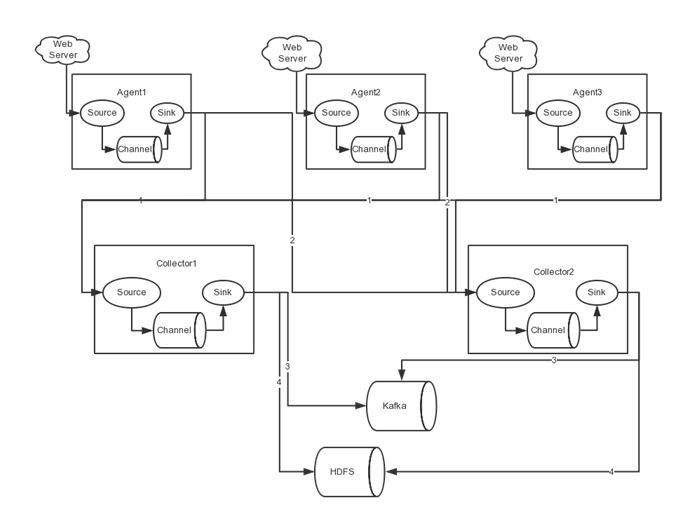
图中,我们可以看出,Flume的存储可以支持多种,这里只列举了HDFS和Kafka(如:存储最新的一周日志,并给Storm系统提供实时日志流)。
1.4.1、角色分配
Flume的Agent和Collector分布如下表所示:
|
名称 |
HOST |
角色 |
|
Agent1 |
node01 |
Web Server |
|
Collector1 |
node02 |
AgentMstr1 |
|
Collector2 |
node03 |
AgentMstr2 |
图中所示,Agent1数据分别流入到Collector1和Collector2,Flume NG本身提供了Failover机制,可以自动切换和恢复。在上图中,有3个产生日志服务器分布在不同的机房,要把所有的日志都收集到一个集群中存储。下 面我们开发配置Flume NG集群
1.4.2、node01安装配置flume与拷贝文件脚本
将node03机器上面的flume安装包以及文件生产的两个目录拷贝到node01机器上面去
node03机器执行以下命令
cd /export/servers
scp -r apache-flume-1.6.0-cdh5.14.0-bin/ node01:$PWD
scp -r shells/ taillogs/ node01:$PWD
node01机器配置agent的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim agent.conf
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#
##set gruop
agent1.sinkgroups = g1
#
##set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
#
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /export/servers/taillogs/access_log
#
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
#
## set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node02
agent1.sinks.k1.port = 52020
#
## set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = node03
agent1.sinks.k2.port = 52020
#
##set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#
##set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
#
1.4.3、node02与node03配置flumecollection
node02机器修改配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim collector.conf
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#
##set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
## other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = node02
a1.sources.r1.channels = c1
#
##set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://node01:8020/flume/failover/
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
#
node03机器修改配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim collector.conf
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#
##set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
## other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = node03
a1.sources.r1.channels = c1
#
##set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path= hdfs://node01:8020/flume/failover/
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
1.4.4、顺序启动命令
node03机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
node02机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/collector.conf -Dflume.root.logger=DEBUG,console
node01机器上面启动flume
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n agent1 -c conf -f conf/agent.conf -Dflume.root.logger=DEBUG,console
node01机器启动文件产生脚本
cd /export/servers/shells
sh tail-file.sh
1.4.5、 FAILOVER测试
下面我们来测试下Flume NG集群的高可用(故障转移)。场景如下:我们在Agent1节点上传文件,由于我们配置Collector1的权重比Collector2大,所以 Collector1优先采集并上传到存储系统。然后我们kill掉Collector1,此时有Collector2负责日志的采集上传工作,之后,我 们手动恢复Collector1节点的Flume服务,再次在Agent1上次文件,发现Collector1恢复优先级别的采集工作。具体截图如下所 示:
Collector1优先上传
HDFS集群中上传的log内容预览
Collector1宕机,Collector2获取优先上传权限
重启Collector1服务,Collector1重新获得优先上传的权限
第1节 flume:11、flume的failover机制实现高可用的更多相关文章
- 11.Redis 哨兵集群实现高可用
作者:中华石杉 Redis 哨兵集群实现高可用 哨兵的介绍 sentinel,中文名是哨兵.哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能: 集群监控:负责监控 redis mast ...
- 《即时消息技术剖析与实战》学习笔记11——IM系统如何保证服务高可用:流量控制和熔断机制
IM 系统的不可用主要有以下两个原因: 一是无法预测突发流量,即使进行了服务拆分.自动扩容,但流量增长过快时,服务已经不可用了: 二是业务中依赖的这些接口.资源不可用或变慢时,比如发消息可能需要依赖& ...
- Kubernetes实战(一):k8s v1.11.x v1.12.x 高可用安装
说明:部署的过程中请保证每个命令都有在相应的节点执行,并且执行成功,此文档已经帮助几十人(仅包含和我取得联系的)快速部署k8s高可用集群,文档不足之处也已更改,在部署过程中遇到问题请先检查是否遗忘某个 ...
- Flume的load-balance、failover
配置flume集群参考https://www.cnblogs.com/jifengblog/p/9277793.html load-balance负载均衡 介绍 负载均衡是用于解决一台机器(一个进程) ...
- 高可用Hadoop平台-Flume NG实战图解篇
1.概述 今天补充一篇关于Flume的博客,前面在讲解高可用的Hadoop平台的时候遗漏了这篇,本篇博客为大家讲述以下内容: Flume NG简述 单点Flume NG搭建.运行 高可用Flume N ...
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- Flume 高可用配置案例+load balance负载均衡+ 案例:日志的采集及汇总
高可用配置案例 (一).failover故障转移 在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示: (1)节点分配 Flume的Agent和Colle ...
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
随机推荐
- 服务迁移之路 | Spring Cloud向Service Mesh转变
一.导读 Spring Cloud基于Spring Boot开发,提供一套完整的微服务解决方案,具体包括服务注册与发现,配置中心,全链路监控,API网关,熔断器,远程调用框架,工具客户端等选项中立的开 ...
- (水题)洛谷 - P2439 - 阶梯教室设备利用 - 简单dp
https://www.luogu.org/fe/problem/P2439 很明显时间是一个维度,按照时间顺序决策就行了. dp[i]表示以时间i为结尾所能达到的最长演讲时间. #include & ...
- 51nod1640 【最小生成树】
题意: 在一副图中,搞N-1条边,使得每个点都相连, 有多种可能的情况,所以求一种使得其中n-1条边的最大是所有可能的最小,然后并保证连接的n-1条边的权值总和最大 思路: 一开始没有看清题意,随便写 ...
- hdoj5493【树状数组+二分】
题意: 给你n个人的高度, 再给出一个值代表该高度下有前面比他高的 或 后面比他高的人数, 求满足条件下的最小字典序, 不行的话输出"impossible" 思路: 对于最小字典序 ...
- Unity Prefabs
通过上一期的学习,我们知道为了如何向场景中添加一个物体.问题来了,如果需要对这个立方体进行修改应该怎么做呢?那我们肯定就得修改这段代码,能不能将立方体本身从我们的开发中单独提出来呢?这就涉及到我们今天 ...
- Html5shiv ---- 让IE低版本浏览器识别并支持HTML5标签
Html5shiv.js是针对IE浏览器的 javaScript 补丁,作用如题 该脚本的下载链接 使用使在head标签中使用script标签引用即可
- IT兄弟连 JavaWeb教程 EL表达式中的内置对象
EL语言定义了11个隐含对象,它们都是java.util.Map类型,网页制作者可通过它们来便捷地访问Web应用中的特定数据.表1对这11个隐含对象做了说明. 1 EL表达式中的内置对象 这11个隐 ...
- CF1175E Minimal Segment Cover 题解
题意:给出\(n\)个形如\([l,r]\)的线段.\(m\)次询问,每次询问区间\([x,y]\),问至少选出几条线段,使得区间\([x,y]\)的任何一个部位都被至少一条线段覆盖. 首先有一个显然 ...
- kafka剖析(转)
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 213. 打家劫舍 II
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金.这个地方所有的房屋都围成一圈,这意味着第一个房屋和最后一个房屋是紧挨着的.同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在 ...