python3爬取豆瓣top250电影
需求:爬取豆瓣电影top250的排名、电影名称、评分、评论人数和一句话影评
环境:python3.6.5
准备工作:
豆瓣电影top250(第1页)网址:https://movie.douban.com/top250?start=0 或者 https://movie.douban.com/top250
每页展示25个电影,一共10张翻页
第2页:https://movie.douban.com/top250?start=&filter=
第3页:https://movie.douban.com/top250?start=&filter=
……
最后一页:https://movie.douban.com/top250?start=&filter=
由此可见,除了首页代码其他9页(相对首页增加了一些字符串)以25递增
查看每页的html代码:
在浏览器空白区域点击“查看源代码”(不同的浏览器可能起的名字不一样),找到所需要的内容。
快速定位html有效信息的方法:
例如排名第一的电影是《肖申克的救赎》,在html源码中搜索(ctrl+F)这个名字(不要加书名号),快速定位大致位置,如下图
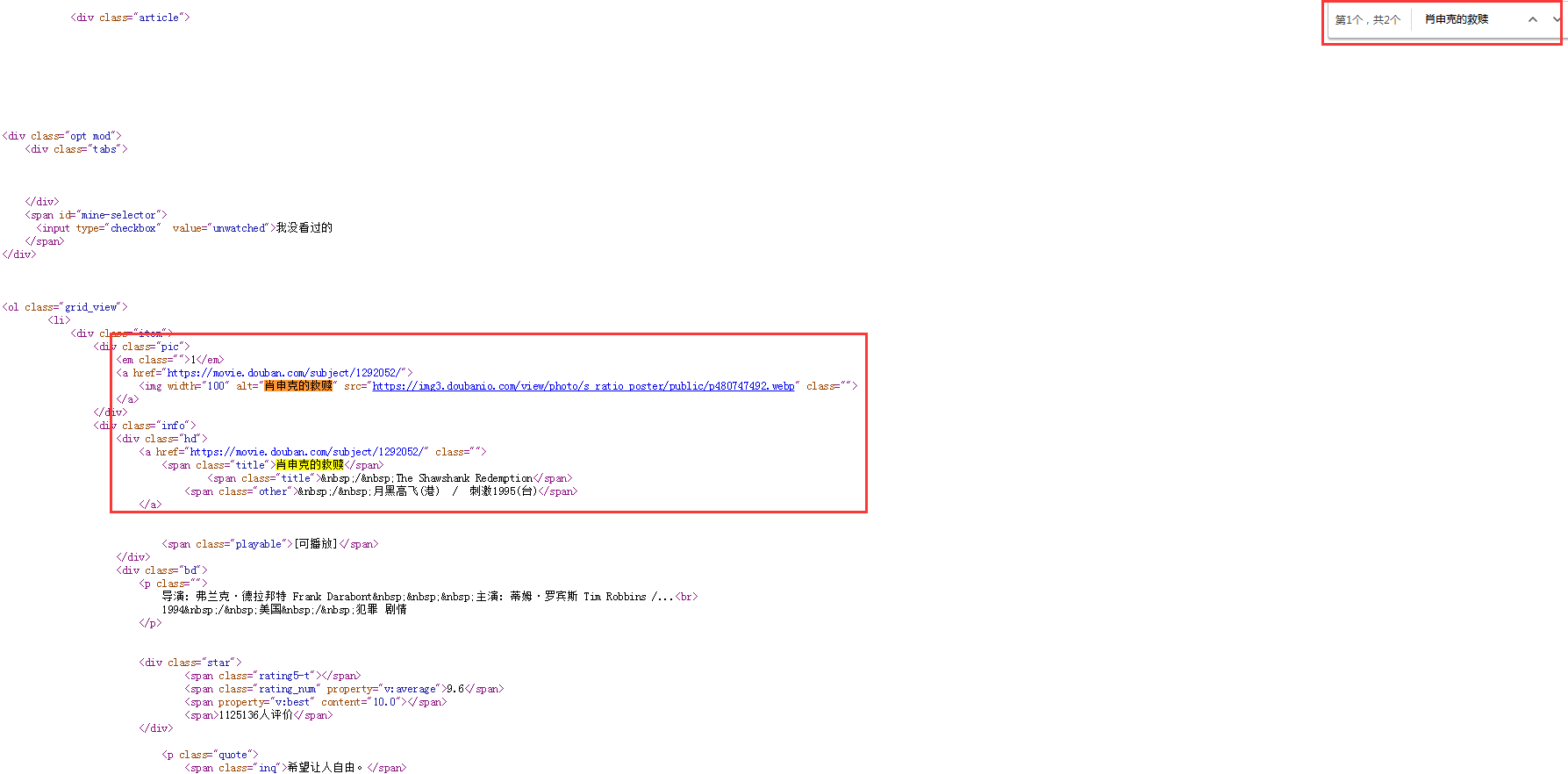
仔细研究html代码:
所有影片存放在ol列表中,每一部影片在一个li中,需要提取的信息在不同的标签中,如下图所示

代码逻辑为:查找ol→li→各个标签
需要用到的第三方库:
from bs4 import BeautifulSoup as bs
from urllib import request
读取html源码(以首页为例)
h="https://movie.douban.com/top250"
resp = request.urlopen(h)
html_data = resp.read().decode('utf-8')
soup = bs(html_data,'lxml')
#print(soup.prettify())
第5行的soup.prettify()输出的比较好看,但是有可能更改一些并列标签的前后位置,用这个输出只是看起来更人性化一些
查找ol标签,获取本页面上25部电影
通过class名称,因为这个class是唯一命名的,因此无需find_all,只需要find(这个是查找第一个)
movieList = soup.find('ol',attrs={'class':"grid_view"})
在ol内查找li标签,无class和id,只需标签名即可
movie = movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
返回结果是一位数组,每个元素是li标签
在每一个li标签内提取有用信息
for i in range(0,25):
name = movie[i].find('span',class_="title").string#获得影片名称
score = movie[i].find('span',class_="rating_num").string#获得影片评分
num = movie[i].find('div',class_="star").find_all('span')[-1].string.strip('人评价')#获得影片评价人数
quote = movie[i].find('span',class_="inq")#获得影片短评
.string和get_text()在本代码中显示结果一样(有些代码中返回显示也是不同的),但是返回类型不同
注意第4行获取评价人数时,span标签内无class和id等,只能先把div中所有的信息提取(返回结果是一位数组),人数在数组中最后一个,通过数组方法[-1]提取这个标签,通过string提取标签内内容,再用strip字符串方法去掉“人评价”这几个字
还有一点需要注意是,有几部影片是没有短评的(通过运行程序的结果才能看到,返回的是None),如果需要显示的更加人性化一些,添加以下语句:
if quote is None:
quote = "暂无"
else:
quote = quote.string
查找所有信息:不要想着把10页的html先拼接成一个html处理,这样的的html进行soup时只能提取到第一个<html>标签内的,也就是说只能查到第一页的信息。因此总体思路还是遍历每一页的电影信息,然后将结果拼接成数组。如果只是print出来或者逐行写入歧途文件的话无需整合所有影片
写入txt文件,提取出的结果是二维数组
#将数组movieData250写入文件txt
import codecs
s ="—————————豆瓣电影top250——————————\r\n"
f = codecs.open("豆瓣电影top250.txt",'w','utf-8')
f.write(s) for i in movieData250:
f.write(str(i)+'\r\n') #\r\n为换行符
f.close()
源代码:
#豆瓣电影前250信息,写入txt文件 from bs4 import BeautifulSoup as bs
from urllib import request
k = 0
n = 1
movieData250 = [] #读取每一个网页25个电影信息
def info25():
movieData = []
for i in range(0,25):
name = movie[i].find('span',class_="title").string#获得影片名称
score = movie[i].find('span',class_="rating_num").string#获得影片评分
num = movie[i].find('div',class_="star").find_all('span')[-1].string.strip('人评价')#获得影片评价人数
quote = movie[i].find('span',class_="inq")#获得影片短评
if quote is None:
quote = "暂无"
else:
quote = quote.string
#movieData[i] = [i+1,name,score,num,quote]
movieData.append([i+1+k,name,score,num,quote])
#print(movieData)
return movieData
#movieData250 = movieData250 + movieData while(k == 0):
h="https://movie.douban.com/top250"
resp = request.urlopen(h)
html_data = resp.read().decode('utf-8')
soup = bs(html_data,'lxml')
#print(soup.prettify())
#movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影
#movieList=soup.find('ol',class_="grid_view")#以下两种方法均可
movieList = soup.find('ol',attrs={'class':"grid_view"})
movie = movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
movieData250 +=info25()
k += 25 while(k<250): h = "https://movie.douban.com/top250?start=" + str(k) + "&filter="
resp=request.urlopen(h)
html_data=resp.read().decode('utf-8')
soup=bs(html_data,'lxml')
#print(soup.prettify())
#movieList=soup.find('ol')#寻找第一个ol标签,得到所有电影
#movieList=soup.find('ol',class_="grid_view")#以下两种方法均可
movieList=soup.find('ol',attrs={'class':"grid_view"})
movie=movieList.find_all('li')#获取每一个li(每个li是一个电影),以数组方式
movieData250 += info25()
k+=25 print(movieData250) #将数组movieData250写入文件txt
import codecs
s ="—————————豆瓣电影top250——————————\r\n"
f = codecs.open("豆瓣电影top250.txt",'w','utf-8')
f.write(s) for i in movieData250:
f.write(str(i)+'\r\n') #\r\n为换行符
f.close()
输出的txt:

显示结果不是很友好~~~
python3爬取豆瓣top250电影的更多相关文章
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- 爬取豆瓣TOP250电影
自己跟着视频学习的第一个爬虫小程序,里面有许多不太清楚的地方,不如怎么找到具体的电影名字的,那么多级关系,怎么以下就找到的是那个div呢? 诸如此类的,有许多,不过先做起来再说吧,后续再取去弄懂. i ...
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- 80 行代码爬取豆瓣 Top250 电影信息并导出到 CSV 及数据库
一.下载页面并处理 二.提取数据 观察该网站 html 结构 可知该页面下所有电影包含在 ol 标签下.每个 li 标签包含单个电影的内容. 使用 XPath 语句获取该 ol 标签 在 ol 标签中 ...
- 团队-爬取豆瓣Top250电影-团队-阶段互评
团队名称:咣咣踹电脑学号:2015035107217姓名:耿文浩 得分10 原因:组长带领的好,任务分配的好,积极帮助组员解决问题学号:2015035107213姓名:周鑫 得分8 原因:勇于分担,积 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
随机推荐
- NET Core项目部署
NET Core项目部署到linux(Centos7) 阅读目录 1.开篇说明 2.Jexus简单说明 3.Visual Studio 2015本地发布并且测试 4.配置Jexus并且部署.NET C ...
- LinkedList源码及原理
简介 内部结构分析 LinkedList源码分析 构造方法 添加(add)方法 根据位置取数据的方法 根据对象得到索引的方法 检查链表是否包含某对象的方法: 删除(remove/pop)方法 Link ...
- ruby 正则表达式 匹配中文
1.puts /[一-龥]+/.match("this is 中文") =>中文 2.str2="123中文"puts / ...
- 完整uploadify批量上传文件插件使用
1.首先准备uploadify的js文件,网上一搜一大堆 2.上传页面UpFilePage.aspx 关键代码: <html xmlns="http://www.w3.org/1999 ...
- 一个很好用的侧滑框架ICSDrawerController实现的 QQ 侧滑及换肤功能
使用ICSDrawerController 实现侧滑功能 在ICSDrawerController 第三方上做了修改实现,QQ 点击头像打开关抽屉头像渐变的效果 - (void)hiddenHeadV ...
- Linux mount实际使用
查看所有文件系统(设备):fdisk -l 1.当要重新挂载一个文件系统时(设备):可以直接 #mount -o remount,rw /dev/sdb9/(文件系统) /mnt/sdb9/(目录) ...
- python中的getcwd
Help on built-in function getcwd in module posix: getcwd(...) getcwd() -> path Return a ...
- 洛谷 P1784 数独
题目描述 数独是根据9×9盘面上的已知数字,推理出所有剩余空格的数字,并满足每一行.每一列.每一个粗线宫内的数字均含1-9,不重复.每一道合格的数独谜题都有且仅有唯一答案,推理方法也以此为基础,任何无 ...
- 【Python图像特征的音乐序列生成】第一阶段的任务分配
从即日起到7月20号,项目成员进行了第一次任务分配. 赵同学A.岳同学.周同学,负责了图像数据的情感数据集制作,他们根据自己的经验,对图像进行了情绪提取. 赵同学B全权负责向量映射这一块的网络搭建. ...
- UVA 177 PaperFolding 折纸痕 (分形,递归)
著名的折纸问题:给你一张很大的纸,对折以后再对折,再对折……每次对折都是从右往左折,因此在折了很多次以后,原先的大纸会变成一个窄窄的纸条.现在把这个纸条沿着折纸的痕迹打开,每次都只打开“一半”,即把每 ...