【scikit-learn】06:make_blobs聚类数据生成器
- 【scikit-learn】01:使用案例对sklearn库进行简单介绍
- 【scikit-learn】02:使用sklearn库进行统计学习
- 【scikit-learn】03:将sklearn库用于非监督性学习 聚类
- 【scikit-learn】04:sklearn库下进行文本数据分析
- 【scikit-learn】05:sklearn文本分类及评价指标
- 【scikit-learn】06:make_blobs聚类数据生成器
- 【scikit-learn】07:数据加载,数据归一,特征选择,逻辑回归,贝叶斯,k近邻,决策树,SVM
make_blobs聚类数据生成器简介
scikit中的make_blobs方法常被用来生成聚类算法的测试数据,直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
make_blobs方法:
sklearn.datasets.make_blobs(n_samples=100, n_features=2,centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)[source]其中:
- n_samples是待生成的样本的总数。
- n_features是每个样本的特征数。
- centers表示类别数。
- cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
例:生成3类数据用于聚类(100个样本,每个样本有2个特征)
from sklearn.datasets import make_blobs
from matplotlib import pyplot
data,target=make_blobs(n_samples=100,n_features=2,centers=3)
# 在2D图中绘制样本,每个样本颜色不同
pyplot.scatter(data[:,0],data[:,1],c=target);
pyplot.show()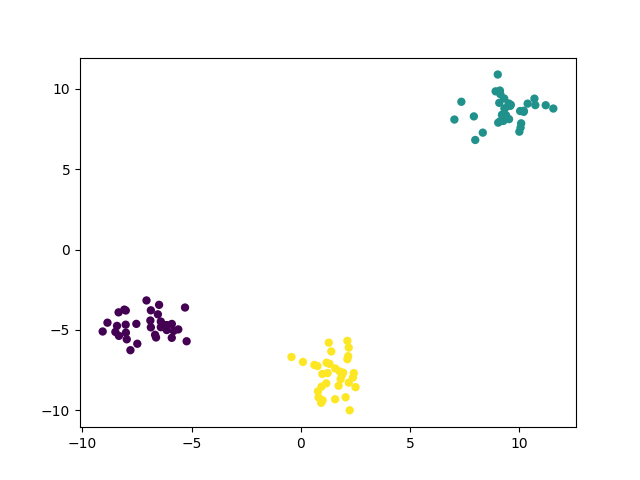
为每个类别设置不同的方差,只需要在上述代码中加入cluster_std参数即可:
from sklearn.datasets import make_blobs
from matplotlib import pyplot
data,target=make_blobs(n_samples=100,n_features=2,centers=3,cluster_std=[1.0,3.0,2.0])
#在2D图中绘制样本,每个样本颜色不同
pyplot.scatter(data[:,0],data[:,1],c=target);
pyplot.show()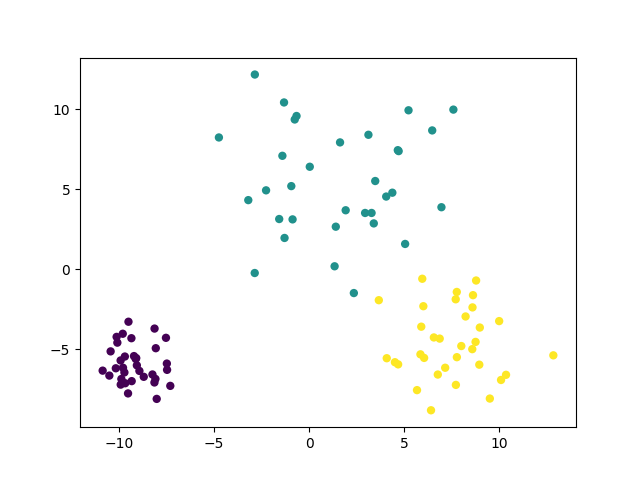
【scikit-learn】06:make_blobs聚类数据生成器的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Mockjs,模拟数据生成器
(推荐使用)Mock.js是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试. 提供了以下模拟功能: 1. 根据数据模板生成模拟数据. 2. 模拟Ajax请求,生成并返回模拟 ...
- [CF787D]遗产(Legacy)-线段树-优化Dijkstra(内含数据生成器)
Problem 遗产 题目大意 给出一个带权有向图,有三种操作: 1.u->v添加一条权值为w的边 2.区间[l,r]->v添加权值为w的边 3.v->区间[l,r]添加权值为w的边 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 【BZOJ3671】【NOI2014】随机数据生成器(贪心)
[BZOJ3671][NOI2014]随机数据生成器(贪心) 题面 BZOJ 题解 前面的模拟 真的就是语文阅读理解题目 理解清楚题目意思 然后就会发现要求的就是一个贪心 从小往大枚举,检查当前数能不 ...
- 【awesome-dotnet-core-learning】(3)-Bogus-假数据生成器
[awesome-dotnet-core-learning](3)-Bogus-假数据生成器 简介 Bogus一个简单而强大的假数据生成器,用于C#,F#和VB.NET.从著名的faker.js移植过 ...
- 让前端独立于后端进行开发,模拟数据生成器Mock.js
让前端独立于后端进行开发,模拟数据生成器Mock.jsMock.js 是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试. Home · nuysoft/Mock Wiki ...
随机推荐
- BLE 广播格式定义
低功耗蓝牙两类报文 : 广播报文 和 数据报文. 本文讨论广播报文数据段,不包括完整报文其他部分,比如前导,接入地址等 蓝牙设备通过广播表明自己的存在,等待被连接, 就好象一个人站在接口大喊“我要脱单 ...
- 由于找不到MSVCP140.dll,无法继续执行代码。重新安装程序可能会解决此问题。
msvcp140.dll文件下载,解决找不到msvcp140.dll的问题: 如果您的系统是64位的请将32位的dll文件复制到C:\Windows\System32目录 如果您的系统是64位的请将3 ...
- selenium按钮
学习使用selenium第一个坑,按钮type,submit,button driver.findElement(By.id("su")).submit() driver.find ...
- shell 数学运算
数学运算之 expr expr操作符对照表 比较大小,只能对整数进行比较,需要加空格,linux 保留关键字要转义 num1=30 num2=50 expr $num1 \> $num2 查看上 ...
- 【TestNG】使用代码方式调用TestNG用例执行
TestNG的用例除了直接运行之外,还可以使用代码来调用,这样做的好处在于我们可以将其嵌入其他代码中,来执行这些TestNG用例,方法如下: 1.直接调用用例类 范例:定义了两个测试用例类为Depen ...
- Scala 中 call by name & call by value 的区别
call by value:会先计算参数的值,然后再传递给被调用的函数 call by name:参数会到实际使用的时候才计算 定义方法 def return1():Int = { println(& ...
- Hadoop读写mysql
需求 两张表,一张click表记录某广告某一天的点击量,另一张total_click表记录某广告的总点击量 建表 CREATE TABLE `click` ( `id` ) NOT NULL AUTO ...
- 25道Shell面试题
1. 用sed修改test.txt的23行test为tset: sed –i ‘23s/test/tset/g’ test.txt 2. 查看/web.log第25行第三列的内容. sed –n ‘2 ...
- 跨域访问支持(Spring Boot、Nginx、浏览器)
原文:http://www.itmuch.com/work/cors/ 最近家中事多,好久没有写点啥了.一时间竟然不知从何说起.先说下最近家里发生的事情吧: 老爸肺气肿住院: 老妈甲状腺囊肿 儿子喘息 ...
- 请求类型 GET 和 POST 的区别
一.GET 一个简单的 GET 请求: xmlhttp.open("GET","demo_get.asp",true); xmlhttp.send(); 在上面 ...