【scikit-learn】06:make_blobs聚类数据生成器
- 【scikit-learn】01:使用案例对sklearn库进行简单介绍
- 【scikit-learn】02:使用sklearn库进行统计学习
- 【scikit-learn】03:将sklearn库用于非监督性学习 聚类
- 【scikit-learn】04:sklearn库下进行文本数据分析
- 【scikit-learn】05:sklearn文本分类及评价指标
- 【scikit-learn】06:make_blobs聚类数据生成器
- 【scikit-learn】07:数据加载,数据归一,特征选择,逻辑回归,贝叶斯,k近邻,决策树,SVM
make_blobs聚类数据生成器简介
scikit中的make_blobs方法常被用来生成聚类算法的测试数据,直观地说,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果。
make_blobs方法:
sklearn.datasets.make_blobs(n_samples=100, n_features=2,centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)[source]其中:
- n_samples是待生成的样本的总数。
- n_features是每个样本的特征数。
- centers表示类别数。
- cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
例:生成3类数据用于聚类(100个样本,每个样本有2个特征)
from sklearn.datasets import make_blobs
from matplotlib import pyplot
data,target=make_blobs(n_samples=100,n_features=2,centers=3)
# 在2D图中绘制样本,每个样本颜色不同
pyplot.scatter(data[:,0],data[:,1],c=target);
pyplot.show()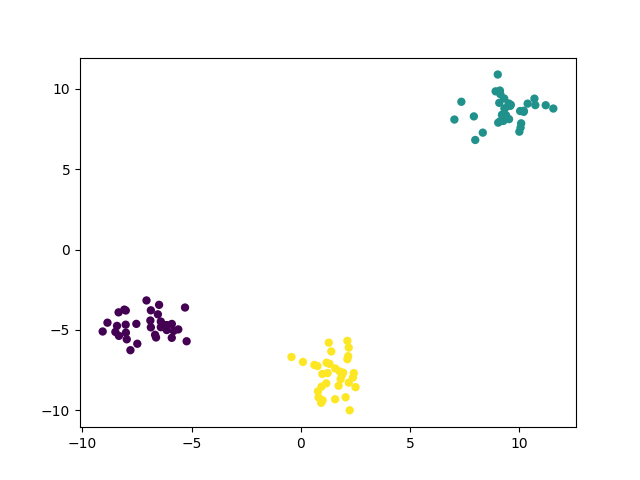
为每个类别设置不同的方差,只需要在上述代码中加入cluster_std参数即可:
from sklearn.datasets import make_blobs
from matplotlib import pyplot
data,target=make_blobs(n_samples=100,n_features=2,centers=3,cluster_std=[1.0,3.0,2.0])
#在2D图中绘制样本,每个样本颜色不同
pyplot.scatter(data[:,0],data[:,1],c=target);
pyplot.show()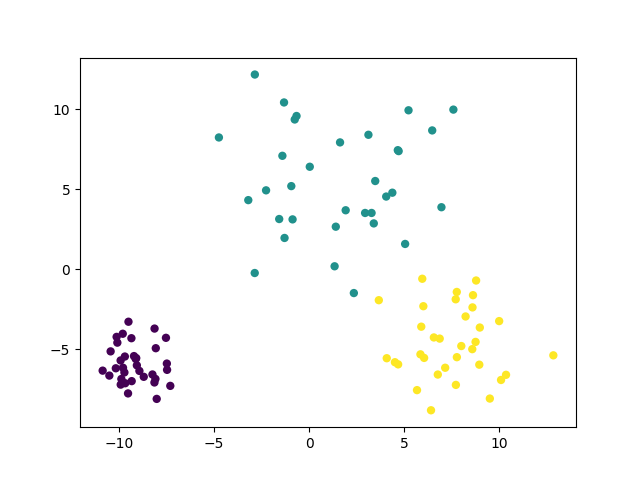
【scikit-learn】06:make_blobs聚类数据生成器的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Mockjs,模拟数据生成器
(推荐使用)Mock.js是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试. 提供了以下模拟功能: 1. 根据数据模板生成模拟数据. 2. 模拟Ajax请求,生成并返回模拟 ...
- [CF787D]遗产(Legacy)-线段树-优化Dijkstra(内含数据生成器)
Problem 遗产 题目大意 给出一个带权有向图,有三种操作: 1.u->v添加一条权值为w的边 2.区间[l,r]->v添加权值为w的边 3.v->区间[l,r]添加权值为w的边 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- 【BZOJ3671】【NOI2014】随机数据生成器(贪心)
[BZOJ3671][NOI2014]随机数据生成器(贪心) 题面 BZOJ 题解 前面的模拟 真的就是语文阅读理解题目 理解清楚题目意思 然后就会发现要求的就是一个贪心 从小往大枚举,检查当前数能不 ...
- 【awesome-dotnet-core-learning】(3)-Bogus-假数据生成器
[awesome-dotnet-core-learning](3)-Bogus-假数据生成器 简介 Bogus一个简单而强大的假数据生成器,用于C#,F#和VB.NET.从著名的faker.js移植过 ...
- 让前端独立于后端进行开发,模拟数据生成器Mock.js
让前端独立于后端进行开发,模拟数据生成器Mock.jsMock.js 是一款模拟数据生成器,旨在帮助前端攻城师独立于后端进行开发,帮助编写单元测试. Home · nuysoft/Mock Wiki ...
随机推荐
- java 原子操作(1) CAS
在 java 多线程编程中经常说的就是:“原子操作(atomic operation) 不需要 synchronized”. 原子操作指的是不会被线程调度机制打断的操作:这种操作一旦开始,就一直运行到 ...
- C#-MailHelper
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Vue框架之vuex的使用
1.首先需要在你的项目目录下安装vuex 终端命令: 2.在全局组件中导入与声明vuex 3.创建store实例对象 let store = new Vuex.store({ state:{ }, m ...
- linux reboot ,shutdown,halt区别
reboot ,shutdown,halt区别 重启 reboot 和 shutdown -r now 效果是一样的都是重启 区别在于reboot 是重启时,删除所有的进程,为不是平稳的终止他 ...
- TLS1.3 握手协议的分析
1.LTS支持的三种基本的密码交换模式 (EC)DHE (Diffie-Hellman both the finte field and ellptic curve varieties) PSK-on ...
- 【转】如何在TensorFlow中高效使用数据集
本文主要记录tensorflow一个比较好用的API:Dataset,feed-dict 是向 TensorFlow 传递信息最慢的方式,应该尽量避免使用.向模型提供数据的正确方式是使用输入管道,这样 ...
- python logging记录日志的方式
python的logging模块提供了标准的日志接口,可以通过它存储各种格式的日志,日志级别等级:critical > error > warning > info > deb ...
- 河南省acm第九届省赛--《表达式求值》--栈和后缀表达式的变形--手速题
表达式求值 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 假设表达式定义为:1. 一个十进制的正整数 X 是一个表达式.2. 如果 X 和 Y 是 表达式,则 X+Y, ...
- CentOS升级Openssl至openssl-1.1.0
1.查看原版本 wget http://www.openssl.org/source/openssl-1.1.0c.tar.gz openssl version 2.解压安装tar zxf opens ...
- flask 框架 转载:https://cloud.tencent.com/developer/article/1465949
1.cookie.py """ - 解释: 用来保持服务器和浏览器交互的状态的, 由服务器设置,存储在浏览器 - 作用: 用来做广告推送 - cookie的设置和获取 - ...