[译]如何使用Python构建指数平滑模型:Simple Exponential Smoothing, Holt, and Holt-Winters
原文连接:How to Build Exponential Smoothing Models Using Python: Simple Exponential Smoothing, Holt, and…
今年前12个月,iPhone XS将售出多少部?在埃隆·马斯克(Elon musk)在直播节目中吸食大麻之后,特斯拉的需求趋势是什么?这个冬天会暖和吗?(我住在加拿大。)如果你对这些问题感到好奇,指数平滑法可以通过建立模型来预测未来。
指数平滑方法为过去的观测分配指数递减的权重。得到的观测值越近,权重就越大。例如,与12个月前的观测结果相比,对上个月的观测结果给予更大的权重是合理的。

上图为指数平滑权值从过去到现在。
本文将说明如何使用Python和Statsmodel构建简单指数平滑、Holt和Holt- winters模型。对于每个模型,演示都按照以下方式组织。
模型操作方法+Python代码
Statsmodels是一个Python模块,它为实现许多不同的统计模型提供了类和函数。我们需要将它导入Python代码,如下所示。
import matplotlib.pyplot as plt
from statsmodels.tsa.holtwinters import ExponentialSmoothing, SimpleExpSmoothing, Holt
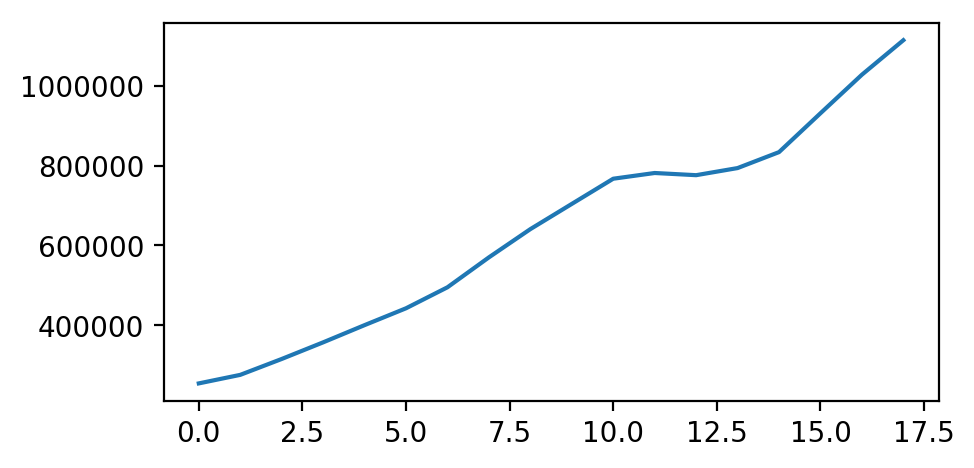
我们示例中的源数据如下:
data = [253993,275396.2,315229.5,356949.6,400158.2,442431.7,495102.9,570164.8,640993.1,704250.4,767455.4,781807.8,776332.3,794161.7,834177.7,931651.5,1028390,1114914]
我们可以先看看折线图
plt.plot(data);
简单指数平滑(SES)
对于没有明显趋势或季节规律的预测数据,SES是一个很好的选择。预测是使用加权平均来计算的,这意味着最大的权重与最近的观测值相关,而最小的权重与最远的观测值相关
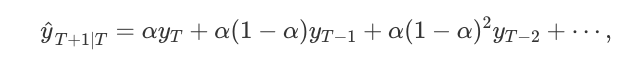
其中0≤α≤1是平滑参数。
权重减小率由平滑参数α控制。 如果α很大(即接近1),则对更近期的观察给予更多权重。 有两种极端情况:
- α= 0:所有未来值的预测等于历史数据的平均值(或“平均值”),称为平均值法。
- α= 1:简单地将所有预测设置为最后一次观测的值,统计中称为朴素方法。
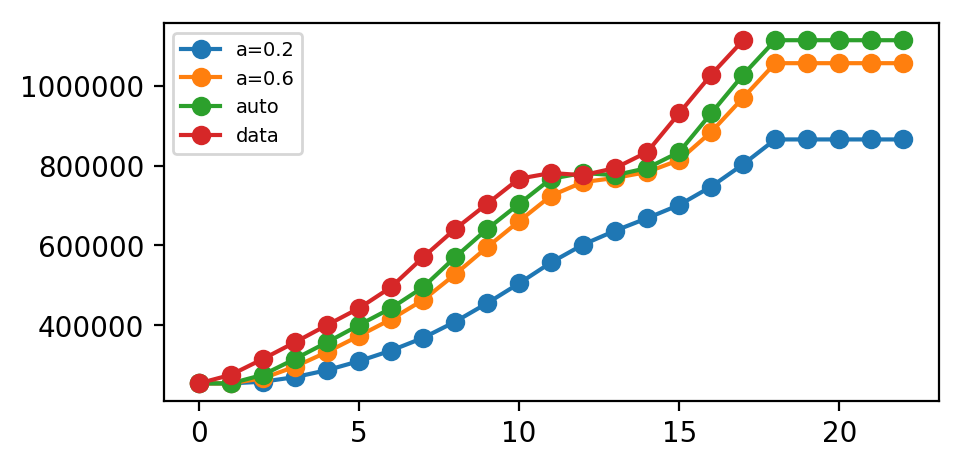
这里我们运行三种简单指数平滑变体:
- 在
fit1中,我们明确地为模型提供了平滑参数\(α= 0.2\) - 在
fit2中,我们选择\(α= 0.6\) - 在
fit3中,我们使用自动优化,允许statsmodels自动为我们找到优化值。 这是推荐的方法。
# Simple Exponential Smoothing
fit1 = SimpleExpSmoothing(data).fit(smoothing_level=0.2,optimized=False)
# plot
l1, = plt.plot(list(fit1.fittedvalues) + list(fit1.forecast(5)), marker='o')
fit2 = SimpleExpSmoothing(data).fit(smoothing_level=0.6,optimized=False)
# plot
l2, = plt.plot(list(fit2.fittedvalues) + list(fit2.forecast(5)), marker='o')
fit3 = SimpleExpSmoothing(data).fit()
# plot
l3, = plt.plot(list(fit3.fittedvalues) + list(fit3.forecast(5)), marker='o')
l4, = plt.plot(data, marker='o')
plt.legend(handles = [l1, l2, l3, l4], labels = ['a=0.2', 'a=0.6', 'auto', 'data'], loc = 'best', prop={'size': 7})
plt.show()
我们预测了未来五个点。
Holt's 方法(二次指数平滑)
Holt扩展了简单的指数平滑(数据解决方案没有明确的趋势或季节性),以便在1957年预测数据趋势.Holt的方法包括预测方程和两个平滑方程(一个用于水平,一个用于趋势):
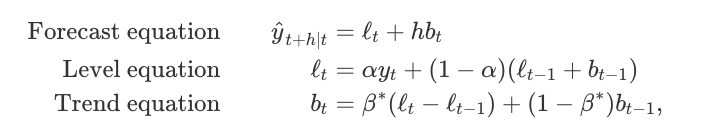
其中\(0≤α≤1\)是水平平滑参数,\(0≤β*≤1\)是趋势平滑参数。
对于长期预测,使用Holt方法的预测在未来会无限期地增加或减少。 在这种情况下,我们使用具有阻尼参数\(0 <φ<1\)的阻尼趋势方法来防止预测“失控”。
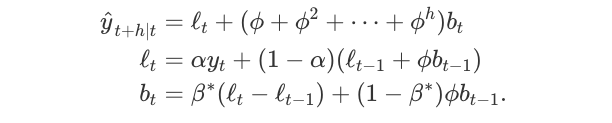
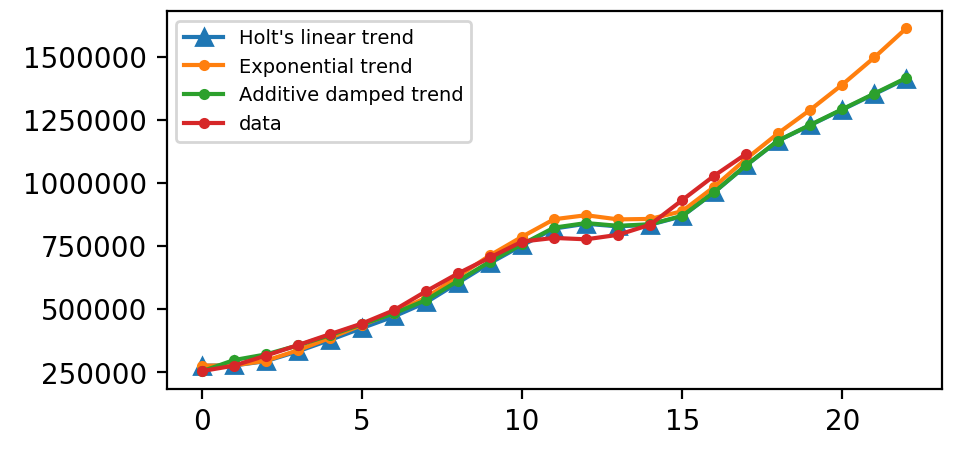
同样,这里我们运行Halt方法的三种变体:
- 在
fit1中,我们明确地为模型提供了平滑参数\(α= 0.8\),\(β* = 0.2\)。 - 在
fit2中,我们使用指数模型而不是Holt的加法模型(默认值)。 - 在
fit3中,我们使用阻尼版本的Holt附加模型,但允许优化阻尼参数\(φ\),同时固定\(α= 0.8\),\(β* = 0.2\)的值。
data_sr = pd.Series(data)
# Holt’s Method
fit1 = Holt(data_sr).fit(smoothing_level=0.8, smoothing_slope=0.2, optimized=False)
l1, = plt.plot(list(fit1.fittedvalues) + list(fit1.forecast(5)), marker='^')
fit2 = Holt(data_sr, exponential=True).fit(smoothing_level=0.8, smoothing_slope=0.2, optimized=False)
l2, = plt.plot(list(fit2.fittedvalues) + list(fit2.forecast(5)), marker='.')
fit3 = Holt(data_sr, damped=True).fit(smoothing_level=0.8, smoothing_slope=0.2)
l3, = plt.plot(list(fit3.fittedvalues) + list(fit3.forecast(5)), marker='.')
l4, = plt.plot(data_sr, marker='.')
plt.legend(handles = [l1, l2, l3, l4], labels = ["Holt's linear trend", "Exponential trend", "Additive damped trend", 'data'], loc = 'best', prop={'size': 7})
plt.show()
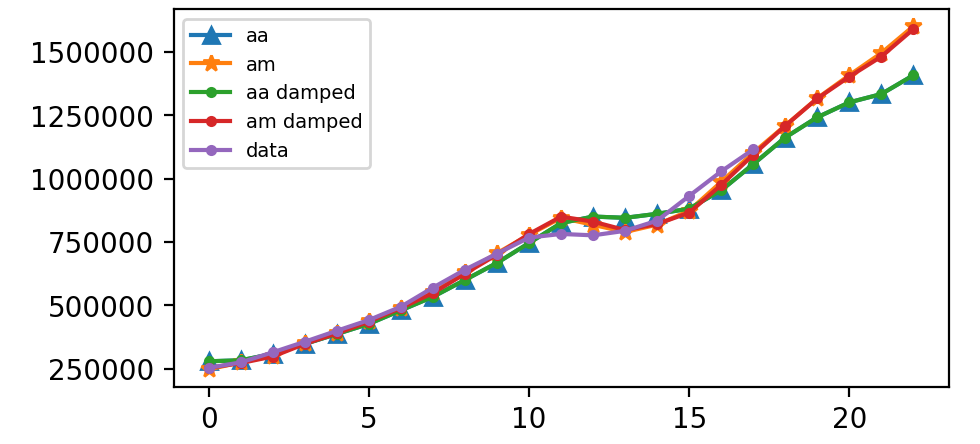
Holt-Winters 方法(三次指数平滑)
(彼得·温特斯(Peter Winters)是霍尔特(Holt)的学生。霍尔特-温特斯法最初是由彼得提出的,后来他们一起研究。多么美好而伟大的结合啊。就像柏拉图遇到苏格拉底一样。)
Holt-Winters的方法适用于具有趋势和季节性的数据,其包括季节性平滑参数\(γ\)。 此方法有两种变体:
- 加法方法:整个序列的季节变化基本保持不变。
- 乘法方法:季节变化与系列水平成比例变化。
在这里,我们运行完整的Holt-Winters方法,包括趋势组件和季节性组件。 Statsmodels允许所有组合,包括如下面的示例所示:
- 在
fit1中,我们使用加法趋势,周期season_length = 4的加性季节和Box-Cox变换。 - 在
fit2中,我们使用加法趋势,周期season_length = 4的乘法季节和Box-Cox变换。 - 在
fit3中,我们使用加性阻尼趋势,周期season_length = 4的加性季节和Box-Cox变换。 - 在
fit4中,我们使用加性阻尼趋势,周期season_length = 4的乘法季节和Box-Cox变换。
data_sr = pd.Series(data)
fit1 = ExponentialSmoothing(data_sr, seasonal_periods=4, trend='add', seasonal='add').fit(use_boxcox=True)
fit2 = ExponentialSmoothing(data_sr, seasonal_periods=4, trend='add', seasonal='mul').fit(use_boxcox=True)
fit3 = ExponentialSmoothing(data_sr, seasonal_periods=4, trend='add', seasonal='add', damped=True).fit(use_boxcox=True)
fit4 = ExponentialSmoothing(data_sr, seasonal_periods=4, trend='add', seasonal='mul', damped=True).fit(use_boxcox=True)
l1, = plt.plot(list(fit1.fittedvalues) + list(fit1.forecast(5)), marker='^')
l2, = plt.plot(list(fit2.fittedvalues) + list(fit2.forecast(5)), marker='*')
l3, = plt.plot(list(fit3.fittedvalues) + list(fit3.forecast(5)), marker='.')
l4, = plt.plot(list(fit4.fittedvalues) + list(fit4.forecast(5)), marker='.')
l5, = plt.plot(data, marker='.')
plt.legend(handles = [l1, l2, l3, l4, l5], labels = ["aa", "am", "aa damped", "am damped","data"], loc = 'best', prop={'size': 7})
plt.show()
总而言之,我们通过3个指数平滑模型的机制和python代码。 如下表所示,我提供了一种为数据集选择合适模型的方法。

总结了指数平滑方法中不同分量形式的平滑参数。

指数平滑是当今行业中应用最广泛、最成功的预测方法之一。如何预测零售额、游客数量、电力需求或收入增长?指数平滑是你需要展现未来的超能力之一。
[译]如何使用Python构建指数平滑模型:Simple Exponential Smoothing, Holt, and Holt-Winters的更多相关文章
- Holt Winter 指数平滑模型
1 指数平滑法 移动平均模型在解决时间序列问题上简单有效,但它们的计算比较难,因为不能通过之前的计算结果推算出加权移动平均值.此外,移动平均法不能很好的处理数据集边缘的数据变化,也不能应用于现有数据集 ...
- OpenAI的GPT-2:用Python构建世界上最先进的文本生成器的简单指南
介绍 "The world's best economies are directly linked to a culture of encouragement and positive f ...
- (转)利用Auto ARIMA构建高性能时间序列模型(附Python和R代码)
转自: 原文标题:Build High Performance Time Series Models using Auto ARIMA in Python and R 作者:AISHWARYA SI ...
- 使用OpenCV和Python构建自己的车辆检测模型
概述 你对智慧城市的想法感到兴奋吗?如果是的话,你会喜欢这个关于建立你自己的车辆检测系统的教程的 在深入实现部分之前,我们将首先了解如何检测视频中的移动目标 我们将使用OpenCV和Python构建自 ...
- 使用Boost.Python构建混合系统(译)
目录 Building Hybrid Systems with Boost.Python 摘要(Abstract) 介绍(Introduction) 设计目标 (Boost.Python Design ...
- Python中利用LSTM模型进行时间序列预测分析
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺 ...
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- python Django教程 之 模型(数据库)、自定义Field、数据表更改、QuerySet API
python Django教程 之 模型(数据库).自定义Field.数据表更改.QuerySet API 一.Django 模型(数据库) Django 模型是与数据库相关的,与数据库相关的代码 ...
- 构建Java并发模型框架
Java的多线程特性为构建高性能的应用提供了极大的方便,但是也带来了不少的麻烦.线程间同步.数据一致性等烦琐的问题需要细心的考虑,一不小心就会出现一些微妙的,难以调试的错误.另外,应用逻辑和线程逻辑纠 ...
随机推荐
- 洛谷P1169 棋盘制作【悬线法】【区间dp】
题目:https://www.luogu.org/problemnew/show/P1169 题意:n*m的黑白格子,找到面积最大的黑白相间的正方形和矩形. 思路:传说中的悬线法!用下面这张图说明一下 ...
- [ZJOI2009]假期的宿舍 二分图匹配匈牙利
[ZJOI2009]假期的宿舍 二分图匹配匈牙利 一个人对应一张床,每个人对床可能不止一种选择,可以猜出是二分图匹配. 床只能由本校的学生提供,而需要床的有住校并且本校和外校两种人.最后统计二分图匹配 ...
- 在Android中使用OpenGL ES开发第(四)节:相机预览
笔者之前写了三篇Android中使用OpenGL ES入门级的文章,从OpenGL ES的相关概念出发,分析了利用OpenGL ES实现3D绘图的重要的两个步骤:定义形状和绘制形状,简单的绘制了一个三 ...
- php使用ZipArchive提示Fatal error: Class ZipArchive not found in的解决方法
使用压缩包函数必须要安装zip扩展,否则会报错 $ apt install php-zip
- Python学习日记(二)——字符转编码操作
首先搞清楚:Python3的默认编码是unicode,Python2的默认编码是ASCII码 为什么需要编解码? 打个比方:假如说我做了一个游戏,叫<西游记>,游戏传到了日本去.但是日本人 ...
- WGAN实验环境搭建
"TensorFlow在Windows上支持Python 3.5.x和3.6.x." 因此,您无法在Windows上使用Python 2.7的tensorflow windows+ ...
- springboot实现异步调用
介绍 所谓的异步执行其实就是使用多线程的方式实现异步调用. 异步有什么好处呢? 如果一个业务逻辑执行完成需要多个步骤,也就是调用多个方法去执行, 这个时候异步执行比同步执行相应更快.不过要注意异步请求 ...
- Java的Lambda表达式
Java的Lambda表达式 1. 什么是Lambda表达式 简单的说,Lambda表达式就是匿名方法.Lambda表达式让程序员能够使用更加简洁的代码,但是同样也使代码的可读性比较差. Lambda ...
- Flutter设置Container的最大最小宽高
Flutter中设置Container宽高可直接通过width和height属性来设置:如下 Container( width: 100, height: 100, color: Colors.red ...
- 官网引用的axios,lodash文件在脚手架中如何使用?
对于官网属性与侦听器模块,所引用的以下文件在脚手架中如何使用? <script src="https://cdn.jsdelivr.net/npm/axios@0.12.0/dist/ ...