NLP传统基础(1)---BM25算法---计算文档和query相关性
一、简介:TF-IDF 的改进算法
https://blog.csdn.net/weixin_41090915/article/details/79053584
bm25 是一种用来评价搜索词和文档之间相关性的算法。通俗地说:主要就是计算一个query里面所有词q和文档的相关度,然后再把分数做累加操作。
我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词qi,然后单词的分数由3部分组成:
- 单词qi和D之间的相关性
- 单词qj和query之间的相关性
- 每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。

二、优缺点
适用于:在文档包含查询词的情况下,或者说查询词精确命中文档的前提下,如何计算相似度,如何对内容进行排序。不适用于:基于传统检索模型的方法会存在一个固有缺陷,就是检索模型只能处理 Query 与 Document 有重合词的情况,传统检索模型无法处理词语的语义相关性。
白话举例:提出一个query:当下最火的女网红是谁?
在Document集合中document1的内容为:[当下最火的男明星为鹿晗];
document2的内容为:[女网红能火的只是一小部分]。
显然document1和document2中都包含[火]、[当下]、[网红]等词语。
但是document3的内容可能是:[如今最众所周知的网络女主播是周二柯]。
很显然与当前Query能最好匹配的应该是document3,可是document3中却没有一个词是与query中的词相同的(即上文所说的没有“精确命中”),此时就无法应用BM25检索模型。
三、算法核心:
https://blog.csdn.net/weixin_41090915/article/details/79053584
四、传统TF-IDF vs. BM25
传统的TF-IDF是自然语言搜索的一个基础理论,它符合信息论中的熵的计算原理,虽然作者在刚提出它时并不知道与信息熵有什么关系,但你观察IDF公式会发现,它与熵的公式是类似的。实际上IDF就是一个特定条件下关键词概率分布的交叉熵。
BM25在传统TF-IDF的基础上增加了几个可调节的参数,使得它在应用上更佳灵活和强大,具有较高的实用性。
BM25中的TF
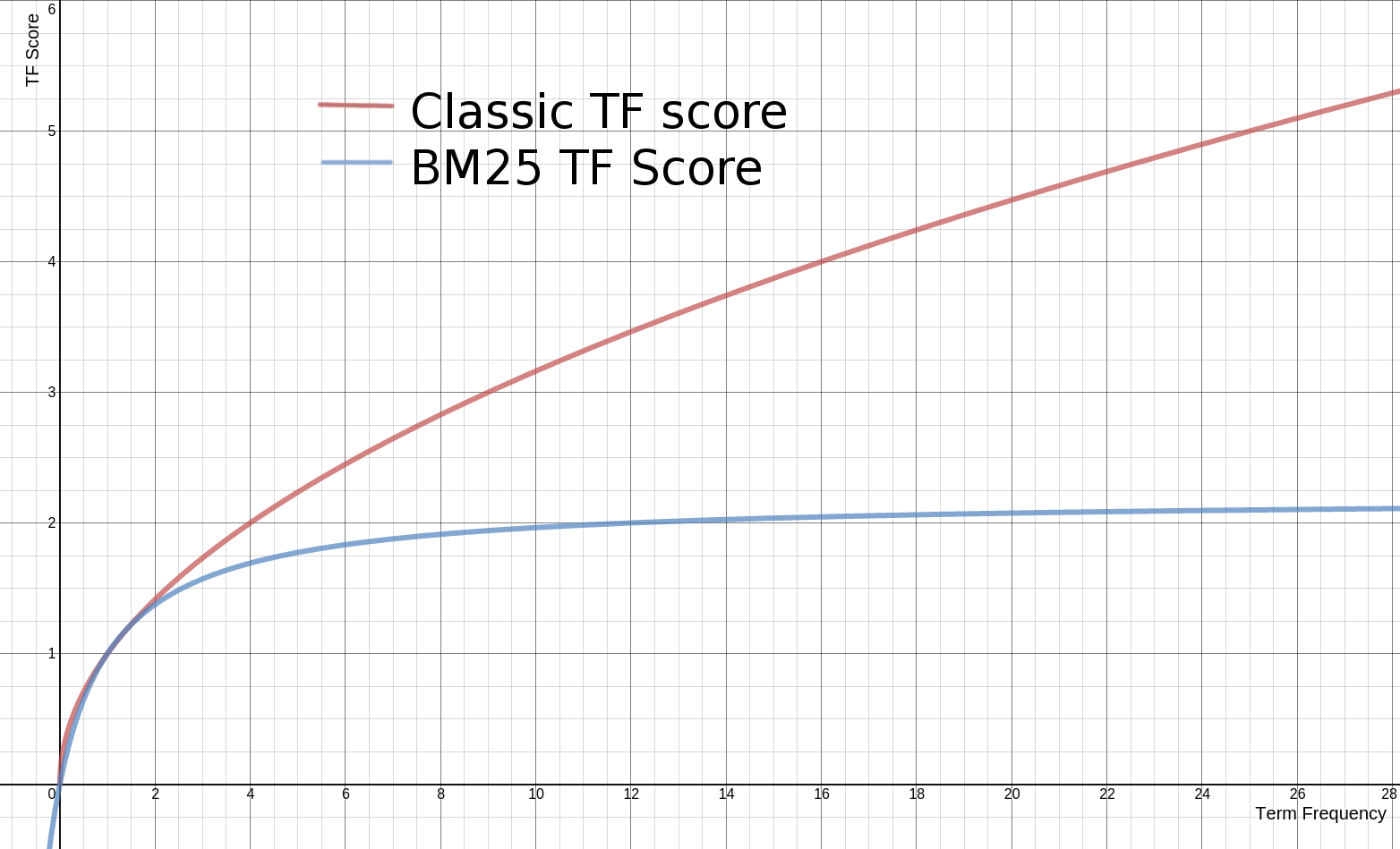
传统的TF值理论上是可以无限大的。而BM25与之不同,它在TF计算方法中增加了一个常量k,用来限制TF值的增长极限。下面是两者的公式:
传统 TF Score = sqrt(tf)
BM25的 TF Score = ((k + 1) * tf) / (k + tf)
下面是两种计算方法中,词频对TF Score影响的走势图。从图中可以看到,当tf增加时,TF Score跟着增加,但是BM25的TF Score会被限制在0~k+1之间。它可以无限逼近k+1,但永远无法触达它。这在业务上可以理解为某一个因素的影响强度不能是无限的,而是有个最大值,这也符合我们对文本相关性逻辑的理解。 在Lucence的默认设置里,k=1.2,使用者可以修改它。
NLP传统基础(1)---BM25算法---计算文档和query相关性的更多相关文章
- python 分词计算文档TF-IDF值并排序
文章来自于我的个人博客:python 分词计算文档TF-IDF值并排序 该程序实现的功能是:首先读取一些文档,然后通过jieba来分词,将分词存入文件,然后通过sklearn计算每一个分词文档中的tf ...
- Java-2-学习历程2:基础知识1,2,3文档、完整版视频资源、电子书籍下载
Java学习历程:基础知识1,2,3文档.完整版视频资源.电子书籍 1.基础知识1,2.3可到下面地址下载: http://download.csdn.net/detail/iot_li/886 ...
- NLP传统基础(2)---LDA主题模型---学习文档主题的概率分布(文本分类/聚类)
一.简介 https://cloud.tencent.com/developer/article/1058777 1.LDA是一种主题模型 作用:可以将每篇文档的主题以概率分布的形式给出[给定一篇文档 ...
- NLP传统基础(3)---潜在语义分析LSA主题模型---SVD得到降维矩阵
https://www.jianshu.com/p/9fe0a7004560 一.简单介绍 LSA和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(d ...
- CSS 基础:HTML 标记与文档结构(1)<思维导图>
这段时间利用一下间隙时间学习了CSS的基础知识,主要目的是加深对CSS的理解,虽然个人主要工作基本都是后台开发,但是个人觉得系统学习一下CSS的基础还是很有必要的.下面我学习CSS时做的思维导图(全屏 ...
- 前端基础-CSS如何布局以及文档流
一. 网页布局方式 二. 标准流 三. 浮动流 四. 定位流 一. 网页布局方式 1.什么是网页布局方式 布局可以理解为排版,我们所熟知的文本编辑类工具都有自己的排版方式, 比如word,nodpad ...
- Spring Boot 2.x基础教程:Swagger静态文档的生成
前言 通过之前的两篇关于Swagger入门以及具体使用细节的介绍之后,我们已经能够轻松地为Spring MVC的Web项目自动构建出API文档了.如果您还不熟悉这块,可以先阅读: Spring Boo ...
- Objective-C ,ios,iphone开发基础:使用GDataXML解析XML文档,(libxml/tree.h not found 错误解决方案)
使用GDataXML解析XML文档 在IOS平台上进行XML文档的解析有很多种方法,在SDK里面有自带的解析方法,但是大多情况下都倾向于用第三方的库,原因是解析效率更高.使用上更方便 这里主要介绍一下 ...
- java Web开发基础(一)工程项目文档结构
2013年毕业后,在深圳工作开始是用.NET ASP.NET MVC做的项目,后来公司用java来做.于是就从.NET转java了.从.NET转java不是那么的难.今天刚好是清明节放假三天,整理了j ...
随机推荐
- 涨停复盘:5G概念持续活跃,军工股强势崛起
午后银行股快速拉升,三大股指大幅拉升,沪指一度临近2800点,但未能持续随后沪指小幅下行,题材股表现强势,证券板块高开低走.截止收盘,沪指涨0.93%,创业板指涨1.51%. 盘面上,银行板块午后拉升 ...
- sql语句中,取得schema中的所有表信息及表的定义结构
postgressql下'検索スキーマの中で.全てテーブルselect tablename from pg_tables where schemaname='test' mysql下'検索スキーマの中 ...
- FAQ and discussed with adam
1. About permuter index. url: https://www.youtube.com/watch?v=j789k96g5aQ&list=PL0ZVw5-GryEkGAQ ...
- 《Mysql - 我的Mysql为什么会抖一下?》
一: 抖一下? - 平时的工作中,不知道有没有遇到过这样的场景. - 一条 SQL 语句,正常执行的时候特别快,但是有时也不知道怎么回事,它就会变得特别慢. - 并且这样的场景很难复现,它不只随机,而 ...
- vue图片点击放大功能
因项目需求(ui框架element-ui),需要实现图片的点击放大,还要能旋转以及上下切换.当时第一反应,element-ui好像没有这样的组件,就想过自己写,但是那个旋转翻页上下切换感觉有点麻烦,不 ...
- 2019php面试大全
一 .PHP基础部分 1.PHP语言的一大优势是跨平台,什么是跨平台? PHP的运行环境最优搭配为Apache+MySQL+PHP,此运行环境可以在不同操作系统(例如windows.Linux等)上配 ...
- 使用网关zuul过滤器登录鉴权
使用网关zuul过滤器登录鉴权 1.新建一个filter包 filte有很多种 pre.post. 2.新建一个类LoginFilter,实现ZuulFilter,重写 ...
- 记录学习Python的第一天
这是我的第一篇博客,也是我学Python的第一天. 写这篇博客主要目的是为了记下我学习Python的过程以及所学到的知识点.我所学的是Python3版本,我所学的内容有如下几点: 1.python3中 ...
- SAS学习笔记35 options语句
- PHP对程序员的要求更高
我这个文章标题可不是和大家开玩笑的哦 首先, 大家都知道, PHP也是一种编译型脚本语言, 和其他的预编译型语言不同, 它不是编译成中间代码, 然后发布.. 而是每次运行都需要编译.. 为此, 也 ...