python笔记2小数据池,深浅copy,文件操作及函数初级
小数据池就是在内存中已经开辟了一些特定的数据,经一些变量名直接指向这个内存,多个变量间公用一个内存的数据.
int: -5 ~ 256 范围之内
str: 满足一定得规则的字符串. 小数据池:
1,节省空间。
2,提高性能
深浅copy
赋值运算
l1 = ['wk', 'xixi', 'lol', 'xyq', [, , ]]
l2 = l1 #l2就是l1 l1是什么,l2就是什么
l1.append('qqfc')
l1[-].append('heihei')
print(l1)
print(l2) ['wk', 'xixi', 'lol', 'xyq', [, , , 'heihei'], 'qqfc']
['wk', 'xixi', 'lol', 'xyq', [, , , 'heihei'], 'qqfc']
浅copy
浅copy 第一层开辟的新的内存地址,但是从第二层乃至更深的层来说,公用的都是一个。 copy()
l1 = ['wk', 'xixi', 'lol', 'xyq', [, , ]]
l2 = l1.copy() #浅拷贝
l1.append('qqfc') #在l1第一层结尾追加qqcc
l1[-].append('heihei') #在l1第二层追加heihei
print(l1)
print(l2) ['wk', 'xixi', 'lol', 'xyq', [, , , 'heihei'], 'qqfc']
['wk', 'xixi', 'lol', 'xyq', [, , , 'heihei']] #结果第一层copy为新开辟的独立的内存空间,l1的追加在l2里没有,在第二层里是公用的,l1的追加l2里也有
深copy
深copy:复制两个完全独立的数据(多少层都是独立的) 使用深copy的引用copy模块.copy.deepcopy()
import copy #引用copy模块
l1 = ['wk', 'xixi', 'lol', 'xyq', [1, 2, 3]]
l2 = copy.deepcopy(l1) #深copy
l1.append('qqfc')
l1[-2].append('heihei')
print(l1)
print(l2) ['wk', 'xixi', 'lol', 'xyq', [1, 2, 3, 'heihei'], 'qqfc']
['wk', 'xixi', 'lol', 'xyq', [1, 2, 3]] #不管多少层发生改变,其l2都是独立的内存地址,内容不会发生变化
文件操作
open()内置函数,操作文件
f1文件句柄.f1,fh,file_handle,f....
f1 = open(r'C:\Users\22490\Desktop\新建文本文档 (9).txt', encoding='utf-8', mode='r') #打开文件产生句柄,对文件句柄进行相应的操作(读,写,追加,读写....)。
print(f1.read())
f1.close() #关闭文件句柄
导致文件错误的原因:
1.文件路径过长 导致路径有些字符有特殊意义, 解决方法:路径前+r转译
2.\UXXXXXXXX escape; decodeincodeerror 错误 为文件编码的不一致 解决: encoding='utf-8'
读 (r r+ rb r+b )
r {read(), read(n), readline(), readlines(), for循环}
f1 = open('文件', encoding='utf-8',)
print(f1.read()) #全读出来只针对一些小文件文件太大会撑爆内存
f1.close()
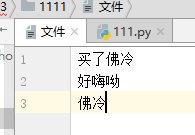
买了佛冷
好嗨呦
佛冷
f1 = open('文件', encoding='utf-8',)
print(f1.read(2)) #r模式安字符读取
f1.close()
买了
f1 = open('文件', encoding='utf-8',)
print(f1.readline()) #按行度 多个readline读多行,从上往下依次读但是每行结尾都有换行符
print(f1.readline())
f1.close()
买了佛冷
好嗨呦
f1 = open('文件', encoding='utf-8',)
print(f1.readline().strip()) #结尾加上.strip()取消换行符
print(f1.readline().strip())
print(f1.readline().strip())
f1.close()
买了佛冷
好嗨呦
佛冷
f1 = open('文件', encoding='utf-8',)
print(f1.readlines()) #返回一个列表,刘表中的每个元素为源文件的一行
f1.close()
'买了佛冷\n', '好嗨呦\n', '佛冷']
最常用for循环文件句柄读所有
f1 = open('文件', encoding='utf-8',)
for line in f1:
print(line.strip())
f1.close()
买了佛冷
好嗨呦
佛冷
readable()判断文件是否可读
f1 = open('文件4', encoding='utf-8', mode='w')
print(f1.readable()) #mode为写入文件,因此readable判断为false
False
rb
f1 = open('有点大.jpg',mode='rb')
print(f1.read())
f1.close()
\xcb\xf0FT\x90\xac{\x90\x0f\xb6}>\xb8\xcds\x17W\xa5\x86\x01\\\
xb6\xed\xdf?@\xbdO\x07\x93\xcf\xf4\x15\x81\x7f\xac\xa9p\xb1H\x08\x1c\xb\xe3\xb5
\x13\x1f\xedg\r\x9cc\xf5\xe9X\xcd~\xf2\xb3(%\x97\x04\xf4\xe0\xe7\xae\xd6\x03\x9e?\n\x
97.]\xef\xafn\x9bz\x1a\xc6\r-5\xf3\xdb\xfa\xff\x00\x87
r+
r+就是先读后写,写入为追加写入,写入的内容必须是字符串
#如果先写后读则会是按字符串覆盖写入
f1 = open('文件4', encoding='utf-8', mode='r+')
print(f1.read()) #先读
f1.write('\n1111111') #后写
f1.close()
写 (w wb w+)
w
没有文件创建文件写入
有文件先清空文件,后写入文件
f1 = open('文件2', encoding='utf-8',mode='w')
f1.write('eve')
f1.close()
writable()判断是否可写
f1 = open('文件4', encoding='utf-8', mode='r')
print(f1.writable()) #判断文件是否可写入
False
.wb
用于下载非文字的文件(图片视频等)
f1 = open('有点大.jpg',mode='rb') #先以rb的模式打开读取一个文件
f2 = open('文件3.jpg', mode='wb') #再以wb的模式打开写入一个文件
f2.write(f1.read()) #将读取的f1的内容写入到f2
f1.close() #关闭f1
f2.close() #关闭f2
追加(a + ab a+b)
a
1.没有文件创建文件写入内容
2.有文件直接在后边追加(不换行)
f1 = open('文件4',mode='a')
f1.write('hehe')
f1.close()
换行追加 在加入内容前加上换行符 \n
文件光标的操作
tell()查看文件光标所在位置(按字节)
f1 = open('文件4', encoding='utf-8', mode='r')
print(f1.read(3)) #读取3字节文件
print(f1.tell()) #查看光标所在位置
f1.close()
xix
3 #光标在第三字节
seek()调整光标的位置(按字节)
f1 = open('文件4', encoding='utf-8', mode='r')
f1.seek(20) #光标调整至第20字节,从第20字节开始读取
print(f1.read())
with open('', mode='r', encoding='utf-8') as f:
print(f.read())
f.seek(0, 0) #等于f.seek(0) 表示光标移动至开头
f.seek(0, 1) #光标当前位置
f.seek(0, 2) #光标移动至末尾
truncate() 清空文件内容
f1 = open('文件4', encoding='utf-8', mode='r')
f1.truncate()
with open
打开文件运行完操作后自动关闭文件,不需要再用close()函数
with open('', mode='r+',encoding='utf-8') as f:
print(f.read())
f.write("\nxixi")
文件改的操作
word wps 记事本,nodpad++ ....
1,以读的模式打开原文件
2,以写的模式打开一个新文件
3,对原文件的内容进行修改,形成新内容写入新文件
4,删除原文件
5,将新文件重命名为原文件。
将文件里的佛改为神
import os #调用os模块修改系统的文件
with open('文件', encoding='utf-8', mode='r') as f1, \ #打开读取文件
open('文件2',encoding='utf-8', mode='w') as f2: #打开写入文件2
for i in f1: #for循环每行文件赋值i
new = i.replace('佛','神') #通过replace()修改字符串方法将每行的佛改为神
f2.write(new) #将修改后的内容写入到文件2中
os.remove('文件') #删除原文件
os.rename('文件2','文件') #修改文件2名字为文件
函数初识
一个函数封装一个功能
def xixi(): #def 函数名():
print("") #函数图
xixi() #调用函数 1433223
return
1.在函数中,遇到return终止函数.
2.返回值返回给函数的调用者
1.return 返回的是none
2.return 单个值 返回单个值
3.return 多个值 返回多个值组成的元组
s1 = ''
def aaa(s1):
c=0
for i in s1:
c += 1
return c #将c的只返回给函数aaa
print(aaa(s1)) #打印函数aaa则打印c的值 12
函数的传参(实参和形参)
实参角度:
位置参数;从前至后,一一对应
def xixi(x,y,z): #定义3个位置参数
c = x + y +z
return c
print(xixi(1,2,3)) #传入3个位置参数 6
三元运算(if,else的简单优化)
def aa(a,b):
return = a if a > b else b #三元运算 复制de 如果a>b返回a 否者返回b
print(aa(3,4)) 4
关键字传参:
def aa(fo,ma):
print('%s%s' % (ma, fo)) aa(ma='买了',fo='佛冷') #关键字传参 买了佛冷
混合传参(位置参数在前,关键字参数在后)
def aa(a,b,c):
print(a,b,c) aa("你是","不是",c="傻呀") #位置参数在前,关键字参数在后 你是 不是 傻呀
形参角度:
位置传参
和实参一致
def aa(a,b,c):
print(a,b,c)
aa("你是","不是","傻呀") 你是 不是 傻呀
默认参数
def aa(a='你是不是傻呀'): #已经写过的参数,如果不传参默认用
print(a)
aa()
aa('不是')
你是不是傻呀
部署
制作班级统计表:
def aaa(a, b, xb='男'):
with open('文件6', encoding='utf-8', mode='a') as banji:
banji.write('姓名:%s年龄:%s性别:%s \n'% (a,b,xb))
banji.close() while True:
name = input('请输入名字或退出:')
if name == 'q':
break
nian = input('请输入年龄:')
if name.startswith(''):
aaa(name,nian)
else:
xb = input('请输出性别:')
aaa(name,nian,xb)
万能参数
*args和 **kwargs (前边的*和**为聚合和打散的作用)
l1 = ['kjkj','kjkjk','hghg','sadsa','qwew','qe',21,12,121,2,12,1,21]
l2 = {'weq':'eqweqw','CCC':'QWWQ'}
def aaa(*args,**kwargs): #将传入的的参数聚合给args和kwargs
print(args)
print(kwargs)
aaa(*l1,**l2) #将l1和l2打散为多个参数传入到函数内
('kjkj', 'kjkjk', 'hghg', 'sadsa', 'qwew', 'qe', 21, 12, 121, 2, 12, 1, 21)
{'weq': 'eqweqw', 'CCC': 'QWWQ'}
函数参数位置顺序
def func(a,b,*args,sec='嘻嘻',**kwargs) 位置参数 *args 默认参数 **kwargs
python的名称空间
全局名称空间:存储的是全局(py文件)的变量与值的对应关系
临时(局部)名称空间:当函数执行时,会在内存中临时开辟一个空间,此空间记录函数中的变量与值的对应关系,随着函数的结束,临时名称空间而关闭。
内置名称空间: len print 等内置函数等等。
作用域:
全局作用域: 内置名称空间 全局名称空间
局部作用域:临时(局部)名称空间
加载顺序: 内置名称空间 ---> 全局名称空间 ---> 函数执行时:临时(局部)名称空间
取值顺序: 函数执行时:临时(局部)名称空间 ---> 全局名称空间 ----> 内置名称空间(取值顺序满足就近原则)
global nonlocal #2.7版本的python没有nonlocal
global
1可以修改全局变量
2在局部空间可以声明一个全局变量
1.局部只能引用全局的变量但是不能修改,修改就会报错
a =
def fun():
a += 1 #内部改变外部变量 会报错
print(a)
fun()
如果想在函数内修改全局变量,需要global引用变量
a =
def fun():
global a #在函数内引用了全局变量
a += 1
print(a)
fun()
2.在局部空间声明变量不能在全局调用
def fun():
a = 1
fun()
print(a) #在局部的变量全局引用不出来
如果想要在全局调用,需要用global声明
def fun():
global a
a = 1
fun()
print(a)
nonlocal
1.不能操作全局变量
2,在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的哪层,从那层及以下此变量全部发生改变。
子名称空间不能修改父名称空间的变量
def fun():
a = 1
def innaer():
a += 1 #无法修改
print(a)
innaer()
fun()
用nonlocal可以修改
def fun():
a = 1
def innaer():
nonlocal a #引用nonlocal可以修改
a += 1
print(a)
innaer()
fun()
函数名的运用
函数名(函数的内存地址) 变量
函数名可以作为函数的参数
def func1():
print(111) def func2(x): #将func1作为参数传入func2调用func1
print(x)
x()
func2(func1)
函数名可以作为函数的返回值
def fun():
print(111) def fun2(x):
return x
fun2(fun)() #将fun作为参数传入fun2,fun2返回值为参数即fun,所以fun2(fun)=fun,fun2(fun)()=fun() 111
函数名可以作为容器类数据类型的参数
def fun():
print(111)
def fun2():
print(222)
def fun3():
print(333) l1 = [fun, fun2, fun3] #将函数名作为列表的值
for i in l1:
i() #列表调用函数 111
222
333
def fun():
print(111)
def fun2():
print(222)
def fun3():
print(333)
dic = {
1:fun,
2:fun2,
3:fun3,
}
while 1:
zhi = int(input('请输入要调用函数的序号:')) #字典根据key取函数名调用函数(key是int类型)
dic[zhi]()
内置函数max和min用于取出列表或元组的最大值和最小值
a = (12, 35, 6, 3, 234, 3435, 324)
print(max(a))
print(min(a)) 3435
3
python笔记2小数据池,深浅copy,文件操作及函数初级的更多相关文章
- python 小数据池 深浅拷贝 集合
1.小数据池: 1.1代码块: 一个文件,一个函数,一个类,一个模块,终端中每一行 1.1.1 数字: -5 ~ 256 1.1.2 字符串: 乘法时总长度不能超过20 1.1.3 布尔值: 内容相同 ...
- 百万年薪python之路 -- 小数据池和代码块
1.小数据池和代码块 # 小数据池 -- 缓存机制(驻留机制) # == 判断两边内容是否相等 # a = 10 # b = 10 # print(a == b) # is 是 # a = 10 # ...
- python基础之小数据池、代码块、编码和字节之间换算
一.代码块.if True: print(333) print(666) while 1: a = 1 b = 2 print(a+b) for i in '12324354': print(i) 虽 ...
- python基础之小数据池
一,id,is,== 在Python中,id是什么?id是内存地址,比如你利用id()内置函数去查询一个数据的内存地址: name = '太白' print(id(name)) # 158583128 ...
- python 浅谈小数据池和编码
⼀. ⼩数据池 在说⼩数据池之前. 我们先看⼀个概念. 什么是代码块: 根据提示我们从官⽅⽂档找到了这样的说法: A Python program is constructed from code b ...
- python基础之小数据池,is和==区别 编码问题
主要内容 小数据池,is和==区别 编码问题 小数据池 一种缓存机制,也称为驻留机制,是为了能更快提高一些字符串和整数的处理速度is 和 == 的区别 == 主要指对变量值是否相等的判断,只要数值相同 ...
- python中的 小数据池 is 和 ==
1. 小数据池 一种数据缓存机制,也被称为驻留机制 小数据池针对的是:整数 , 字符 , 布尔值 .其他的数据类型不存在驻留机制 在python中对 -5 到256之间的整数会被驻留在内存中, 将一定 ...
- python编码和小数据池
python_day_6 一. 回顾上周所有内容一. python基础 Python是一门解释型. 弱类型语言 print("内容", "内容", end=&q ...
- python基础之小数据池、代码块、编码
一.代码块.if True: print(333) print(666) while 1: a = 1 b = 2 print(a+b) for i in '12324354': print(i) 虽 ...
随机推荐
- 阿里高级架构师教你使用Spring Cloud Sleuth跟踪微服务
随着微服务数量不断增长,需要跟踪一个请求从一个微服务到下一个微服务的传播过程,Spring Cloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能 ...
- MySQL主从复制以及在本地环境搭建
MySQL主从复制原理: master(主服务器),slave(从服务器) MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事binary log ...
- rt-thread下调试elmfat 问题记录
硬件平台:stm32f107 SPI flash:w25q32 RTT版本:v2.1 w25q32的驱动大神们已经写好(w25qxx.c),我只需要照猫画虎的实现相应SPI的驱动程序即可(bsp例 ...
- linux基础--命令使用
rpm命令 rpm -qa 包 查看包是否安装 rpm qa 列出系统安装的所有包 rpm -ql 包 查看软件包安装的位置及配置的目录 rpm -ivh 包 安装rpm包或强制安装包 rpm -Uv ...
- mxnet在windows使用gpu 出错
1. cuda windows安装 官网下载 代码: import mxnet as mxfrom mxnet import ndfrom mxnet.gluon import nn a = nd.a ...
- Java常用数学类和BigDecimal
笔记: Math类 * java.lang.Math提供了一系列静态方法用于科学计算:其方法的参数和返回值类型一般为double型. * abs 绝对值 * acos,asin,atan,cos,si ...
- 1. jenkins常见错误及解决方法
1. Jenkins一直卡在启动页面 需要你进入jenkins的工作目录, 打开 hudson.model.UpdateCenter.xml 把 http://updates.jenkins-ci.o ...
- TreadPool
ThreadPool概述 提供一个线程池,该线程池可用于执行任务.发送工作项.处理异步 I/O.代表其他线程等待以及处理计时器. 创建线程需要时间.如果有不同的小任务要完成,就可以事先创建许多线程/在 ...
- 快捷键IntelliJ IDEA For Mac
http://www.cnblogs.com/wxd0108/p/5295017.html Mac键盘符号和修饰键说明 ⌘ Command ⇧ Shift ⌥ Option ⌃ Control ↩︎ ...
- BZOJ 1778: [Usaco2010 Hol]Dotp 驱逐猪猡 (高斯消元)
题面 题目传送门 分析 令爆炸概率为PPP.设 f(i)=∑k=0∞pk(i)\large f(i)=\sum_{k=0}^{\infty}p_k(i)f(i)=∑k=0∞pk(i),pk(i)p ...