对SPI进行参数化结构设计
前言
为了避免每次SPI驱动重写,直接参数化,尽量一劳永逸。
SPI master有啥用呢,你发现各种外围芯片的配置一般都是通过SPI配置的,只不过有3线和四线。
SPI slave有啥用呢,当外部主机(cpu)要读取FPGA内部寄存器值,那就很有用了,fpga寄存器就相当于RAM,cpu通过SPI寻址读写数据。
代码仅供参考,勿做商业用途。
SPI salve
SPI salve支持功能:(1)支持三线SPI或者四线SPI。通过define切换。
(2)支持指令长度、帧长自定义。
(3)工作时钟可自定义,大于SPI clk的2倍。
用户只需修改:(1)几线SPI。(2)单帧长度。(3)指令长度。(4)寄存器开辟。
注意:指令最高bit表示读写,低写高读,其余bit表示地址。指令接着为数据端,两者位宽之和即为SPI单帧长。
//`define SPI_LINE //是否是三线SPI
`define SPI_FRAME_WIDTH //SPI一帧长度为16
`define SPI_INS_WIDTH //SPI指令长
`timescale 1ns/1ps
////
module spi_slave
(
input i_clk , //work clk
input i_rst_n , input i_spi_clk , //SPI clk
input i_spi_cs , //SPI cs `ifdef SPI_LINE //条件编译
inout io_spi_sdio
`else
input i_spi_mosi , //SPI mosi
output o_spi_miso //SPI miso
`endif
);
//位宽计算函数
function integer clogb2 (input integer depth);
begin
for (clogb2=; depth>; clogb2=clogb2+)
depth = depth >>;
end
endfunction
reg r_cs = 'b1; //打一拍
always @(posedge i_clk)
begin
r_cs <= i_spi_cs;
end
reg [:] r_spi_clk_edge = 'b00; //SPI clk边沿检测
always @(posedge i_clk)
begin
r_spi_clk_edge <= {r_spi_clk_edge[],i_spi_clk};
end //always
reg [clogb2(`SPI_FRAME_WIDTH-)-:] r_spi_cnt = 'd0;
always @(posedge i_clk)
begin
if (r_cs) //cs为高则归零
r_spi_cnt <= 'd0;
else if (r_spi_clk_edge == 'b10) //下降沿才计数
r_spi_cnt <= r_spi_cnt + 'd1;
end
////指令锁存
reg [`SPI_INS_WIDTH-:] r_ins = 'd0;
always @(posedge i_clk)
begin
if ((~r_cs) && (r_spi_clk_edge == 'b01)) //上升沿锁存数据
begin
if ((r_spi_cnt >= ) && (r_spi_cnt <= `SPI_INS_WIDTH-))
`ifdef SPI_LINE //条件编译
r_ins <= {r_ins[`SPI_INS_WIDTH-:],io_spi_sdio};
`else
r_ins <= {r_ins[`SPI_INS_WIDTH-:],i_spi_mosi};
`endif
end
end
////数值写入
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_data_rx = 'd0;
always @(posedge i_clk)
begin
if ((~r_cs) && (r_spi_clk_edge == 'b01)) //上升沿锁存数据
begin
if (r_spi_cnt >= `SPI_INS_WIDTH)
`ifdef SPI_LINE
r_data_rx <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:],io_spi_sdio};
`else
r_data_rx <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:],i_spi_mosi};
`endif
end
end
////用户寄存器定义
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_reg0 = 'd0;
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_reg1 = 'd0;
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_reg2 = 'd0;
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_reg3 = 'd0;
////
always @(posedge i_clk,negedge i_rst_n)
begin
if (~i_rst_n)
begin
r_reg0 <= 'd0;
r_reg1 <= 'd0;
r_reg2 <= 'd0;
r_reg3 <= 'd0; end
else if ((~r_ins[`SPI_INS_WIDTH-]) && (r_spi_cnt == (`SPI_FRAME_WIDTH-)) && (~r_cs) && (r_spi_clk_edge == 'b01))
begin
`ifdef SPI_LINE
case (r_ins[`SPI_INS_WIDTH-:])
'd0:begin r_reg0 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],io_spi_sdio}; end
'd1:begin r_reg1 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],io_spi_sdio}; end
'd2:begin r_reg2 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],io_spi_sdio}; end
'd3:begin r_reg3 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],io_spi_sdio}; end endcase
`else
case (r_ins[`SPI_INS_WIDTH-:])
'd0:begin r_reg0 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],i_spi_mosi}; end
'd1:begin r_reg1 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],i_spi_mosi}; end
'd2:begin r_reg2 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],i_spi_mosi}; end
'd3:begin r_reg3 <= {r_data_rx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-2:0],i_spi_mosi}; end endcase
`endif
end end
////寄存器值读出
reg [`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:] r_data_tx = 'd0;
always @(posedge i_clk)
begin
if (r_ins[`SPI_INS_WIDTH-] && (~r_cs) && (r_spi_clk_edge == 'b10))
begin
if (r_spi_cnt == (`SPI_INS_WIDTH-))
begin
case (r_ins[`SPI_INS_WIDTH-:])
'd0:begin r_data_tx <= r_reg0; end
'd1:begin r_data_tx <= r_reg1; end
'd2:begin r_data_tx <= r_reg2; end
'd3:begin r_data_tx <= r_reg3; end endcase
end
else
r_data_tx <= {r_data_tx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-:],'b0};
end
end ////读取输出
`ifdef SPI_LINE
assign io_spi_sdio = (r_ins[`SPI_INS_WIDTH-]) ? (((r_spi_cnt>=`SPI_INS_WIDTH) && (r_spi_cnt<`SPI_FRAME_WIDTH)) ? r_data_tx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-] : 'bz) : 1'bz;
`else
assign o_spi_miso = ((r_spi_cnt>=`SPI_INS_WIDTH) && (r_spi_cnt<`SPI_FRAME_WIDTH)) ? r_data_tx[`SPI_FRAME_WIDTH-`SPI_INS_WIDTH-] : 'b0;
`endif endmodule // end the spi_slave model
SPI master
spi master内部仅仅封装SPI驱动,写入值读出控制由上层控制,这部分逻辑很simple,不赘述。用户只需给入SPI帧及控制使能即可。
用户只需修改parameter参数:(1)单帧长。(2)指令长。(3)数据长。(4)工作时钟。(5)SPI clk。
实现不使用状态机,采用线性序列计数法。
//`define SPI_LINE //是否是三线SPI
`timescale 1ns/1ps
module spi_master
#(parameter p_spi_frame_width = , //SPI单帧长度
parameter p_spi_ins_width = , //指令长度
parameter p_spi_data_width = //读出数据长度
)
(
input i_clk , //系统时钟
input i_rst_n ,
input i_flag , //检测到flag的上升沿则启动一次传输,一个时钟周期即可 input [p_spi_frame_width-:] i_spi_data ,
output o_spi_cs ,
output o_spi_clk , `ifdef SPI_LINE //条件编译
inout io_spi_sdio ,
`else
input i_spi_miso , //SPI miso
output o_spi_mosi , //SPI mosi
`endif output o_transfer_done , //单次传输完成
output [p_spi_data_width-:] o_spi_data //读取数据
);
parameter p_clk_fre = ; //XXM时钟频率
parameter p_spi_clk_fre = 0.5*; //SPI 时钟速率,表示1M
parameter p_clk_div = p_clk_fre * /p_spi_clk_fre/-;
parameter p_spi_cnt_max = p_spi_frame_width*-;
parameter p_spi_ins_max = p_spi_ins_width*-;
//位宽计算函数
function integer clogb2 (input integer depth);
begin
for (clogb2=; depth>; clogb2=clogb2+)
depth = depth >>;
end
endfunction
//把最大值赋值给线型,直接用p_clk_div仿真有问题,但实际上板是可以的
wire [clogb2(p_clk_div)-:] w_clk_div;
assign w_clk_div = p_clk_div;
////时钟分频
reg [clogb2(p_clk_div)-:] r_cnt_div = 'd0;
always @(posedge i_clk)
begin
if (r_cnt_div == w_clk_div)
r_cnt_div <= 'd0;
else
r_cnt_div <= r_cnt_div + 'd1;
end //always
wire w_clk_en; //分频时钟使能
assign w_clk_en = (r_cnt_div == w_clk_div) ? 'b1 : 1'b0;
reg [:] r_flag_edge = 'b00;
reg [clogb2(p_spi_cnt_max)-:] r_spi_cnt = 'd0;
always @(posedge i_clk) //flag边沿检测
begin
r_flag_edge <= {r_flag_edge[],i_flag};
end
//flag信号展宽到低速时钟域
reg r_flag_enlarge = 'b0;
always @(posedge i_clk)
begin
if (r_flag_edge == 'b01) //上升沿拉高
r_flag_enlarge <= 'b1;
else if (r_spi_cnt == p_spi_ins_max) //足够长的高电平才拉低
r_flag_enlarge <= 'b0;
end
reg [:] r_flag_enlarge_edge = 'b00;
always @(posedge i_clk)
begin
if (w_clk_en)
r_flag_enlarge_edge <= {r_flag_enlarge_edge[],r_flag_enlarge};
end
reg r_cs = 'b1;
always @(posedge i_clk)
begin
if (w_clk_en)
begin
if (r_flag_enlarge_edge == 'b01) //检测到需要进行SPI操作
r_cs <= 'b0;
else if (r_spi_cnt == p_spi_cnt_max) //计数到最大值表示一次SPI完成
r_cs <= 'b1;
end
end
always @(posedge i_clk)
begin
if (w_clk_en)
begin
if(~r_cs) //在操作区间计数
r_spi_cnt <= r_spi_cnt + 'd1;
else
r_spi_cnt <= 'd0;
end
end
////数据传输段
reg [p_spi_frame_width-:] r_data = 'd0;
always @(posedge i_clk)
begin
if (w_clk_en)
begin
if (r_flag_enlarge_edge == 'b01) //上升沿刷入
r_data <= i_spi_data;
else if (r_spi_cnt[] == 'b1) //数据移动
r_data <= {r_data[p_spi_frame_width-:],'b1};
end
end
////数据读取段
reg [p_spi_data_width-:] r_data_read = 'd0;
always @(posedge i_clk)
begin
if (w_clk_en)
begin
if (i_spi_data[p_spi_frame_width-] && (r_spi_cnt > p_spi_ins_max) && (r_spi_cnt[] == 'b0)) //是读
`ifdef SPI_LINE
r_data_read <= {r_data_read[p_spi_data_width-:],io_spi_sdio};
`else
r_data_read <= {r_data_read[p_spi_data_width-:],i_spi_miso};
`endif
end
end
////SPI输出段
assign o_spi_cs = r_cs;
assign o_spi_clk = r_cs ? 'b0 : r_spi_cnt[0];
////SPI SDIO的输入输出切换
`ifdef SPI_LINE
assign io_spi_sdio = (i_spi_data[p_spi_frame_width-]) ? (((r_spi_cnt >= 'd0) && (r_spi_cnt <= p_spi_ins_max)) ? r_data[p_spi_frame_width-1] : 1'bz ) : r_data[p_spi_frame_width-];
`else
assign o_spi_mosi = r_data[p_spi_frame_width-];
`endif
assign o_transfer_done = ((~r_cs) && (r_spi_cnt == p_spi_cnt_max)) ? 'b1:1'b0;
assign o_spi_data = r_data_read; endmodule // end the spi_master model
仿真如下所示:写入四个寄存器值,再读出。
仿真代码如下:
`define TRANSFER_NUMBER //操作数为4
`define DATA 'ha5
//`define SPI_LINE
timeunit 1ns;
timeprecision 1ps;
module top;
parameter p_sim_end_time = ; //ns
logic l_clk = 'b0;
always #2.5 l_clk = ~l_clk;
////复位
logic l_rst_n = 'b0;
initial begin
# l_rst_n = 'b1;
end wire io_sdio;
wire o_spi_cs;
wire o_spi_clk;
wire o_transfer_done;
wire [:] o_spi_data;
////多个数据操作模式
reg r_flag = 'b0;
reg [:] r_first_cnt = 'b00;
always @(posedge l_clk,negedge l_rst_n)
begin
if (~l_rst_n)
r_first_cnt <= 'b00;
else if (r_first_cnt == 'd3)
r_first_cnt <= r_first_cnt;
else
r_first_cnt <= r_first_cnt + 'd1;
end
reg [:] r_transfer_done_edge = 'b00;
always @(posedge l_clk)
begin
r_transfer_done_edge <= {r_transfer_done_edge[],o_transfer_done};
end
reg [:] r_transfer_cnt = 'd0;
always @(posedge l_clk)
begin
if ((r_first_cnt == 'd2) && (r_transfer_cnt < `TRANSFER_NUMBER))
r_flag <= 'b1;
else if ((r_transfer_done_edge == 'b10) && (r_transfer_cnt < `TRANSFER_NUMBER-1))
r_flag <= 'b1;
else
r_flag <= 'b0;
end
always @(posedge l_clk)
begin
if (r_transfer_done_edge == 'b10)
r_transfer_cnt <= r_transfer_cnt + 'd1;
end
reg [:] r_in_data = 'd0;
always @(*)
begin
if (~l_rst_n) //仿真不执行此段仿真会有问题
r_in_data = 'h0000;
else
begin
case(r_transfer_cnt)
'd0:begin r_in_data = {8'h00,'h43}; end
'd1:begin r_in_data = 16'h0132; end
'd2:begin r_in_data = 16'h0245; end
'd3:begin r_in_data = 16'h0367; end
'd4:begin r_in_data = 16'h8000; end
'd5:begin r_in_data = 16'h8100; end
'd6:begin r_in_data = 16'h8200; end
'd7:begin r_in_data = 16'h8300; end default:begin r_in_data = 'h0000; end
endcase
end
end wire w_spi_miso;
wire w_spi_mosi; spi_master inst_spi_master (
.i_clk (l_clk),
.i_rst_n (),
.i_flag (r_flag),
.i_spi_data (r_in_data),
.o_spi_cs (o_spi_cs),
.o_spi_clk (o_spi_clk),
`ifdef SPI_LINE
.io_spi_sdio (io_sdio),
`else
.i_spi_miso (w_spi_miso),
.o_spi_mosi (w_spi_mosi),
`endif
.o_transfer_done (o_transfer_done),
.o_spi_data (o_spi_data) ); spi_slave inst_spi_slave (
.i_clk (l_clk),
.i_rst_n (l_rst_n), .i_spi_clk (o_spi_clk),
.i_spi_cs (o_spi_cs),
`ifdef SPI_LINE
.io_spi_sdio (io_sdio)
`else
.i_spi_mosi (w_spi_mosi),
.o_spi_miso (w_spi_miso)
`endif ); initial begin
#p_sim_end_time $stop;
end endmodule
三线SPI:
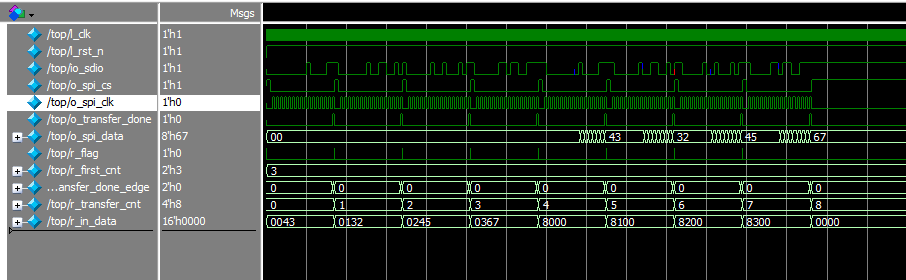
四线SPI:
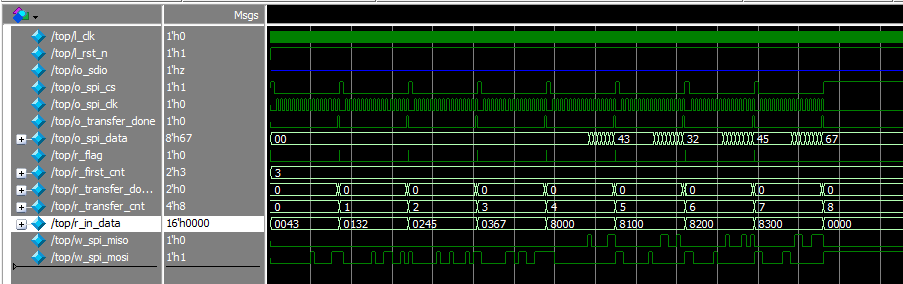
可以看到读写是一致的,验证通过。
以上。
对SPI进行参数化结构设计的更多相关文章
- LoadRunner脚本实例来验证参数化的取值
LoadRunner脚本实例来验证参数化的取值 SINM {3]!G0问题提出: 主要想试验下,在Controller中,多个用户,多次迭代中参数的取值.51Testing软件测试网(['H5f,d ...
- lr文件下载脚本(文件参数化重命名)
http://wenku.baidu.com/link?url=6oiIadyF9eFS4VshKbfJDnxrBh2IX919ndi0JO8yoqTRNRNIpavFrZJ9LPVb-FBSfbRY ...
- SQL Server 动态行转列(参数化表名、分组列、行转列字段、字段值)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 实现代码(SQL Codes) 方法一:使用拼接SQL,静态列字段: 方法二:使用拼接SQL, ...
- 数据库表结构设计方法及原则(li)
数据库设计的三大范式:为了建立冗余较小.结构合理的数据库,设计数据库时必须遵循一定的规则.在关系型数据库中这种规则就称为范式.范式是符合某一种设计要求的总结.要想设计一个结构合理的关系型数据库,必须满 ...
- Google C++单元测试框架GoogleTest---值参数化测试
值参数化测试允许您使用不同的参数测试代码,而无需编写同一测试的多个副本. 假设您为代码编写测试,然后意识到您的代码受到布尔参数的影响. TEST(MyCodeTest, TestFoo) { // A ...
- SPI基础知识
Serial Peripheral Interface 是摩托罗拉公司提出的一种总线协议,主要应用在EEPROM,FLASH,实时时钟,A/D转换,以及数字信号处理和数字信号解码器中 是一种高速,全双 ...
- spi子系统之驱动SSD1306 OLED
spi子系统之驱动SSD1306 OLED 接触Linux之前,曾以为读源码可以更快的学习软件,于是前几个博客都是一边读源码一边添加注释,甚至精读到每一行代码,实际上效果并不理想,看过之后就忘记了.主 ...
- java中的SPI机制
1 SPI机制简介 SPI的全名为Service Provider Interface.大多数开发人员可能不熟悉,因为这个是针对厂商或者插件的.在java.util.ServiceLoader的文档里 ...
- 基于TQ2440的SPI驱动学习(OLED)
平台简介 开发板:TQ2440 (NandFlash:256M 内存:64M) u-boot版本:u-boot-2015.04 内核版本:Linux-3.14 作者:彭东林 邮箱:pengdongl ...
随机推荐
- 算法习题---3.11换抵挡装置(UVa1588)
一:题目 给你连个长度分别为n1,n2且每列高度只为1或2的长条,然后将他们拼在一起,高度不能超过3,问他们拼在一起的最短长度 二:实现思路 1.获取主动轮和从动轮的数据. 2.主动轮不动,从动轮从左 ...
- 123457123456#0#-----com.twoapp.YiZhiPuzzle02--前拼后广--儿童日常拼图游戏jiemei
com.twoapp.YiZhiPuzzle02--前拼后广--儿童日常拼图游戏jiemei
- application.properties在Spring Boot项目中的位置
application.properties可以放在如下位置: 当前目录的 "/config"的子目录下 当前目录下 classpath根目录的"/config" ...
- 【Leetcode_easy】804. Unique Morse Code Words
problem 804. Unique Morse Code Words solution1: class Solution { public: int uniqueMorseRepresentati ...
- localStorage 存储 数组
let str = JSON.stringify(data.list); localStorage.setItem("options",str); let optionss=loc ...
- iOS面试题超全!
之前看了很多面试题,感觉要不是不够就是过于冗余,于是我将网上的一些面试题进行了删减和重排,现在分享给大家.(题目来源于网络,侵删) 1. Object-c的类可以多重继承么?可以实现多个接口么?Cat ...
- Newton法(牛顿法 Newton Method)
1.牛顿法应用范围 牛顿法主要有两个应用方向:1.目标函数最优化求解.例:已知 f(x)的表达形式,,求 ,及g(x)取最小值时 ...
- 【c# 学习笔记】继承
在c#中,一个类可以继承另外一个已有的类(密封类除外),被继承的类称为基类(或父类),继承的类称为派生类(或子类),子类将获得基类 除构造函数和析构函数以外的所有成员.此外,静态类是密封的,也不能被继 ...
- myeclipse安装activiti-designer
将压缩包中的features和plugins放到dropins下,然后重启myeclipse activiti-designer下载地址: 链接:https://pan.baidu.com/s/19u ...
- utf8 gbk 互转
public static function utf8_to_gbk($utfstr) { return iconv("utf-8", "gbk//IGNORE" ...