【R作图】lattice包,画多个分布柱形图,hist图纵轴转换为百分比
一开始用lattice包,感觉在多元数据的可视化方面,确实做得非常好。各种函数,可以实现任何想要实现的展示。
| barchart(y ~ x) | y对x的直方图 |
| bwplot(y ~ x) | 盒形图 |
| densityplot(~ x) | 密度函数图 |
| dotplot(y ~ x) | Cleveland点图(逐行逐列累加图) |
| histogram(~ x) | x的频率直方图 |
| qqmath(~ x) | x的关于某理论分布的分位数-分位数图 |
| stripplot(y ~ x) | 一维图,x必须是数值型,y可以是因子 |
| qq(y ~ x) | 比较两个分布的分位数,x必须是数值型,y可以是数值型,字符型,或者因子,但是必须有两个"水平" |
| xyplot(y ~ x) | 二元图(有许多功能) |
| levelplot(z ~ x*y) contourplot(z ~ x*y) |
在x,y坐标点的z值的彩色等值线图(x,y和z等长) |
| cloud(z ~ x*y) | 3-D透视图(点) |
| wireframe(z ~ x*y) |
同上(面) |
| splom(~ x) | 二维图矩阵 |
| parallel(~ x) | 平行坐标图 |
下面详细介绍下xyplot,xyplot相当于plot,不过可以画多个子图。
一.不过如果想要在每个子图里展示几种点或线,就要想想办法了。
1)这是一个利用公式关系的方法:Sepal.Length + Sepal.Width ~ Petal.Length + Petal.Width能在一个子图中画出
Sepal.Length ~ Petal.Length,Sepal.Width ~ Petal.Length,Sepal.Length ~ Petal.Width,Sepal.Width ~ Petal.Width四种关系
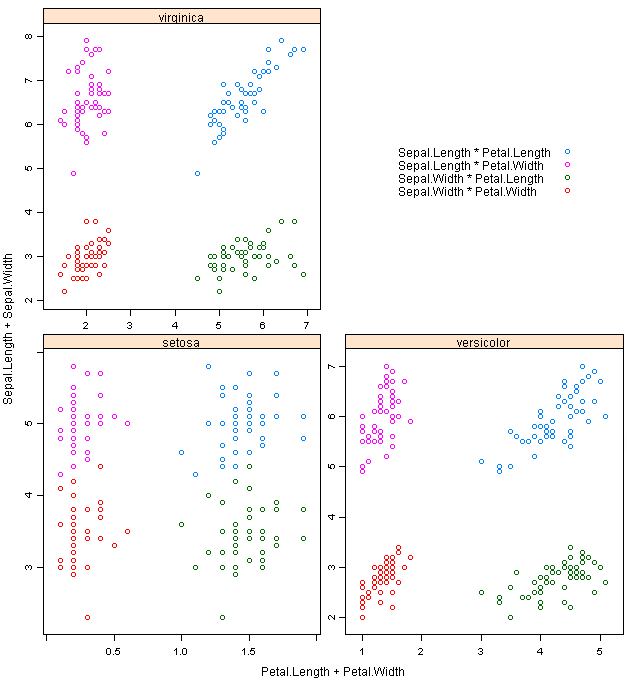
*代码:
library(lattice)
require(stats)
xyplot(Sepal.Length + Sepal.Width ~ Petal.Length + Petal.Width | Species,
data = iris, scales = "free", layout = c(2, 2),
auto.key = list(x = .6, y = .7, corner = c(0, 0)))
2)下面是另一种方法,利用groups参数:
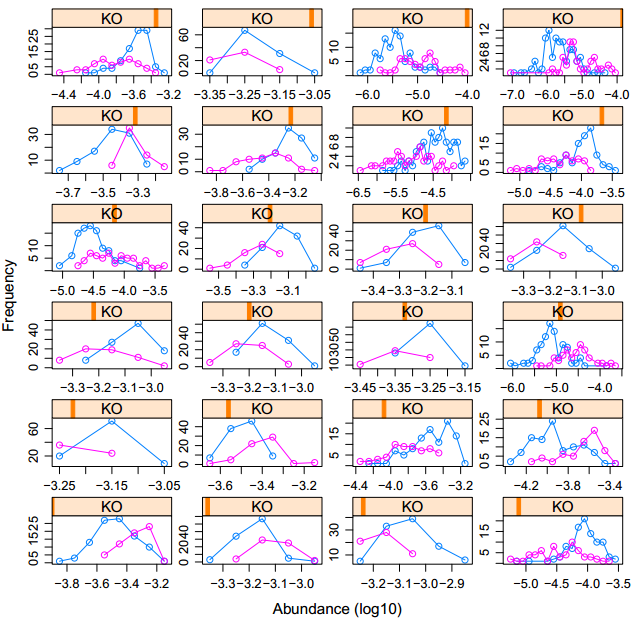
*代码:
xyplot(freq~abun |KO ,groups=country,data =zz, type="o", layout = c(4, 6),xlab="Abundance (log10)",ylab="Frequency",scales="free")
不过我想要画hist分布图,所以尝试了几种不同方法:
1)barchart:可惜柱子的透明度无法调节
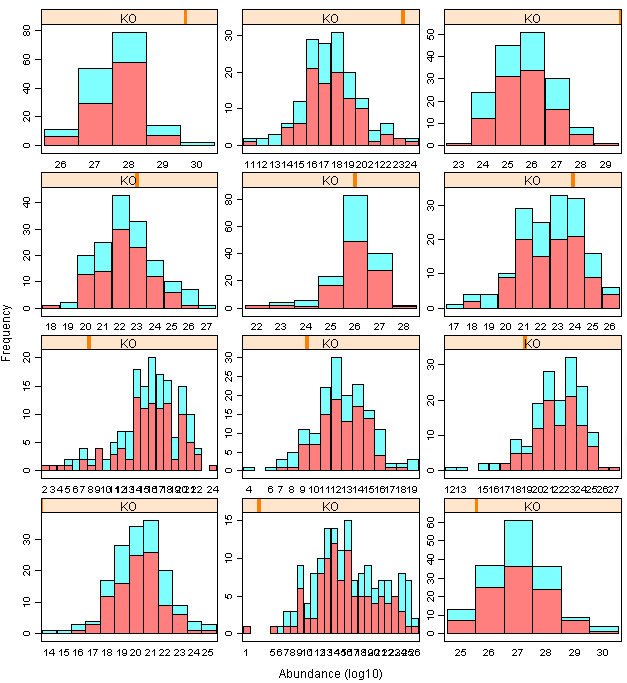
*代码:
barchart(freq~abun |KO ,groups=country,data =zz,stack =T,strip=T, layout = c(2, 2),xlab="Abundance (log10)",ylab="Frequency",scales="free",col=rainbow(2,alpha=0.5),box.ratio =100,horizontal=F)
2)想用xyplot 函数,把type改成“h”柱形,但是 lwd 这个参数没法每个子图不一样,lend参数无效 。
*代码:
xyplot(freq~abun |KO ,groups=country,data =zz, type="h", lwd = 10, lend =2, layout = c(4, 6),xlab="Abundance (log10)",ylab="Frequency",scales="free",col=rainbow(2,alpha=0.5))
3)经过一番研究,用histogram函以及函数中的panel(子图中加函数)可以实现,但是发觉xlim无法各个子图自己调整,最后无奈选择最原始的方法。

*代码:
histogram(~abun |KO ,data=zz , layout = c(4, 6),xlab="Abundance (log10)",ylab="Frequency",scales="free",col=rainbow(2,alpha=0.5)[1],
panel = function(x, ...) {
panel.histogram(x[1:100],breaks=NULL,type="count",col = rainbow(2,alpha=0.5)[1])
panel.histogram(x[101:160],breaks=NULL,type="count",col = rainbow(2,alpha=0.5)[2])
}
)
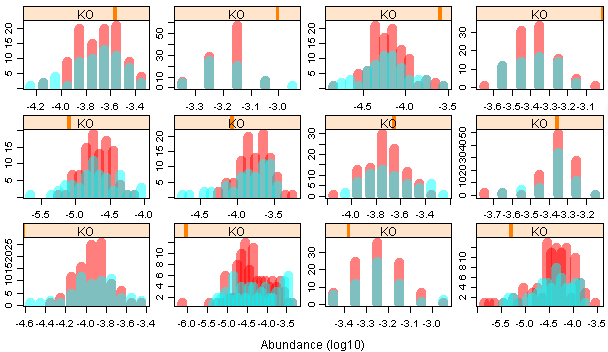
4)最原始的方法:
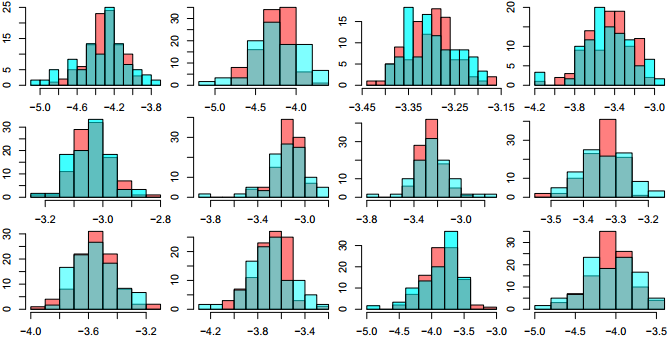
*代码:
par(mfrow=c(6,4),mar=c(2.1,2.1,0.1,0.1))
for (i in 1:length(id))
{
tmp=log10(as.numeric(data[id[i],2:161]))
a=hist(tmp,breaks=10,plot=F)
b=hist(tmp[1:100],breaks=a$breaks,plot=F)
c=hist(tmp[101:160],breaks=a$breaks,plot=F)
if((max(b$count)/100)>(max(c$count)/60)){
hist(tmp[1:100],breaks=a$breaks,col=rainbow(2,alpha=0.5)[1],xlab="",ylab="",main="");
e=hist(tmp[101:160],breaks=a$breaks,plot=F)
e$counts = e$counts*100/sum(e$counts)
plot(e,add=T,col=rainbow(2,alpha=0.5)[2],xlab="",ylab="",main="")
}else{
e=hist(tmp[101:160],breaks=a$breaks,plot=F)
e$counts = e$counts*100/sum(e$counts)
plot(e,col=rainbow(2,alpha=0.5)[2],xlab="",ylab="",main="",border=0)
hist(tmp[1:100],breaks=a$breaks,add=T,col=rainbow(2,alpha=0.5)[1],xlab="",ylab="",main="");
plot(e,add=T,col=rainbow(2,alpha=0.5)[2],xlab="",ylab="",main="")
}
}
最后终于大功告成,里面还有很多地方值得仔细研究。
例如:
i.我两组样品的数量不一样,但是我想在一个hist图中比较,怎么办?hist纵轴百分比显示!!!
e=hist(tmp[101:160],breaks=a$breaks,plot=F)#先hist存到变量中
e$counts = e$counts*100/sum(e$counts) #将counts转换成百分比
plot(e,add=T,col=rainbow(2,alpha=0.5)[2],xlab="",ylab="",main="")#再画图
ii.我画两个具有一定透明度的hist,发觉画图先后顺序对重叠部分的颜色有影响,例如我先画红色再画蓝色vs.先画蓝色再画红色,结果就不一样了。

但是我又需要让x轴和y轴依据最大的图来确定。
所以我先根据所有数据来取breaks,保持两个hist的break一致,这样x轴问题就解决了;
然后判断哪个hist的y值最大,那么我先根据最大的那个画一个空白的hist,y轴问题解决;
然后再按照先红后蓝的顺序画上两个hist。
【R作图】lattice包,画多个分布柱形图,hist图纵轴转换为百分比的更多相关文章
- 使用R的networkD3包画可交互的网络图
d3network包code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs & ...
- R语言diagram包画订单状态流图
代码如下: library("diagram") #a <- read.table(file="clipboard",header=TRUE) write ...
- R语言 ggplot2包
R语言 ggplot2包的学习 分析数据要做的第一件事情,就是观察它.对于每个变量,哪些值是最常见的?值域是大是小?是否有异常观测? ggplot2图形之基本语法: ggplot2的核心理念是将 ...
- R语言常用包汇总
转载于:https://blog.csdn.net/sinat_26917383/article/details/50651464?locationNum=2&fps=1 一.一些函数包大汇总 ...
- 安装R语言扩展包vegan
这周的作业我开始得好迟啊...然而还是要努力做啊... ××××××××××××××我是萌萌哒分割线×××××××××××××××××××××××××××××××××××× 首先,百度进入官方页面,看 ...
- R语言-Knitr包的详细使用说明
R语言-Knitr包的详细使用说明 by 扬眉剑 来自数盟[总舵] 群:321311420 1.相关资料 1:自动化报告-谢益辉 https://github.com/yihui/r-ninja/bl ...
- 每R一点:各种画地图,全是知识点,90%人不知道!(转)
R语言绘制地图,在数据分析中经常能够用到,并且会达到非常好的展示效果,本节以例子形式,介绍如何使用R语言工具,画出理想的地图. 本节例子在 R version 2.15.3版本下运行顺畅,其他版本待定 ...
- R+NLP︱text2vec包——四类文本挖掘相似性指标 RWMD、cosine、Jaccard 、Euclidean (三,相似距离)
要学的东西太多,无笔记不能学~~ 欢迎关注公众号,一起分享学习笔记,记录每一颗"贝壳"~ --------------------------- 在之前的开篇提到了text2vec ...
- R语言-神经网络包RSNNS
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
随机推荐
- POJ2065 SETI 高斯消元
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - POJ2065 题意概括 多组数据,首先输入一个T表示数据组数,然后,每次输入一个质数,表示模数,然后,给出一 ...
- BZOJ1966 [Ahoi2005]VIRUS 病毒检测 动态规划
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1966 题意概括 现在有一些串和一个病毒模板.让你统计非病毒串的总数.串个数<=500. 串由 ...
- java实现判断一个经纬度坐标是否在一个多边形内(经自己亲测)
1.在高德地图上绘制的多边形:经纬度逗号分隔格式:上面是用来方便存坐标的对象:下面是方法测试:直接复制代码即可运行 public class Point { private Double x; pri ...
- 037 关于pom.xml的一些问题的理解
最近在pom上出了一些问题,搞了一天才理解了一些问题,记录一下. 当在覆盖本地repository包之后,pom.xml上面出现了一个x. 当mvn->update project之后,还是有许 ...
- (转)Java按指定行数读取文件
package test import java.io.File; import java.io.FileReader; import java.io.IOException; import java ...
- Linux系统 vi/vim文本编辑器
Linux系统 vi/vim文本编辑器 (一)Vim/Vi简介 (二)Vim/Vi工作模式 (三)Vim/Vi基本使用 (四)Vim/Vi应用技巧 (一)Vim/Vi简介 Vim/Vi是一个功能强大的 ...
- loj#2071. 「JSOI2016」最佳团体
题目链接 loj#2071. 「JSOI2016」最佳团体 题解 树形dp强行01分规 代码 #include<cstdio> #include<cstring> #inclu ...
- 10.25 正睿停课训练 Day9
目录 2018.10.25 正睿停课训练 Day9 A 数独(思路 DP) B 红绿灯(最短路Dijkstra) C 轰炸(计算几何 圆并) 考试代码 B C 2018.10.25 正睿停课训练 Da ...
- 深港DJ好听的歌曲
好听女声 Dj陈爷-全中文全国语慢歌连版音乐挑选磁性女声翻唱慢摇串烧 http://www.vvvdj.com/play/154270.html DjPad仔-全中文国粤语Rnb音乐清风主流吃鸡学猫叫 ...
- webstorm激活方法
安装完成后,打开 WebStorm, 在打开的 License Activation 窗口中选择第三个选项: License server. 在输入框输入网址即可 最新网址: https://s.tu ...