019 mapreduce的核心--shuffle理解,以及在shuffle中的优化
关于shuffle的过程图。

一:概述shuffle
Shuffle是mapreduce的核心,链接map与reduce的中间过程。
Mapp负责过滤分发,而reduce则是归并整理,从mapp输出到reduce的输入的这个过程称为shuffle过程。
二:map端的shuffle
1.map结果的输出
map的处理结果首先存放在一个环形的缓冲区。
这个缓冲区的内存是100M,是map存放结果的地方。如果数据量较大,超过了一定的量(默认80M),将会发生溢写过程。
在mapred-site.xml中设置内存的大小
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
在mapred-site.xml中设置内存溢写的阈值
<property>
<name>mapreduce.task.io.sort.spill.percent</name>
<value>0.8</value>
</property>

2.溢写过程(这个过程是一个阶段,不是一个简单的写的过程)
溢写是系统在后台单独开一个线程去操办。
溢写过程包括:分区partitioner,排序sort,溢写spill to disk,合并merge。
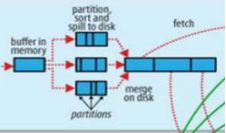
3.分区
分区分的是80%的内存。
因为reduce可能有不同的任务,所以会对80M的内存进行分区,将map的输出结果放入的对应的reduce分区中。
4.排序
默认是按照key排序。
当分区完成之后,对每一个分区的数据进行排序。
排序发生在数据到达80M的时候。(2017.12.24,刚刚想了一下,应该是这个时候)
5.溢写
排序之后,将内存的数据写入硬盘。留出内存方便map的新的输出结果。
6.合并
如果是第一次写入硬盘则不需要考虑合并问题,但是在大数据的情况下,前面已经存在大量的spill文件的时候,这时候需要将它们进行合并。
将各个分区合并之后,对每一个分区的数据再进行一次排序。(2017.12.24,这个比较重要,注意点是各个分区合并)
使用归并的方式进行合并,归并算法。
实现comparator比较器,进行比较。
形成一个文件。
三:reduce端的shuffle
1.步骤
对于reduce端的shuffle,和map端的shuffle步骤相同。但是有一个特别的步骤,分组。
2.复制
当reduce开启任务后,不断的在各个节点复制需要的数据。
3.合并(内含排序)
复制数据的时候,把可以存放进内存的就把数据存放在内存中,当达到一定的时候,启动merge,将数据写进硬盘。
如果map数据大于内存需要存放的限制,直接写入硬盘,当达到一定的数量后将其合并为一个文件。
这时候,reduce开启任务需要的数据在内存中和在硬盘中,最终形成一个全局文件。
4.分组
《hadoop,1》
《hadoop,1》
《yarn,1》
《hadoop,1》
《hdfs,1》
《yarn,1》
将相同的key放在一起,使用comparable完成比较。
结果为:
《hadoop,list(1,1,1)》
《yarn,list(1,1)》
《hdfs,list(1)》
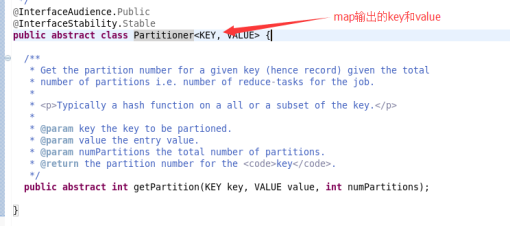
四:关于Comparator的理解
不管是排序还是分组,都需要自定义排序器comparable
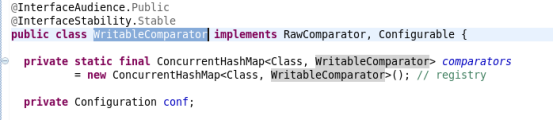
Comparator类继承WritableComparator

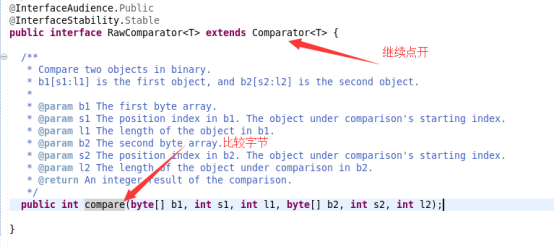
而WritableComparator完成接口RawComparator
在RawComparator中:

五:shuffle处的优化
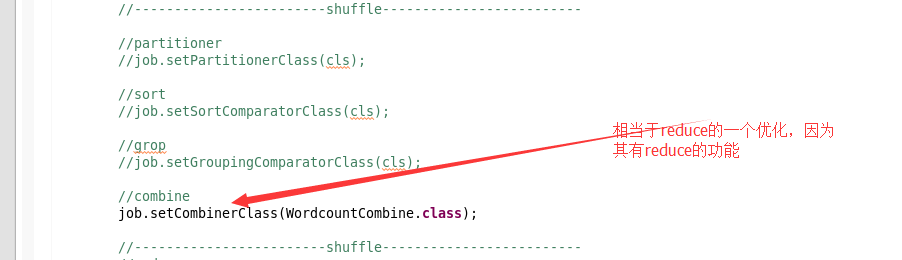
1.combine的优化
这是map段的reduce。
好处就是提前进行一次reduce,注意点是每个map进行一次reduce之后,数据量合并变小。
问题:是否还需要reduce?
回答:这个是map段的reduce,正真的reduce是许多map的一个汇总,所以是需要的。(2017.12.24,想法不知道对不对,希望以后进行仔细研究)
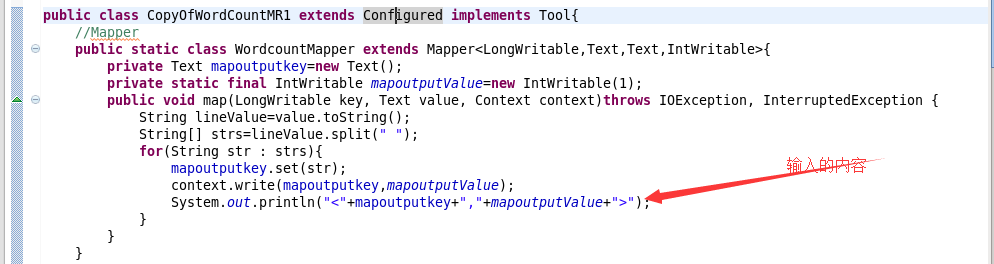
2.下面列举需要修改的程序

3.输出结果
4.关于压缩方面的优化
这个优化也属于map段的一个优化部分。
但是优化的方式是修改配置项。
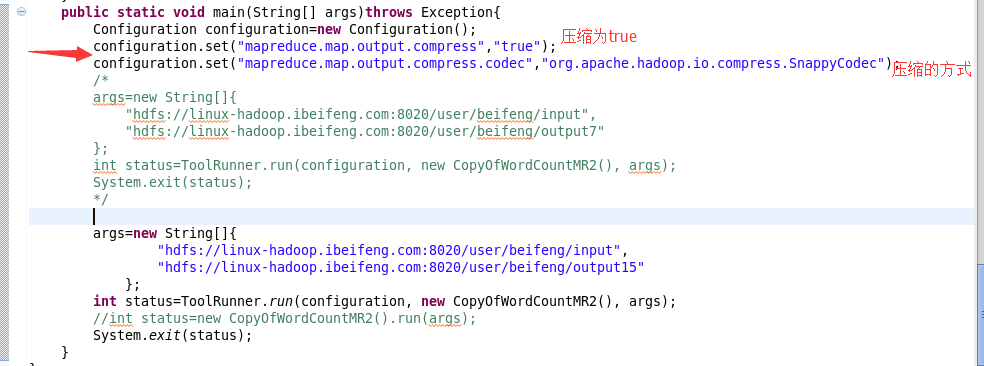
注意点:
会出现的问题:

六:属于分区的一个思路
shuffle中程序:

说明:
这个根据reduce实际需求决定。
根据测试决定合理的reduce数目。
七:shuffle最终总结、
包括优化部分,可以将shuffle分为五个部分。
map端:分区
排序
合并combine
压缩
reduce端:分组
八:完整的程序
package com.senior.bigdata; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class OptimizeOfWordCountMR extends Configured implements Tool{
//Mapper
public static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private Text mapoutputkey=new Text();
private static final IntWritable mapoutputvalue=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String lineValue=value.toString();
String[] strs=lineValue.split(" ");
for(String str:strs){
mapoutputkey.set(str);
context.write(mapoutputkey, mapoutputvalue);
// System.out.println(mapoutputkey+"<---->"+mapoutputvalue);
}
} } //combiner
public static class WordCountCombiner extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable outputvalue=new IntWritable();
@Override
protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {
int sum=0;
// System.out.println("key="+text);
for(IntWritable value:values){
sum+=value.get();
// System.out.print(value.get());
}
// System.out.println();
outputvalue.set(sum);
context.write(text, outputvalue);
} } //Reducer
public static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable outputvalue=new IntWritable();
@Override
protected void reduce(Text text, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {
int sum=0;
// System.out.println("key==="+text);
for(IntWritable value:values){
// System.out.print(value.get());
sum+=value.get();
}
// System.out.println();
outputvalue.set(sum);
context.write(text, outputvalue);
} } //Driver
public int run(String[] args)throws Exception{
Configuration conf=this.getConf();
Job job=Job.getInstance(conf,this.getClass().getSimpleName());
job.setJarByClass(OptimizeOfWordCountMR.class);
//input
Path inpath=new Path(args[0]);
FileInputFormat.addInputPath(job, inpath); //output
Path outpath=new Path(args[1]);
FileOutputFormat.setOutputPath(job, outpath); //map
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //shuffle
job.setCombinerClass(WordCountCombiner.class); //combiner //reduce
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //submit
boolean isSucess=job.waitForCompletion(true);
return isSucess?0:1;
} //main
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration();
//compress
conf.set("mapreduce.map.output.compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
args=new String[]{
"hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/input",
"hdfs://linux-hadoop01.ibeifeng.com:8020/user/beifeng/mapreduce/wordcount/output5"
};
int status=ToolRunner.run(new OptimizeOfWordCountMR(), args);
System.exit(status);
} }
019 mapreduce的核心--shuffle理解,以及在shuffle中的优化的更多相关文章
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
- MapReduce的核心编程思想
1.MapReduce的核心编程思想 2.yarn集群工作机制 3.maptask并行度与决定机制 4.maptask工作机制 5.MapReduce整体流程 6.shuffle机制 7.yarn架构
- MapReduce的核心运行机制
MapReduce的核心运行机制概述: 一个完整的 MapReduce 程序在分布式运行时有两类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.Yarnchild:负责 ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- Node.js面试题:侧重后端应用与对Node核心的理解
Node是搞后端的,不应该被被归为前端,更不应该用前端的观点去理解,去面试node开发人员.所以这份面试题大全,更侧重后端应用与对Node核心的理解. node开发技能图解 node 事件循环机制 起 ...
- node.js面试题大全-侧重后端应用与对Node核心的理解
Node是搞后端的,不应该被被归为前端,更不应该用前端的观点去理解,去面试node开发人员.所以这份面试题大全,更侧重后端应用与对Node核心的理解. github地址: https://github ...
- MR的shuffle和Spark的shuffle之间的区别
mr的shuffle mapShuffle 数据存到hdfs中是以块进行存储的,每一个块对应一个分片,maptask就是从分片中获取数据的 在某个节点上启动了map Task,map Task读取是通 ...
- 理解与应用css中的display属性
理解与应用css中的display属性 display属性是我们在前端开发中常常使用的一个属性,其中,最常见的有: none block inline inline-block inherit 下面, ...
- 理解和使用 JavaScript 中的回调函数
理解和使用 JavaScript 中的回调函数 标签: 回调函数指针js 2014-11-25 01:20 11506人阅读 评论(4) 收藏 举报 分类: JavaScript(4) 目录( ...
随机推荐
- bzoj 1724 优先队列 切割木板
倒着的石子合并,注意不是取当前最长木板贪心做,而是取当前最小累加答案: 例如 4 5 6 7 若按第一种思路:ans=22+15+9 第二种:ans=22+13+9,可以先从中间某一块分开,这样答案更 ...
- Linux 开机启动图形界面,shell界面
查看当前启动模式 # systemctl get-default 更改模式命令: systemctl set-default graphical.target由命令行模式更改为图形界面模式 syste ...
- Java EE之Struts2路径访问小结
一.项目WEB视图结构 注释:struts.xml:最普通配置,任何无特殊配置 二.访问页面 1.访问root.jsp //方式1: http://localhost/demo/root.jsp // ...
- Spring+Struts+Mybatis+Shiro整合配置
Jar包
- ubuntu14.04 放开串口权限
可以用如下命令查看串口信息: ls -l /dev/ttyUSB*来查看相关的信息. 但是普通用户没有usb操作权限(函数open()打不开串口:refused),如果我们想在ROS程序里面打开串口, ...
- AutoMapper中用户自定义转换
Custom Type Converters Sometimes, you need to take complete control over the conversion of one type ...
- linux服务器last查看关机记录
1.查看重启记录 last reboot命令 [root@test ~]# last reboot reboot system boot -.el6.x Mon May : - : (+:) rebo ...
- ES系列十八、FileBeat发送日志到logstash、ES、多个output过滤配置
一.FileBeat基本概念 简单概述 最近在了解ELK做日志采集相关的内容,这篇文章主要讲解通过filebeat来实现日志的收集.日志采集的工具有很多种,如fluentd, flume, logst ...
- HTML学习笔记09-列表
HTML支持无序,有序,自定义列表 列表项内部可以使用段落.换行符.图片.连接.以及其他列表等 无序列表 无序列表使用粗体圆点(典型的小黑圆圈)进行标记,列表始于<ul>标签,列表项使用& ...
- Mashup
简介 mashup是糅合,是当今网络上新出现的一种网络现象,将两种以上使用公共或者私有数据库的web应用,加在一起,形成一个整合应用.一般使用源应用的API接口,或者是一些rss输出(含atom)作为 ...