hashCode 一致性hash 算法
1 如果两个对象相同,那么它们的hashCode值一定要相同。也告诉我们重写equals方法,一定要重写
hashCode方法,同一个对象那么hashcode就是同一个(同一个对象什么都是相同的)。
2 如果两个对象的hashCode相同,它们并不一定相同,这里的对象相同指的是用eqauls方法比较。
Object类中hashCode()方法的声明如下:
Object类中hashCode()方法的声明如下:
1 public native int hashCode();
可以看出,hashCode()是一个native方法,而且返回值类型是整形;实际上,该native方法将对象在内存中的地址作为哈希码返回,可以保证不同对象的返回值不同。
2、hashCode()的作用
总的来说,hashCode()在哈希表中起作用,如HashSet、HashMap等。
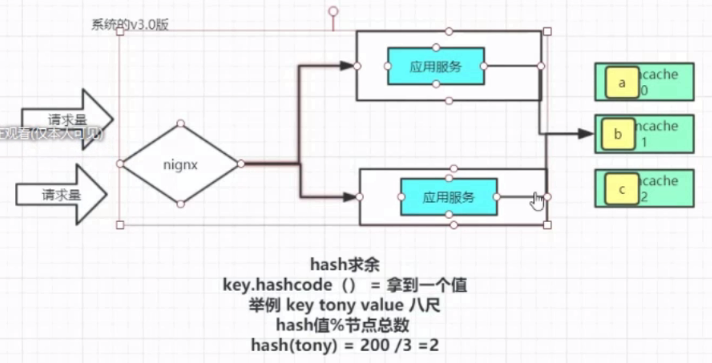
当我们向哈希表(如HashSet、HashMap等)中添加对象object时,首先调用hashCode()方法计算object的哈希码,通过哈希码可以直接定位object在哈希表中的位置(一般是哈希码对哈希表大小取余)。如果该位置没有对象,可以直接将object插入该位置;如果该位置有对象(可能有多个,通过链表实现),则调用equals()方法比较这些对象与object是否相等,如果相等,则不需要保存object;如果不相等,则将该对象加入到链表中。
这也就解释了为什么equals()相等,则hashCode()必须相等。如果两个对象equals()相等,则它们在哈希表(如HashSet、HashMap等)中只应该出现一次;如果hashCode()不相等,那么它们会被散列到哈希表的不同位置,哈希表中出现了不止一次。
实际上,在JVM中,加载的对象在内存中包括三部分:对象头、实例数据、填充。其中,对象头包括指向对象所属类型的指针和MarkWord,而MarkWord中除了包含对象的GC分代年龄信息、加锁状态信息外,还包括了对象的hashcode;对象实例数据是对象真正存储的有效信息;填充部分仅起到占位符的作用, 原因是HotSpot要求对象起始地址必须是8字节的整数倍。
hashcode:返回值是int值,并且每次运行的结果不一样,可以理解为内存编号,便于CPU 快速查找。当
然自己可以去重写hashcode方法,但是要保证每个对象的hashcode值不一样,如果一样,那么CPU查找这
个对象的时候就会出错。
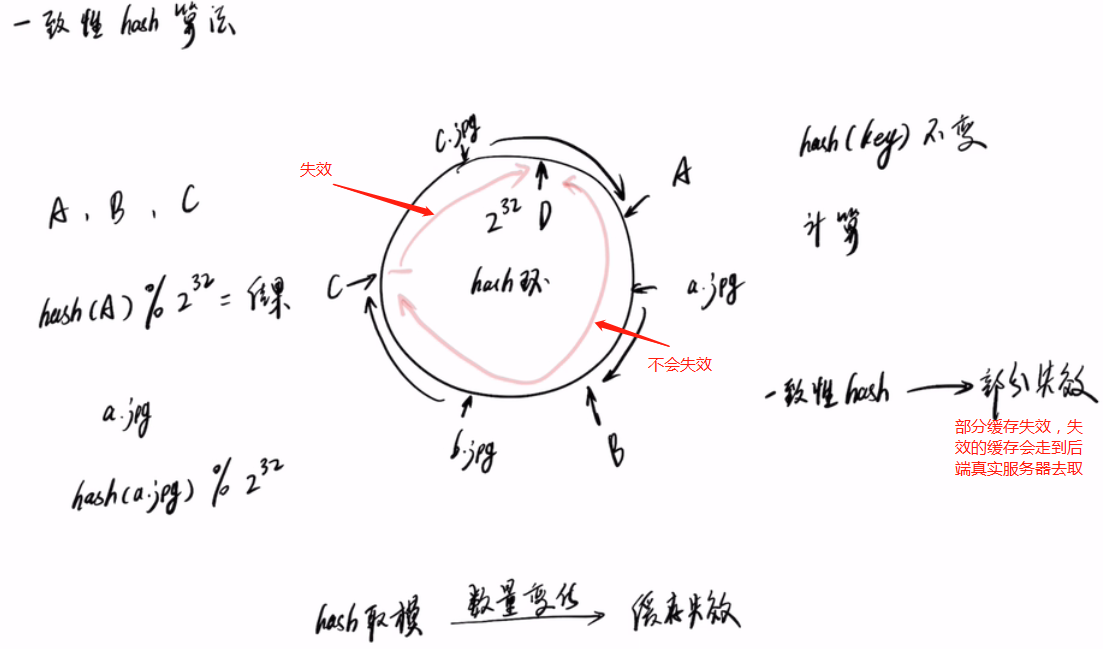
一致性hash 算法

int型占4个字节,有32位,所以有2^31-1个,即2147483647。因为我们这里用的是int值来标识位置信息,所以环的长度是Interger的最大值。否则会覆盖。
原来ACB3个机器,现在增加D这个机器。缓存失效也只有部分缓存失效。失效的缓存将会在后端真实服务器去取。
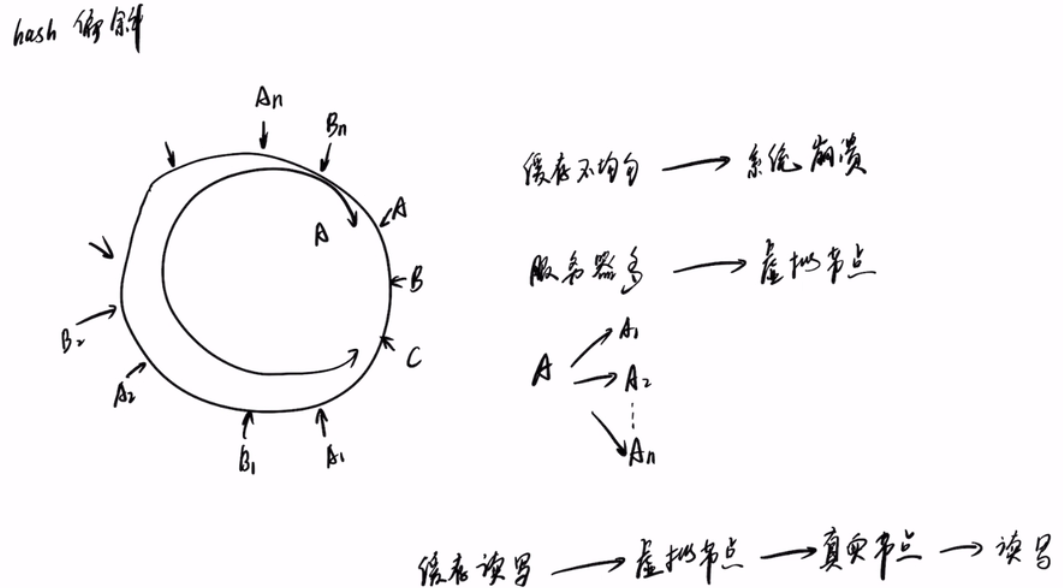
hash倾斜:会导致ABC3台机器在环上分配不均匀,那么所有的数据都在机器A上,当缓存失效的时候会有大量数据失效,从而加重后端非缓存机器的崩溃,所以可以在环上加很多虚礼节点,A加点虚拟出A1 A2 A3 ...,数据读写的时候,先算出虚礼节点的位置,然后找到真实节点,在把数据放入真实节点进行读写。虚礼节点也会跟真实节点碰撞。
hashCode 一致性hash 算法的更多相关文章
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- Java实现一致性Hash算法深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中”一致性Hash算法”部分,对于为什么要使用一致性Hash算法和一致性Hash算法的算法原 ...
- 一致性Hash算法与代码实现
一致性Hash算法: 先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值 ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
- 自己实现一个一致性 Hash 算法
前言 在前文分布式理论(八)-- Consistent Hash(一致性哈希算法)中,我们讨论了一致性 hash 算法的原理,并说了,我们会自己写一个简单的算法.今天就来写一个. 普通 hash 的结 ...
- 对一致性Hash算法及java实现(转)
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 第十一章 自己实现一致性hash算法
关于一致性hash算法的意义以及其相对于简单求余法(除数求余法)的好处,查看第六章 memcached剖析 注意:真实的hash环的数据结构是二叉树,这里为了简便使用了列表List 1.一致性hash ...
- 分布式缓存设计:一致性Hash算法
缓存作为数据库前的一道屏障,它的可用性与缓存命中率都会直接影响到数据库,所以除了配置主从保证高可用之外还需要设计分布式缓存来扩充缓存的容量,将数据分布在多台机器上如果有一台不可用了对整体影响也比较小. ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
随机推荐
- host文件
# Copyright (c) 1993-2009 Microsoft Corp. # # This is a sample HOSTS file used by Microsoft TCP/IP f ...
- 并发编程---开启进程方式---查看进程pid
1.开启进程的两种方式 方式一: from multiprocessing import Process import time def task(name): print('%s is runnin ...
- docker的容器和镜像的差别
- HBase学习总结(1)
HBase是一种数据库:HadoopDatabase顾名思义就是Hadoop数据库,它是一种基于hadoop文件系统HDFS的一种分布式数据库,专门设计用来快速随机读写大规模数据.本文介绍HBase的 ...
- [vue]模拟移动端三级路由: router-link位置体现router的灵活性
小结 router-link可以随便放 router-view显示的是父组件的直接子组件的内容 想研究下移动三级路由的逻辑, 即 router-link和router-view 点首页--点新闻资讯( ...
- 常量,变量,a++,++a,+=等
常量:数据在程序里面进行运算时不能发生改变的数据,成为常量.变量:可变动的数据.变量的定义: 数据类型 变量名 = 初始值.基本数据类型:整数型:byte 1字节 ...
- redis集群redis-cloud搭建
Redis集群中至少应该有三个节点.要保证集群的高可用,需要每个节点有一个备份机.Redis集群至少需要6台服务器. 搭建伪分布式.可以使用一台虚拟机运行6个redis实例.需要修改redis的端口号 ...
- word2vec训练出来的相似词歧义
[问题]word2vec训练以后,得到预付卡和购物卡非常接近,可是实际上这两个东西是不一样的,如何区分这两个东西? 解决:建立一个独立词典,这个词典里的词是没有近义词的,独立的词,比如预付卡是很独特的 ...
- MySQL数据类型--与MySQL零距离接触 3-2 外键约束的要求解析
列级约束:只针对某一个字段 表级约束:约束针对2个或2个以上的字段 约束类型是按功能来划分. 外键约束:保持数据一致性,完整性.实现数据表的一对一或一对多的关系.这就是把MySQL称为关系型数据库的根 ...
- centos5 升级到centos6
From http://www.linuxquestions.org/questions/linux-newbie-8/yum-update-error-4175476250/ 对开发组的一个服务器执 ...