论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
Fully Convolutional Attention Localization Networks:
Efficient Attention Localization for Fine-Grained Recognition
细粒度的识别(Fine-grained recognition)的挑战性主要来自于 类内差异(inter-class differences)在细粒度类别中通常是局部的,细微的;类间差异(intra-class differences)由于姿态的变换而导致很大。为了从类间变化区分他们,放大到具有高度判别性的局部区域是非常重要的。本文提出了一种基于强化学习的全卷积注意力局部网络来自适应的选择多任务驱动的视觉注意力区域 (In this work, we introduce a reinforcement learning-based fully convolutional attention localization network to adaptively select multiple task-driven visual attention regions.) 作者的实验表明将相关区域放大处理,可以得到更好的结果,这一点就相当于我们人类看东西的时候,当全局看的不是很仔细的时候,就需要放大镜来看,从局部得到所需要的信息,从而做出进一步的判断。本文在三个数据集上做了实验,分别是:斯坦福dog, cars, CUB-200-2011。
前人的工作大多是使用手工设计的 part 来进行 fine-grained recognition。依赖于手工定义的part有几个缺点:
1. 精确的part 标注需要非常昂贵的代价;
2. 强监督的基于part的模型可能在part被遮挡时,失效;
3. 最后但也是最重要的,即:没有线索表明,手工设计的part对于所有的 fine-grained recognition tasks来说是最优的。例如:对于食物的识别来别,是非常难以设计part的。
针对以上问题,本文提出了一种框架,即:Fully Convolutional Attention Localization Network 来定位物体的part,而没有任何人工的标注。本文利用基于强化学习的视觉 attenation model 来模拟学习定位物体的part,并且在场景内进行物体分类。这个框架模拟人类视觉系统的识别过程,通过学习一个任务驱动的策略,经过一系列的 glimpse 来定位物体的part。那么,这里的 glimpse 是什么呢?每一个 glimpse 对应一个物体的part。将原始的图像以及之前glimpse 的位置作为输入,下一次 glimpse位置作为输出,作为下一次物体part。每一个 glimpse的位置作为一个 action,图像和之前glimpse的位置作为 state,奖励衡量分类的准确性。本文方法可以同时定位多个part,之前的方法只能一次定位一个part,但是仔细想想,也奇怪,既然是 attenation model,那么像人类一样,一次只能将目光注意到一个地方,只定位一个part也是正常且合理的,这里搞一个多个part的同时定位,有点不太合理。
Fully Convolutional Attention Localization Networks
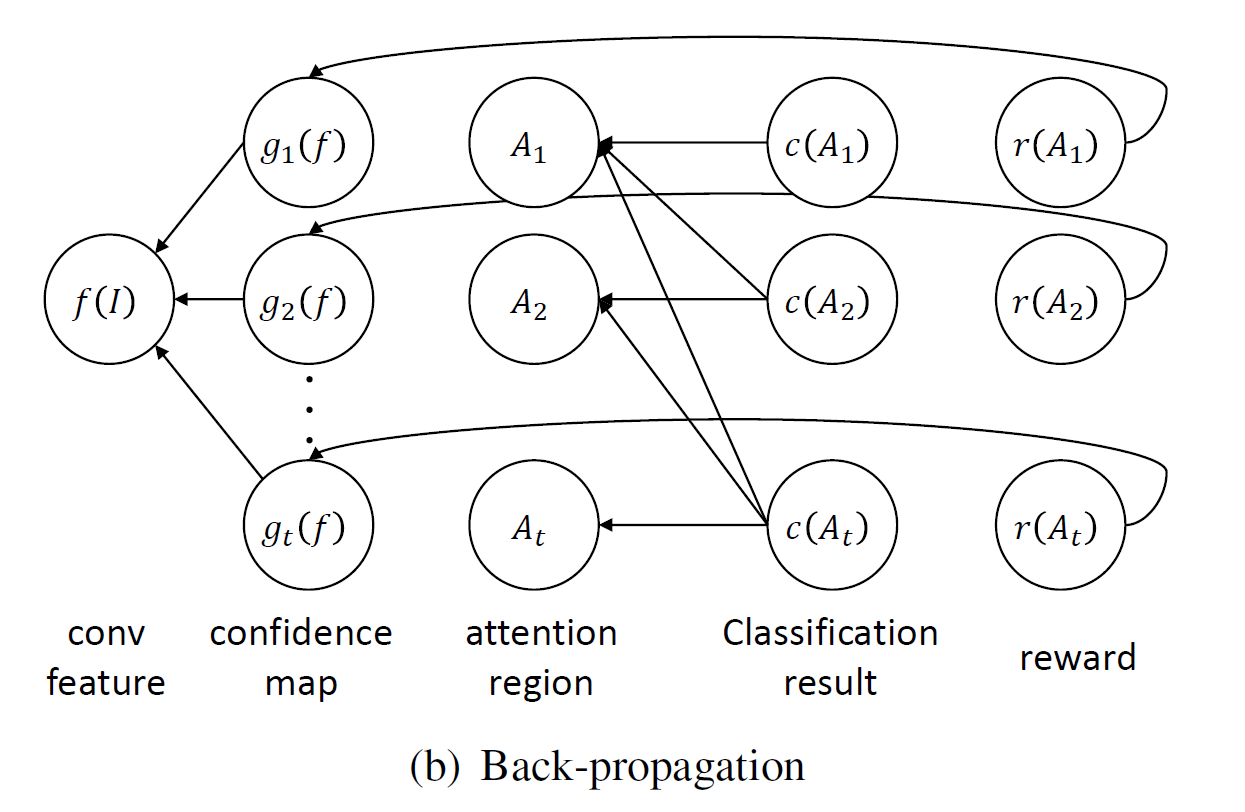
该网络结构可以借助 attention mechanism 来同时定位多个物体的part。不同的part可以拥有不同的预先定义的尺寸,主要包含两个成分:Part localization component and classification component.

定位 part的成分利用一个全卷积的神经网络来定位part的位置。给定一张输入图像,我们用 VGG-16 以及在ImageNet上训练好的model 提取基础的卷积特征映射。attention localization network 定位多个parts,利用基础的卷积特征映射对每一个part都产生一个score map。每一个score map 都是由两层累积的卷积层和一个spatial softmax layer构成。第一个卷积层利用64个3*3的kernel,第二层利用一个3*3的kernel来产生一个单通道的置信图。spatial softmax layer作用于confidence map,用来将置信得分转化为概率。拥有最高概率的 attention region 被选为part location。
分类的部分(classification component) 对于每一个part 以及 全图都给定一个CNN分类器。不同的part 可能有不同的尺寸,局部的图像区域根据其大小以及part的位置进行crop操作。我们对每一个局部图像区域和整体图像分开来进行图像分类器的训练。最终分类的效果是所有单独分类器结果的平均。为了判别出具有细微视觉不同的地方,每一个局部图像区域被resize成高分辨率的。每一个part都单独的训练一个CNN网络。
虽然resize局部图像区域可以达到很好的分类性能,但是其需要我们执行多步前向和后向传播,这是非常耗时的。所以,此处采用了估计part 分类的方法,类似于 fast-rcnn,训练过程中的卷积特征映射对于part的定位,part的分类,以及整张图像的分类都是共享的。在整幅图像的卷及特征映射上选择对应的区域,从而得到每一个part的卷积特征,所以 所选中区域的接受域是和part部分相同的。所有时间步骤的卷积特征也是共享的。所以,我们只要在一个训练batch中,执行前向传递即可。Note:这些分类网络仅仅用来在attention localization network training的时候得到奖励。最后的分类网络是基于resized 高分辨率图像。
Inference
接下来说说如何利用 attention localization network 在inference的过程中进行识别。像上图所示,给定一张图,我们首先定位多个 attention regions,通过选择每一个part 拥有最高概率的区域。
然后放大每一个part的位置,通过resize围绕它的分辨率到对应的高分辨率。每一个resize的part region 以及原本的图像利用分类part单独的进行预测。最后的预测score是原本图像的平均和所有attention region的平均。
Training Attention Localization Networks
由于并没有groundtruth来辅助进行定位 attention region,我们采用RL的方法来学习 attention localization networks。
整个attention定位问题被描述成 马尔科夫决策过程(Markov Decision Process, MDPs)。在MDP的每一步中,attenation localization network作为agent 来基于观察,执行一个action,并且得到一个reward。
在我们的工作中:
action ---> the location of the attention region;
observation ---> the input image and the crops of the attention regions;
the reward ---> measures the quality of the classification using the attention region.
我们的学习目标自然就是:学习一个最优的决策来根据观测产生动作,具体表现为 通过attention localization network的参数来最大化所有时间步骤的期望奖励的总和。
作者额外又训练了一个分类网络来衡量分类的质量。每一步的分类网络是一个全卷积网络紧跟着一个softmax layer,将最后一个timestep的所有part的attention maps 以及 整幅图像的卷积特征作为输入。
分类网络和attention localization network 联合优化来最大化接下来的目标函数:
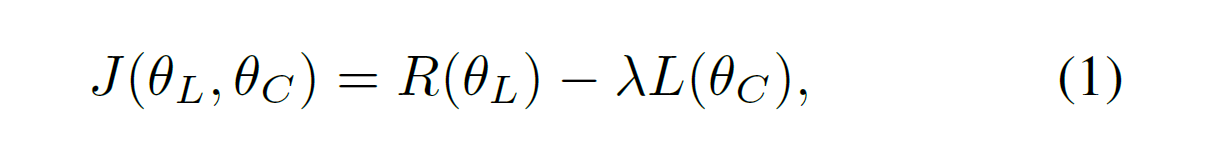
其中,θL, θC 是 attention localization network 和 classification network 的参数。注意到,我们应用L(θC)是交叉熵分类损失,R(θL)的定义是:
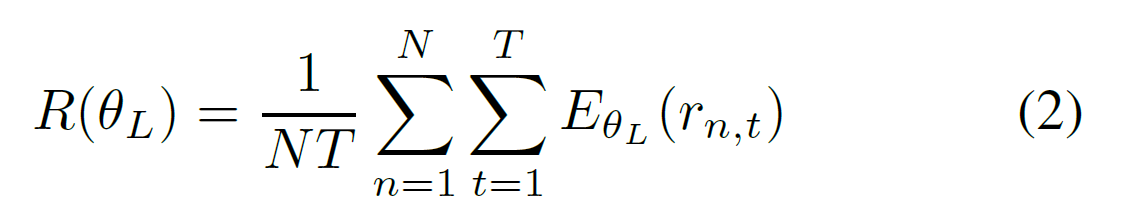
是N个训练样本的平均期望奖励 和 T个不同的选择区域。

是第n个样本的第t个选择的attention region的期望奖励。
1. Reward Strategy

像上面公式表达的那样,有两种情况可以给出奖励:
1. 第一次迭代(t=1),并且预测的结果和gt值相等,则马上给出奖励,即:Cn,1 = yn ;
2. 第t次迭代,当预测的结果和gt值相等,然后当前迭代的loss值小于前一次迭代的loss,那么也给出奖励;
否则,就不出给奖励。
其实,还有一种直观的关于reward奖赏的方法,即:从整体上,利用最终的分类结果来衡量attention region 选择策略的质量, i.e. r(An, t) = 1 如果t = T,并且当前图像被正确的分类;否则就是0.文中提到这可能会导致难以收敛的问题。
所以,作者认为当图像可以利用当前attention region 被正确分类时,就立刻给出奖励,训练时就立刻更加简单和快速的收敛。
2. Optimization

直接计算 期望的梯度有点困难,本文采用的是蒙特卡洛方法来近似计算:

attention 区域的可视化:


我的感受:
z
论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition的更多相关文章
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 论文笔记:Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Deeper and Wider Siamese Networks for Real-Time Visual TrackingUpdated on 2019-04-01 16:10:37 Paper ...
- 【论文笔记】CBAM: Convolutional Block Attention Module
CBAM: Convolutional Block Attention Module 2018-09-14 21:52:42 Paper:http://openaccess.thecvf.com/co ...
- 【论文笔记】Learning Convolutional Neural Networks for Graphs
Learning Convolutional Neural Networks for Graphs 2018-01-17 21:41:57 [Introduction] 这篇 paper 是发表在 ...
- 论文笔记:Siamese Cascaded Region Proposal Networks for Real-Time Visual Tracking
Siamese Cascaded Region Proposal Networks for Real-Time Visual Tracking 2019-03-20 16:45:23 Paper:ht ...
- 论文笔记:Learning regression and verification networks for long-term visual tracking
Learning regression and verification networks for long-term visual tracking 2019-02-18 22:12:25 Pape ...
- 论文笔记:Semantic Segmentation using Adversarial Networks
Semantic Segmentation using Adversarial Networks 2018-04-27 09:36:48 Abstract: 对于产生式图像建模来说,对抗训练已经取得了 ...
随机推荐
- SharePoint 2013 开发——APP开发的考虑和建议
博客地址:http://blog.csdn.net/FoxDave 需要考虑的方面: 1. 记得CSOM授予网站集及以下的权限,而场解决方案需要整个场的访问权限. 2. 由于应用程序是彼此完全独立 ...
- Spark的编译
由于Spark的运行环境的多样性,如可以运行在hadoop的yarn上,这样就必须要对Spark的源码进行编译.下面介绍一下Spark源码编译的详细步骤: 1.Spark的编译方式:编译的方式可以参考 ...
- 关于doctype
一:html文档类型 doctype为documentype 的简称,是在html页面中声明的XHTML或者HTML的文件类型,正确准确的文件类型的声明,才能使html标签以及CSS样式生效. 声明文 ...
- PHP+MySql字符问题原理分析
假如数据库已经设置了utf-8 ,php文件也设置了utf-8 ,但在php文件的查询语句中未添加了 mysql_query("set names utf8")语句,此时php页面 ...
- jvm之xms、xmx等参数分析
注:本文摘自http://www.cnblogs.com/mingforyou/archive/2012/03/03/2378143.html ,感谢原作者 1.参数的含义-vmargs -Xms12 ...
- (转)如何在Windows上安装多个MySQL
原文:http://www.blogjava.net/hongjunli/archive/2009/03/01/257216.html 如何在Windows上安装多个MySQL 本文以免安装版的mys ...
- RAID-4与模2和
在网络传输和磁盘数据管理中经常涉及到的所谓奇偶校验:每N个bit之后加上一个bit保证这N + 1bit的模2和为0(也叫异或,一个意思) 而如果这其中出现了单bit错, 直接导致校验出差,出现偶数b ...
- UIKit框架之UIlabel
1.继承链:UIview:UIresponder:NSObject 2.如果你想要使UIlabel能够和用户进行互动,需要把它实例变量的属性 userInteractionEnabled改为yes 3 ...
- css中的列表属性
list-style-type设定引导列表的符号类型,可以设置多种符号类型,值为disc.circle.square等 list-style-image使用图像作为定制列表的符号 list-style ...
- 10、SQL基础整理(约束2)
约束 除主键约束.外键约束外 唯一约束(主键列.索引列的候选索引) 设计---右键---索引/键---需要修改的列----是唯一的----忽略重复键 代码方式: cid varchar (20) ...