使用Hystrix提高系统可用性
今天稍微复杂点的互联网应用,服务端基本都是分布式的,大量的服务支撑起整个系统,服务之间也难免有大量的依赖关系,依赖都是通过网络连接起来。
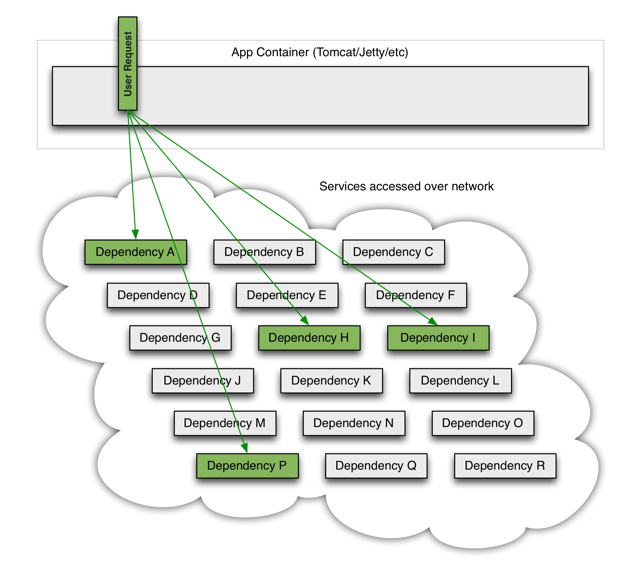
(图片来源:https://github.com/Netflix/Hystrix/wiki)
然而任何一个服务的可用性都不是 100% 的,网络亦是脆弱的。当我依赖的某个服务不可用的时候,我自身是否会被拖死?当网络不稳定的时候,我自身是否会被拖死?这些在单机环境下不太需要考虑的问题,在分布式环境下就不得不考虑了。假设我有5个依赖的服务,他们的可用性都是99.95%,即一年不可用时间约为4个多小时,那么是否意味着我的可用性最多就是 99.95% 的5次方,99.75%(近乎一天),再加上网络不稳定因素、依赖服务可能更多,可用性会更低。考虑到所依赖的服务必定会在某些时间不可用,考虑到网络必定会不稳定,我们应该怎么设计自身服务?即,怎么为出错设计?
Michael T. Nygard 在在精彩的《Release It!》一书中总结了很多提高系统可用性的模式,其中非常重要的两条是:
- 使用超时
- 使用断路器
第一条,通过网络调用外部依赖服务的时候,都必须应该设置超时。在健康的情况下,一般局域往的一次远程调用在几十毫秒内就返回了,但是当网络拥堵的时候,或者所依赖服务不可用的时候,这个时间可能是好多秒,或者压根就僵死了。通常情况下,一次远程调用对应了一个线程或者进程,如果响应太慢,或者僵死了,那一个进程/线程,就被拖死,短时间内得不到释放,而进程/线程都对应了系统资源,这就等于说我自身服务资源会被耗尽,导致自身服务不可用。假设我的服务依赖于很多服务,其中一个非核心的依赖如果不可用,而且没有超时机制,那么这个非核心依赖就能拖死我的服务,尽管理论上即使没有它我在大部分情况还能健康运转的。
断路器其实我们大家都不陌生(你会换保险丝么?),如果你家没有断路器,当电流过载,或者短路的时候,电路不断开,电线就会升温,造成火灾,烧掉房子。有了断路器之后,电流过载的时候,保险丝就会首先烧掉,断开电路,不至于引起更大的灾难(只不过这个时候你得换保险丝)。

当我们的服务访问某项依赖有大量超时的时候,再让新的请求去访问已经没有太大意义,那只会无谓的消耗现有资源。即使你已经设置超时1秒了,那明知依赖不可用的情况下再让更多的请求,比如100个,去访问这个依赖,也会导致100个线程1秒的资源浪费。这个时候,断路器就能帮助我们避免这种资源浪费,在自身服务和依赖之间放一个断路器,实时统计访问的状态,当访问超时或者失败达到某个阈值的时候(如50%请求超时,或者连续20次请失败),就打开断路器,那么后续的请求就直接返回失败,不至于浪费资源。断路器再根据一个时间间隔(如5分钟)尝试关闭断路器(或者更换保险丝),看依赖是否恢复服务了。
超时机制和断路器能够很好的保护我们的服务,不受依赖服务不可用的影响太大,具体可以参看文章《 使用熔断器设计模式保护软件》。然而具体实现这两个模式还是有一定的复杂度的,所幸 Netflix 开源的 Hystrix框架 帮我们大大简化了超时机制和断路器的实现,Hystrix:供分布式系统使用,提供延迟和容错功能,隔离远程系统、访问和第三方程序库的访问点,防止级联失败,保证复杂的分布系统在面临不可避免的失败时,仍能有其弹性。在Codeplex上有一个.NET的移植版本https://hystrixnet.codeplex.com/ 。
使用Hystrix,需要通过Command封装对远程依赖的调用:
public class GetCurrentTimeCommand : HystrixCommand<long>
{
private static long currentTimeCache;
public GetCurrentTimeCommand()
: base(HystrixCommandSetter.WithGroupKey("TimeGroup")
.AndCommandKey("GetCurrentTime")
.AndCommandPropertiesDefaults(new HystrixCommandPropertiesSetter().WithExecutionIsolationThreadTimeout(TimeSpan.FromSeconds(1.0)).WithExecutionIsolationThreadInterruptOnTimeout(true)))
{
}
protected override long Run()
{
using (WebClient wc = new WebClient())
{
string content = wc.DownloadString("http://tycho.usno.navy.mil/cgi-bin/time.pl");
XDocument document = XDocument.Parse(content);
currentTimeCache = long.Parse(document.Element("usno").Element("t").Value);
return currentTimeCache;
}
}
protected override long GetFallback()
{
return currentTimeCache;
}
}
然后在需要的时候调用这个Command:
GetCurrentTimeCommand command = new GetCurrentTimeCommand();
long currentTime = command.Execute();
上述是同步调用,当然如果业务逻辑允许且更追求性能,或许可以选择异步调用:
该例中,不论 WebClient. DownloadString () 自身有没有超时机制(可能你会发现很多远程调用接口自身并没有给你提供超时机制),用 HystrixCommand 封装过后,超时是强制的,默认超时时间是1秒,当然你可以根据需要自己在构造函数中调节 Command 的超时时间,例如说2秒:
HystrixCommandSetter.WithGroupKey("TimeGroup")
.AndCommandKey("GetCurrentTime")
.AndCommandPropertiesDefaults(new HystrixCommandPropertiesSetter().WithExecutionIsolationThreadTimeout(TimeSpan.FromSeconds(2.0)).WithExecutionIsolationThreadInterruptOnTimeout(true))
当Hystrix执行命令超时后,Hystrix 执行命令超时或者失败之后,是会尝试去调用一个 fallback 的,这个 fallback 即一个备用方案,要为 HystrixCommand 提供 fallback,只要重写 protected virtual R GetFallback()方法即可。
一般情况下,Hystrix 会为 Command 分配专门的线程池,池中的线程数量是固定的,这也是一个保护机制,假设你依赖很多个服务,你不希望对其中一个服务的调用消耗过多的线程以致于其他服务都没线程调用了。默认这个线程池的大小是10,即并发执行的命令最多只能有是个了,超过这个数量的调用就得排队,如果队伍太长了(默认超过5),Hystrix就立刻走 fallback 或者抛异常。
根据你的具体需要,你可能会想要调整某个Command的线程池大小,例如你对某个依赖的调用平均响应时间为200ms,而峰值的QPS是200,那么这个并发至少就是 0.2 x 200 = 40 (Little's Law),考虑到一定的宽松度,这个线程池的大小设置为60可能比较合适:
public GetCurrentTimeCommand()
: base(HystrixCommandSetter.WithGroupKey("TimeGroup")
.AndCommandKey("GetCurrentTime")
.AndCommandPropertiesDefaults(new HystrixCommandPropertiesSetter().WithExecutionIsolationThreadTimeout(TimeSpan.FromSeconds(1.0)).WithExecutionIsolationThreadInterruptOnTimeout(true))
.AndThreadPoolPropertiesDefaults(new HystrixThreadPoolPropertiesSetter().WithCoreSize(60) // size of thread pool
.WithKeepAliveTime(TimeSpan.FromMinutes(1.0)) // minutes to keep a thread alive (though in practice this doesn't get used as by default we set a fixed size)
.WithMaxQueueSize(100) // size of queue (but we never allow it to grow this big ... this can't be dynamically changed so we use 'queueSizeRejectionThreshold' to artificially limit and reject)
.WithQueueSizeRejectionThreshold(10) // number of items in queue at which point we reject (this can be dyamically changed)
.WithMetricsRollingStatisticalWindow(10000) // milliseconds for rolling number
.WithMetricsRollingStatisticalWindowBuckets(10)))
{
}
说了这么多,还没提到Hystrix的断路器,其实对于使用者来说,断路器机制默认是启用的,但是编程接口默认几乎不需要关心这个,机制和前面讲的也差不多,Hystrix会统计命令调用,看其中失败的比例,默认当超过50%失败后,开启断路器,那之后一段时间的命令调用直接返回失败(或者走fallback),5秒之后,Hystrix再尝试关闭断路器,看看请求是否能正常响应。下面的几行Hystrix源码展示了它如何统计失败率的:
public HealthCounts GetHealthCounts()
{
// we put an interval between snapshots so high-volume commands don't
// spend too much unnecessary time calculating metrics in very small time periods
long lastTime = this.lastHealthCountsSnapshot;
long currentTime = ActualTime.CurrentTimeInMillis;
if (currentTime - lastTime >= this.properties.MetricsHealthSnapshotInterval.Get().TotalMilliseconds || this.healthCountsSnapshot == null)
{
if (Interlocked.CompareExchange(ref this.lastHealthCountsSnapshot, currentTime, lastTime) == lastTime)
{
// our thread won setting the snapshot time so we will proceed with generating a new snapshot
// losing threads will continue using the old snapshot
long success = counter.GetRollingSum(HystrixRollingNumberEvent.Success);
long failure = counter.GetRollingSum(HystrixRollingNumberEvent.Failure); // fallbacks occur on this
long timeout = counter.GetRollingSum(HystrixRollingNumberEvent.Timeout); // fallbacks occur on this
long threadPoolRejected = counter.GetRollingSum(HystrixRollingNumberEvent.ThreadPoolRejected); // fallbacks occur on this
long semaphoreRejected = counter.GetRollingSum(HystrixRollingNumberEvent.SemaphoreRejected); // fallbacks occur on this
long shortCircuited = counter.GetRollingSum(HystrixRollingNumberEvent.ShortCircuited); // fallbacks occur on this
long totalCount = failure + success + timeout + threadPoolRejected + shortCircuited + semaphoreRejected;
long errorCount = failure + timeout + threadPoolRejected + shortCircuited + semaphoreRejected;
healthCountsSnapshot = new HealthCounts(totalCount, errorCount); }
}
return healthCountsSnapshot;
}
其中 failure 表示命令本身发生错误、success 自然不必说,timeout 是超时、threadPoolRejected 表示当线程池满后拒绝的命令调用、shortCircuited 表示断路器打开后拒绝的命令调用,semaphoreRejected 使用信号量机制(而不是线程池)拒绝的命令调用。
分布式服务弹性框架"Hystrix"实践与源码研究(一)
使用Hystrix提高系统可用性的更多相关文章
- Hystrix提高系统可用性
使用Hystrix提高系统可用性 今天稍微复杂点的互联网应用,服务端基本都是分布式的,大量的服务支撑起整个系统,服务之间也难免有大量的依赖关系,依赖都是通过网络连接起来. (图片来源:https:// ...
- 深入理解SpringCloud与微服务构建学习总结
说明:用时 from 2018-11-16 to 2018-11-23 七天 0 放在前面 什么是微服务? 微服务是一个分布式系统.微服务架构的风格,就是将单一程序开发成一个微服务,每个微服务 ...
- 【转】Java面试题全集2.2(下)
154.如何在Web项目中配置Spring的IoC容器? 答:如果需要在Web项目中使用Spring的IoC容器,可以在Web项目配置文件web.xml中做出如下配置: <context-par ...
- Hadoop原理介绍
Hadoop核心之HDFS 架构设计 老嗨 2015-09-18 16:55:00 浏览225 评论0 摘要: 概述:HDFS即Hadoop Distributed File System分布式文 ...
- 自动检查点(Automatic Checkpointing)
自动检查点(Automatic Checkpointing)在oracle10g,支持自动检查点调优,这样可以提高系统可用性.自动检查点调优需要开启参数fast_start_mttr_target. ...
- Spring JDBC主从数据库配置
通过昨天学习的自定义配置注释的知识,探索了解一下web主从数据库的配置: 背景:主从数据库:主要是数据上的读写分离: 数据库的读写分离的好处? 1. 将读操作和写操作分离到不同的数据库上,避免主服务器 ...
- 转:基于TLS1.3的微信安全通信协议mmtls介绍
转自: https://mp.weixin.qq.com/s?__biz=MzAwNDY1ODY2OQ==&mid=2649286266&idx=1&sn=f5d049033e ...
- (转)基于Redis Sentinel的Redis集群(主从&Sharding)高可用方案
转载自:http://warm-breeze.iteye.com/blog/2020413 本文主要介绍一种通过Jedis&Sentinel实现Redis集群高可用方案,该方案需要使用Jedi ...
- 恒天云IaaS基础设施标准
系统总体要求: 支持多种操作系统:支持Windows,Redhat.Suse等Linux操作系统: 支持多种虚拟化系统:支持多种计算资源虚拟化方式: 网络接口:支持千兆及万兆以太网技术: 供电:支持直 ...
随机推荐
- java EE设计模式简介
1.何为设计模式 设计模式提供了对常见应用设计问题的解决方案.在面向对象的编程中,设计模式通常在解决与对象创建和交互相关的问题,而非整体软件架构所面对的大规模问题,它们以样板代码的形式提供了通用的解决 ...
- Oracle Database 12c Data Redaction介绍
什么是Data Redaction Data Redaction是Oracle Database 12c的高级安全选项之中的一个新功能,Oracle中国在介绍这个功能的时候,翻译为“数据编纂”,在EM ...
- 主成分分析(PCA)原理总结
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一.在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用.一般我们提到降维最容易想到的算法就 ...
- angular 源码分析 1 - angularInit()
angularjs 是个神奇的框架,由于我的好奇,想了解她的内部工作原理,只能一步一步的走进她,靠近她,和她深入的交流. angularjs 的入口是什么样子的呢?一起掀起她的盖头吧. 在这里我只讲方 ...
- ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存
ASP.Net MVC4+Memcached+CodeFirst实现分布式缓存 part 1:给我点时间,允许我感慨一下2016年 正好有时间,总结一下最近使用的一些技术,也算是为2016年画上一个完 ...
- ES6之变量常量字符串数值
ECMAScript 6 是 JavaScript 语言的最新一代标准,当前标准已于 2015 年 6 月正式发布,故又称 ECMAScript 2015. ES6对数据类型进行了一些扩展 在js中使 ...
- Oracle-BPM安装详解
H3 BPM安装包括两个部分,基础工作包括安装IIS..net Freamwork基础框架.安装完成之后,主要配置安装包括数据库,H3 BPM 程序.下面详细介绍Oracle与H3 BPM对接安装的整 ...
- Android—简单的仿QQ聊天界面
最近仿照QQ聊天做了一个类似界面,先看下界面组成(画面不太美凑合凑合呗,,,,):
- 深入理解 Android 之 View 的绘制流程
概述 本篇文章会从源码(基于Android 6.0)角度分析Android中View的绘制流程,侧重于对整体流程的分析,对一些难以理解的点加以重点阐述,目的是把View绘制的整个流程把握好,而对于特定 ...
- Android 添加ActionBar Buttons
一.在res/menu文件夹下创建Xml文件 跟标签为menu,设置item <?xml version="1.0" encoding="utf-8"?& ...