Java_一致性哈希算法与Java实现
摘自:http://blog.csdn.net/wuhuan_wp/article/details/7010071
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
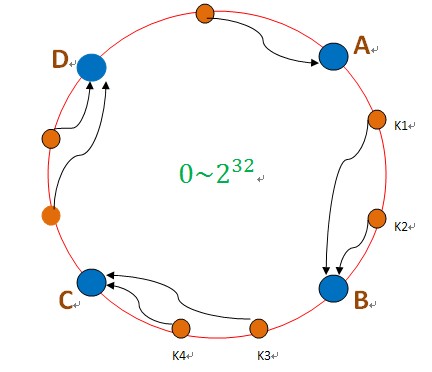
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
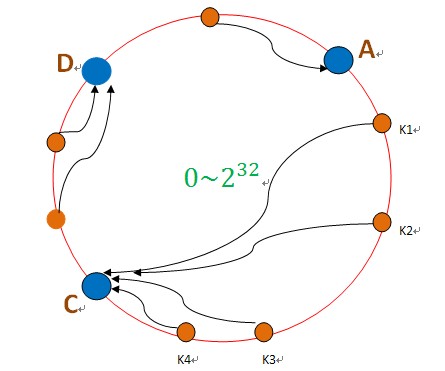
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
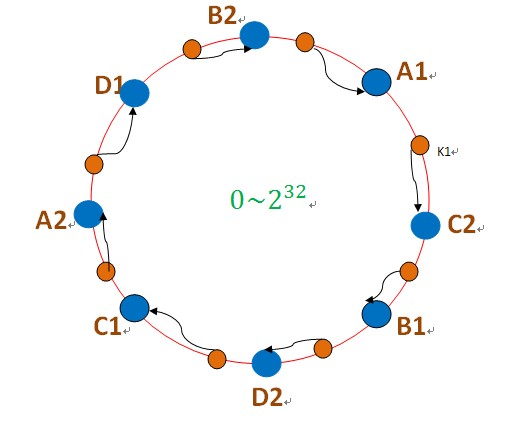
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
Java实现:
- public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
- private TreeMap<Long, S> nodes; // 虚拟节点
- private List<S> shards; // 真实机器节点
- private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
- private void init() { // 初始化一致性hash环
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
- final S shardInfo = shards.get(i);
- for (int n = 0; n < NODE_NUM; n++)
- // 一个真实机器节点关联NODE_NUM个虚拟节点
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
- }
- }
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
- }
- /**
- * MurMurHash算法,是非加密HASH算法,性能很高,
- * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
- * 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
- * http://murmurhash.googlepages.com/
- */
- private Long hash(String key) {
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
- long h = seed ^ (buf.remaining() * m);
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
- k *= m;
- k ^= k >>> r;
- k *= m;
- h ^= k;
- h *= m;
- }
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
- // for big-endian version, do this first:
- // finish.position(8-buf.remaining());
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
- buf.order(byteOrder);
- return h;
- }
- }
Java_一致性哈希算法与Java实现的更多相关文章
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- 负载均衡-基础-一致性哈希算法及java实现
一致性hash算法,参考: http://www.blogjava.net/hello-yun/archive/2012/10/10/389289.html 针对这篇文章,加入了自己的理解,在原有的代 ...
- 一致性哈希算法(consistent hashing)(转)
原文链接:每天进步一点点——五分钟理解一致性哈希算法(consistent hashing) 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- 一致性哈希算法原理及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 一致性哈希算法原理、避免数据热点方法及Java实现
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的简 单 ...
- 一致性哈希算法——算法解决的核心问题是当slot数发生变化时,能够尽量少的移动数据
一致性哈希算法 摘自:http://blog.codinglabs.org/articles/consistent-hashing.html 算法简述 一致性哈希算法(Consistent Hashi ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
- 一致性哈希算法(Consistent Hashing) .
应用场景 这里我先描述一个极其简单的业务场景:用4台Cache服务器缓存所有Object. 那么我将如何把一个Object映射至对应的Cache服务器呢?最简单的方法设置缓存规则:object.has ...
随机推荐
- Hbuilder连接模拟器调试
Hbuilder是一个非常好用的HTML5开发IDE,我最喜欢的功能就是连接手机调试了,连接手机调试有两种途径,一是通过USB连接真机,二是下载安装一个安卓模拟器,让Hbuilder连接到安卓模拟器, ...
- 第十八篇:在SOUI中实现PreTranslateMessage
在MFC中,通常可以通过重载CWnd::PreTranslateMessage这样一个虚函数来实现对一些窗口消息的预处理.多用于tooltip的显示控制. 在SOUI中也实现了类似的机制. 要在SOU ...
- Android之Adapter用法总结-(转)
Android之Adapter用法总结 1.概念 Adapter是连接后端数据和前端显示的适配器接口,是数据和UI(View)之间一个重要的纽带.在常见的View(List View,Grid Vie ...
- hbase伪分布式安装(转)
原文地址:http://blog.csdn.net/yonghutwo/article/details/24555103 本机环境: ubuntu 12.4 Hadoop 1.1.2 安装hbase版 ...
- JQ学习(三)-ajax
jQuery - AJAX jQuery load() 方法 jQuery load() 方法是简单但强大的 AJAX 方法. load() 方法从服务器加载数据,并把返回的数据放入被选元素中. 语法 ...
- loopback 03
使用微信开发前准备 微信公众开发者平台 注册开发者账号获取权限: 安装包: wechat, wechat-oauth 微信公众平台操作 登录之后,得到appID和appsecret 根据appID和a ...
- DOM--6 向应用程序中加入ajax
组合技术 适当的ajax时对已有技术和下列思想的组合 语义化(X)HTML标记 文档对象模型(DOM) JavaScript XML 不同浏览器中,公共XMLHttpRequest方法 open(me ...
- BZOJ 1901 Zju2112 Dynamic Rankings ——树状数组套主席树
[题目分析] BZOJ这个题目抄的挺霸气. 主席树是第一时间想到的,但是修改又很麻烦. 看了别人的题解,原来还是可以用均摊的思想,用树状数组套主席树. 学到了新的姿势,2333o(* ̄▽ ̄*)ブ [代 ...
- js运动框架tween
<!DOCTYPE html> <html> <head> <title>myAnimate</title> <style> * ...
- TStringList 常用操作
//TStringList 常用方法与属性: var List: TStringList; i: Integer; begin List := TStringList.Create; ...