TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,互联网上的搜索引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
F-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 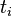 来说,它的重要性可表示为:
来说,它的重要性可表示为:
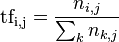
以上式子中  是该词在文件
是该词在文件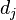 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
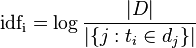
其中
- |D|:语料库中的文件总数
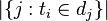 :包含词语的文件数目(即
:包含词语的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用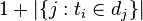
然后

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TF-IDF的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
随机推荐
- Android getevent
详细用法如下: 源码复制打印? Usage: getevent [-t] [-n] [-s switchmask] [-S] [-v [mask]] [-d] [-p] [-i] [-l] [-q] ...
- Linux network driver
一.常见问题 1)2.6.32内核不兼容I219网卡 http://exxactcorp.com/blog/how-to-installconfigure-intel-i219-network-ada ...
- 理解 QEMU/KVM 和 Ceph(2):QEMU 的 RBD 块驱动(block driver)
本系列文章会总结 QEMU/KVM 和 Ceph 之间的整合: (1)QEMU-KVM 和 Ceph RBD 的 缓存机制总结 (2)QEMU 的 RBD 块驱动(block driver) (3)存 ...
- AI (Adobe Illustrator)详细用法(二)
本文主要是介绍形状的创建与编辑. 一.系列形状工具 1.矩形工具 矩形的作用很大,比如输入框,按钮,图片的大小,比如相片应用中每一个照片占的比例是多大. 初步的UI图的话,会画矩形和圆角矩形就够了. ...
- [麦先生]TP3.2之微信开发那点事[基础篇](微信支付签名算法)
两种模式:扫码支付和微信内支付(调用js-sdk) trade_type==native即扫码支付,只需要将code_url转成二维码,使用微信扫码即可: js-sdk微信内支付-调用微信js-sdk ...
- NOIP2009 提高组T3 机器翻译 解题报告-S.B.S
题目背景 小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章. 题目描述 这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换.对于每个英文单词,软件会先 ...
- Codeforces 549C. The Game Of Parity[博弈论]
C. The Game Of Parity time limit per test 1 second memory limit per test 256 megabytes input standar ...
- jprofiler安装图解
环境: 1.sun jdk1.6.0 2.jprofiler_windows_6_0_2.exe 安装 1. jdk, 安装略... 2. jprofiler安装 一路next 到Enter lice ...
- Eclipse代码追踪功能说明
在使用Java编写复杂一些的程序时,你会不会常常对一层层的继承关系和一次次方法的调用感到迷惘呢?幸亏我们有了Eclipse这么好的IDE可以帮我们理清头绪--这就要使用Eclipse强大的代码追踪功能 ...
- 开发之UI篇
首先这里介绍一个软件一个插件,它们的主要功能是方便开发者看UI(如尺寸,颜色,大小等),两个配合使用 一. Sketch软件 1.Sketch 看ui图,还可以切图 2.Sketch 如何切图: 1 ...