大数据SQL中的Join谓词下推,真的那么难懂?
听到谓词下推这个词,是不是觉得很高大上,找点资料看了半天才能搞懂概念和思想,借这个机会好好学习一下吧。
引用范欣欣大佬的博客中写道,以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白的很真切。这里拿出来和大家交流交流。个人认为谓词下推有两个层面的理解:
其一是逻辑执行计划优化层面的说法,比如SQL语句:select * from order ,item where item.id = order.item_id and item.category = ‘book’,正常情况语法解析之后应该是先执行Join操作,再执行Filter操作。通过谓词下推,可以将Filter操作下推到Join操作之前执行。即将where item.category = ‘book’下推到 item.id = order.item_id之前先行执行。
其二是真正实现层面的说法,谓词下推是将过滤条件从计算进程下推到存储进程先行执行,注意这里有两种类型进程:计算进程以及存储进程。计算与存储分离思想,这在大数据领域相当常见,比如最常见的计算进程有SparkSQL、Hive、impala等,负责SQL解析优化、数据计算聚合等,存储进程有HDFS(DataNode)、Kudu、HBase,负责数据存储。正常情况下应该是将所有数据从存储进程加载到计算进程,再进行过滤计算。谓词下推是说将一些过滤条件下推到存储进程,直接让存储进程将数据过滤掉。这样的好处显而易见,过滤的越早,数据量越少,序列化开销、网络开销、计算开销这一系列都会减少,性能自然会提高。
谓词下推 Predicate Pushdown(PPD):简而言之,就是在不影响结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
PPD 配置
PPD控制参数:hive.optimize.ppd,默认值:true
PPD规则:
| Preserved Row tables | Null Supplying tables | |
|---|---|---|
| Join Predicate | Case J1: Not Pushed | Case J2: Pushed |
| Where Predicate | Case W1: Pushed | Case W2: Not Pushed |
Push:谓词下推,可以理解为被优化
Not Push:谓词没有下推,可以理解为没有被优化
实验
实验结果列表形式:
| Pushed or Not | SQL |
|---|---|
| Pushed | select ename,dept_name from E join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Pushed | select ename,dept_name from E join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Pushed | select ename,dept_name from E join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Pushed | select ename,dept_name from E join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Not Pushed | select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Pushed | select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Pushed | select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Not Pushed | select ename,dept_name from E left outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Pushed | select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Not Pushed | select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Not Pushed | select ename,dept_name from E right outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Pushed | select ename,dept_name from E right outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
| Not Pushed | select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001'); |
| Not Pushed | select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where E.eid='HZ001'; |
| Not Pushed | select ename,dept_name from E full outer join D on ( E.dept_id = D.dept_id and D.dept_id='D001'); |
| Not Pushed | select ename,dept_name from E full outer join D on E.dept_id = D.dept_id where D.dept_id='D001'; |
实验结果表格形式:
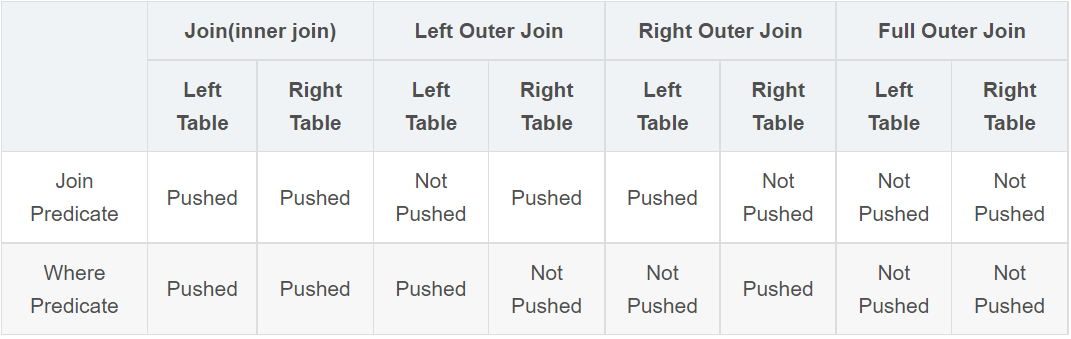
此表实际上就是上述PPD规则表。
结论
1、对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别;
2、对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
3、对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;
4、当条件分散在两个表时,谓词下推可按上述结论2和3自由组合,情况如下:
| SQL | 过滤时机 |
|---|---|
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001' and D.dept_id = 'D001'); |
dept_id在map端过滤,eid在reduce端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and D.dept_id = 'D001') where E.eid='HZ001'; |
dept_id,eid都在map端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id and E.eid='HZ001') where D.dept_id = 'D001'; |
dept_id,eid都在reduce端过滤 |
select ename,dept_name from E left outer join D on ( E.dept_id = D.dept_id ) where E.eid='HZ001' and D.dept_id = 'D001'; |
dept_id在reduce端过滤,eid在map端过滤 |
注意:如果在表达式中含有不确定函数,整个表达式的谓词将不会被pushed,例如
select a.*
from a join b on a.id = b.id
where a.ds = '2019-10-09' and a.create_time = unix_timestamp();
因为unix_timestamp是不确定函数,在编译的时候无法得知,所以,整个表达式不会被pushed,即ds='2019-10-09'也不会被提前过滤。类似的不确定函数还有rand()等。
参考文献:
[1] https://cwiki.apache.org/confluence/display/Hive/OuterJoinBehavior
引用:https://blog.csdn.net/strongyoung88/article/details/81156271
猜你喜欢
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个
大数据SQL中的Join谓词下推,真的那么难懂?的更多相关文章
- SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 . Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景. Join背景介 ...
- 最强最全面的大数据SQL经典面试题(由31位大佬共同协作完成)
本套SQL题的答案是由许多小伙伴共同贡献的,1+1的力量是远远大于2的,有不少题目都采用了非常巧妙的解法,也有不少题目有多种解法.本套大数据SQL题不仅题目丰富多样,答案更是精彩绝伦! 注:以下参考答 ...
- 开发一个不需要重写成Hive QL的大数据SQL引擎
摘要:开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL. 本文分享自华为云社区< ...
- SQL中inner join、outer join和cross join的区别
对于SQL中inner join.outer join和cross join的区别简介:现有两张表,Table A 是左边的表.Table B 是右边的表.其各有四条记录,其中有两条记录name是相同 ...
- SQL中关于Join、Inner Join、Left Join、Right Join、Full Join、On、 Where区别
前言: 今天主要的内容是要讲解SQL中关于Join.Inner Join.Left Join.Right Join.Full Join.On. Where区别和用法,不用我说其实前面的这些基本SQL语 ...
- 【转载】SQL中inner join、outer join和cross join的区别
对于SQL中inner join.outer join和cross join的区别很多人不知道,我也是别人问起,才查找资料看了下,跟自己之前的认识差不多, 如果你使用join连表,缺陷的情况下是inn ...
- LINQ TO SQL 中的join(转帖)
http://www.cnblogs.com/ASPNET2008/archive/2008/12/21/1358152.html join对于喜欢写SQL的朋友来说还是比较实用,也比较容易接受的东西 ...
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- sql中的join
首先准备数据 有以下数据,三张表:role(角色表).hero(英雄表).skill(技能表),我们以英雄联盟的数据做示例 一个hero对应一个role(我们这里暂定) 一个role可以对应多个her ...
随机推荐
- Python+selenium自动化生成测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- 产生UUID随机字符串工具类
产生UUID随机字符串工具类 UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的.通常平台会提供生成的API.按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址. ...
- 实现线程按顺序输出ABC
线程按顺序输出ABC 实现描述:建立三个线程A.B.C,分别按照顺序输出十次ABC 首先建立一个方法,按照条件进行输出 class PrintABC{ private int index=0; pub ...
- stm32-HAL使用usart发送中断判断发送标志库问题
前言: stm32是嵌入式MCU开发中最多应用的芯片,很早之前我们开发ST芯一般都是标准库开发,标准库简洁好读,现在要配合CubeMX生成代码,所以官方主推HAL库和LL库,但是HAL代码冗杂很绕,因 ...
- Xcode相关
Xcode相关的路径 Provisioning Profiles存放路径:~/Library/MobileDevice/Provisioning Profiles 所有模拟器(包括历史模拟器):~/L ...
- 函数式编程 —— 将 JS 方法函数化
前言 JS 调用方法的风格为 obj.method(...),例如 str.indexOf(...),arr.slice(...).但有时出于某些目的,我们不希望这种风格.例如 Node.js 的源码 ...
- GDP区域分布图的生成与对比(ArcPy实现)
一.背景 各地区经济协调发展是保证国民经济健康持续稳定增长的关键.GDP是反映各地区经济发展状况的重要指标.科学准确分析各地区GDP空间分布特征,对制定有效措施,指导经济协调发展具有重要参考价值. 二 ...
- springcloud整合config组件
config组件 config组件支持两种配置文件获取方式springcould搭建的微服务的配置文件的获取方式有两种.它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中或者本地 ...
- 利用 CSS Overview 面板重构优化你的网站
本文将向大家介绍 Chrome 87 开始支持的 CSS Overview Panel,并且介绍如何更好地利用这个面板.通过 CSS Overview Panel,可能可以帮助我们: 更准确(高保真) ...
- Java中的函数式编程(二)函数式接口Functional Interface
写在前面 前面说过,判断一门语言是否支持函数式编程,一个重要的判断标准就是:它是否将函数看做是"第一等公民(first-class citizens)".函数是"第一等公 ...