python11文件读写模块
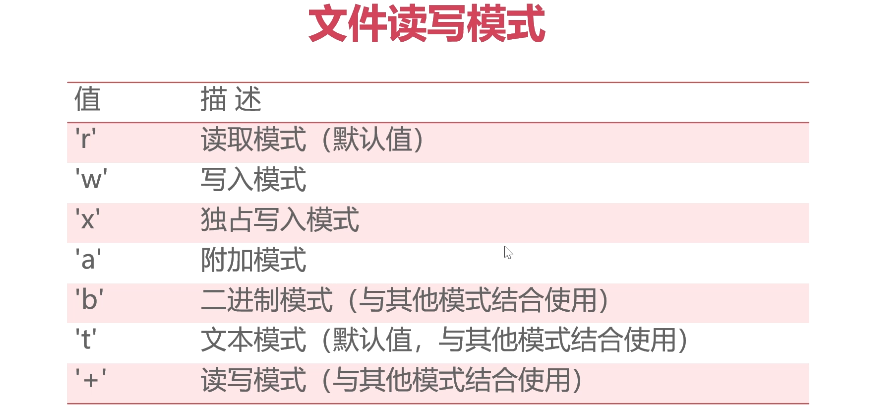


将文件的打开和关闭,交给上下文管理工具with去实现。
def read_file():
"""
读取文件
:return:
"""
file_path1 = 'D:\\PycharmProjects\\p1\\text.txt'
file_path2 = 'D:/PycharmProjects/p1/text.txt'
#普通读取
f = open(file_path1,encoding='utf-8')
#rest = f.read()
###############################
#读取指定的内容
###他不会从头开始读取,而是延续上一次读取的位置进行读取
rest = f.read(10)
print(rest)
print("@@@@@@@@@@@@@@@@")
rest = f.read(20)
print(rest)
print("@@@@@@@@@@@@@@@@")
rest = f.read()
print(rest)
##############################
f.close()
if __name__ == "__main__":
read_file() jieguo :
【发文说明】
博客园
@@@@@@@@@@@@@@@@
是面向开发者的知识分享社区,不允许发布任
@@@@@@@@@@@@@@@@
何推广、广告、政治方面的内容。
博客园首页(即网站首页)只能发布原创的、高质量的、能让读者从中学到东西的内容。
如果博文质量不符合首页要求,会被工作人员移出首页,望理解。如有疑问,请联系contact@cnblogs.com。
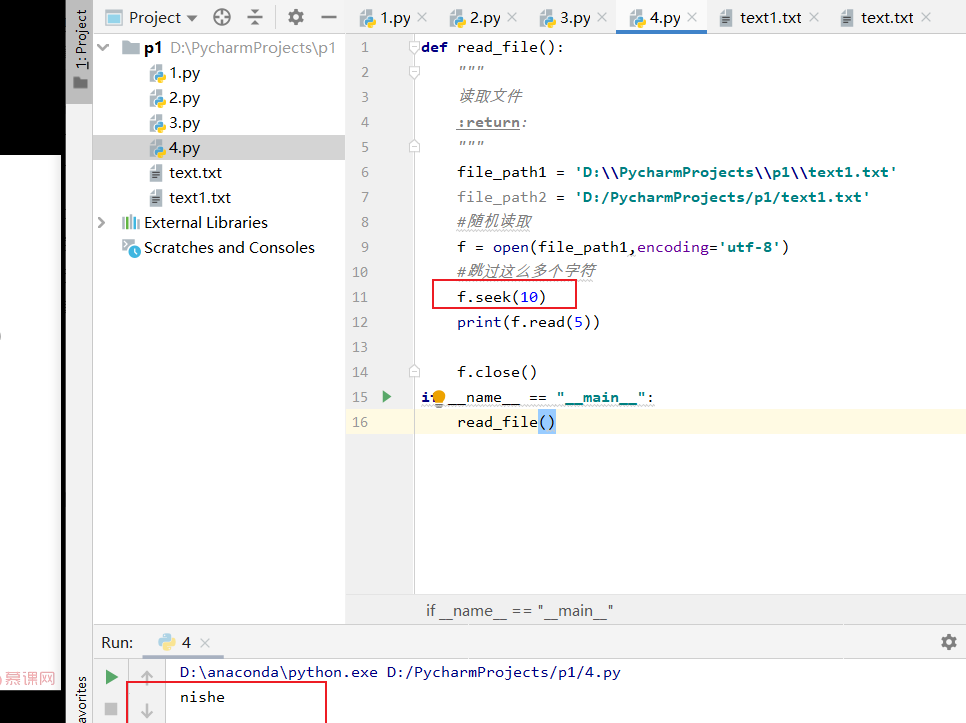
def read_file():
"""
读取文件
:return:
"""
file_path1 = 'D:\\PycharmProjects\\p1\\text1.txt'
file_path2 = 'D:/PycharmProjects/p1/text1.txt'
#随机读取
f = open(file_path1,encoding='utf-8')
#跳过这么多个字符
#f.seek(10)
#print(f.read(5))
#rest = f.readline()
# print(rest)
#print(f.readline())#接着上一次读取继续读取
# print(f.readline()) #读取所有的行,返回列表:
rest = f.readlines()
print(rest) f.close()
if __name__ == "__main__":
read_file() jeiguo :
['Process finished with exit code 0\n', 'finished with exit code\n', '\n', 'finished with exit\n', '\n', 'finished with exit code\n']
import random
from datetime import datetime def w_f():
"""
写入文件
:return:
"""
file_name = 'D:/PycharmProjects/p1/text1.txt' f = open(file_name,'w')
f.write("quanzhiqiang")
f.write("\n")
f.write("QQQQ")
f.close()
def w_m_f():
file_name = "D:/PycharmProjects/p1/text1.txt"
with open(file_name,"w",encoding='utf-8') as f:
l = ["11111","2222222","3333"]
f.writelines(l) def w_u_l():
rest = "用户:{}-访问时间:{}\n".format(random.randint(1000,9999),datetime.now())
file_name = "write_user_log.txt"
with open(file_name,"a",encoding="utf-8") as f:
f.writelines(rest) def read_and_write():
"""
先读再写入
:return:
"""
file_name = "read_and_write.txt"
with open(file_name,"r+",encoding="utf-8") as f:
read_rest = f.read()
#如果里面没用1,写入一行数据aaa
#如果有,写入bbb
if "1" in read_rest:
f.write("bbb")
else:
f.write("aaa") if __name__ == "__main__":
read_and_write()
文件的备份:
import os
class FileBackup(object):
"""
文本的备份
"""
def __init__(self,src,dist):
"""
构造方法
:param src: 需要备份的文件目录
:param dist: 备份到的目录
"""
self.src = src
self.dist = dist def read_files(self):
""" 读取src的所有文件
:return:
"""
ls = os.listdir(self.src)
print(ls)
for l in ls:
self.back_file(l) def back_file(self,filename):
"""
备份
:param filename: 文件/文件夹的名称
:return:
"""
#判断dist是否存在,不存在就创建这个目录
if not os.path.exists(self.dist):
os.makedirs(self.dist)
print("文件夹不存在,已经创建")
#拼接文件的完整路径
full_src_path = os.path.join(self.src,filename)
full_dist_path = os.path.join(self.dist, filename)
#判断文件是否为我们备份的文件
if os.path.isfile(full_src_path) and os.path.splitext(full_src_path)[-1].lower() == ".txt":
print(full_src_path)
#读取文件内容
with open(full_dist_path,"w",encoding="utf-8") as f_dist:
print(">>开始备份 {}".format(filename))
with open(full_src_path,"r",encoding="utf-8") as f_src:
while True:
rest = f_src.read(100)
if not rest:
break
f_dist.write(rest)
f_dist.flush()
#把读取的内容写入新的文件
else:
print("不存在") if __name__ == "__main__":
"""
这样子写通用性不高
src_path = 'D:\\PycharmProjects\\p1\\src'
dist_path = 'D:\\PycharmProjects\\p1\\dist'
"""
base_path = os.path.dirname(os.path.abspath(__file__))
src_path = os.path.join(base_path,"src")
dist_path = os.path.join(base_path,"dist")
print(base_path)
bak = FileBackup(src_path,dist_path)
bak.read_files()
python11文件读写模块的更多相关文章
- node.js之文件读写模块,配合递归函数遍历文件夹和其中的文件
fs.stat会返回文件夹会文件的属性 var fs = require('fs'); var wenwa = function (pathname,callback) { fs.stat(pathn ...
- 7. Buffer_包描述文件_npm常用指令_fs文件读写_模块化require的规则
1. Buffer 一个和数组类似的对象,不同是 Buffer 是专门用来保存二进制数据的. 特点: 大小固定: 在创建时就确定了,且无法调整 性能较好: 直接对计算机的内存进行操作 每个元素大小为1 ...
- python自动化--语言基础四模块、文件读写、异常
模块1.什么是模块?可以理解为一个py文件其实就是一个模块.比如xiami.py就是一个模块,想引入使用就在代码里写import xiami即可2.模块首先从当前目录查询,如果没有再按path顺序逐一 ...
- nodejs基础(回调函数、模块、事件、文件读写、目录的创建与删除)
node官网:http://nodejs.cn/ 今天想看看node的视频,对node进一步了解, 1.我们可以从官网下载node到自己的电脑上,今天了解到node的真正概念,node时javascr ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- python基础之文件读写
python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使用os模块的一些方法如下: 得到 ...
- Python之文件读写
本节内容: I/O操作概述 文件读写实现原理与操作步骤 文件打开模式 Python文件操作步骤示例 Python文件读取相关方法 文件读写与字符编码 一.I/O操作概述 I/O在计算机中是指Input ...
- 第二篇:python基础之文件读写
python基础之文件读写 python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使 ...
- [js高手之路]node js系列课程-创建简易web服务器与文件读写
web服务器至少有以下几个特点: 1.24小时不停止的工作,也就是说这个进程要常驻在内存中 2.24小时在某一端口监听,如: http://localhost:8080, www服务器默认端口80 3 ...
随机推荐
- 改善深层神经网络-week3编程题(Tensorflow 实现手势识别 )
TensorFlow Tutorial Initialize variables Start your own session Train algorithms Implement a Neural ...
- 康托展开+逆展开(Cantor expension)详解+优化
康托展开 引入 康托展开(Cantor expansion)用于将排列转换为字典序的索引(逆展开则相反) 百度百科 维基百科 方法 假设我们要求排列 5 2 4 1 3 的字典序索引 逐位处理: 第一 ...
- uni-app 安卓离线打包详细教程
借鉴 uni-app官方给出的文章http://ask.dcloud.net.cn/article/508(虽说是04年的) 预备环境 AndroidStudio开发环境,要求安装Android4.0 ...
- Java并发:重入锁 ReentrantLock(二)
一.理解锁的实现原理 1. 用wait()去实现一个lock方法,wait()要和synchronized同步关键字一起去使用的,直接使用wait方法会直接报IllegalMonitorStateEx ...
- python pip whl安装和使用
转载:https://www.cnblogs.com/klb561/p/9271322.html 1 python的安装 首先,从python的官方网站 www.python.org下载需要的pyth ...
- cf14C Four Segments(计算几何)
题意: 给四个线段(两个端点的坐标). 判断这四个线段能否构成一个矩形.(矩形的四条边都平行于X轴或Y轴) 思路: 计算几何 代码: class Point{ public: int x,y; voi ...
- linux 内核源代码情景分析——Intel X86 CPU 系列的寻址方式
当我们说一个CPU是"16位"或"32"位时,指的是处理器中"算数逻辑单元"(ALU)的宽度.数据总线通常与ALU具有相同的宽度.当Inte ...
- 『学了就忘』Linux基础命令 — 18、Linux命令的基本格式
目录 1.命令提示符说明 2.命令的基本格式 (1)举例ls命令 (2)说明ls -l命令的 输出内容 1.命令提示符说明 [root@localhost ~] # []:这是提示符的分隔符号,没有特 ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- Linux mem 2.5 Buddy 内存回收机制
文章目录 1. 简介 2. LRU 组织 2.1 LRU 链表 2.2 LRU Cache 2.3 LRU 移动操作 2.3.1 page 加入 LRU 2.3.2 其他 LRU 移动操作 3. LR ...