linux操作系统优化系列-RAID不同阵列模式的选择
背景
笔者所在的某通信运营商某大数据项目由于应用面临瓶颈需要扩充服务器设备,当初上这个项目的时候,服务器上线前的工作(配置raid,安装操作系统,Infiniband网络调试,系统漏洞安全加固)都是我跟另一位同事负责的,所以这块还是比较熟悉的。现在那位同事已经离职了,因此现在扩充新服务器上线这事也就自然落到我这里来了,由于这次距离上次项目施工的时间间隔差不多快两年了,所以我想借着写博客把那段久远的往事回忆起来。
raid的基本概念
raid的全称是 独立磁盘冗余阵列,英文名叫 Redundant Array of Independent Disks,所以raid就是其英文名的首字母缩写。
由加利福尼亚大学伯克利分校(University of California-Berkeley)在1988年发表的文章:“A Case for Redundant Arrays of Inexpensive Disks”。文章中,谈到了RAID这个词汇,而且定义了RAID的5层级。伯克利大学研究目的是反应当时CPU快速的性能。CPU效能每年大约成长30~50%,而硬磁机只能成长约7%。研究小组希望能找出一种新的技术,在短期内,立即提升效能来平衡计算机的运算能力。在当时,柏克莱研究小组的主要研究目的是效能与成本。
另外,研究小组也设计出容错(fault-tolerance),逻辑数据备份(logical data redundancy),而产生了RAID理论。研究初期,便宜(Inexpensive)的磁盘也是主要的重点,但后来发现,大量便宜磁盘组合并不能适用于现实的生产环境,后来Inexpensive被改为independent,许多独立的磁盘组。
独立磁盘冗余阵列(RAID,redundant array of independent disks)是把相同的数据存储在多个硬盘的不同的地方(因此,冗余地)的方法。通过把数据放在多个硬盘上,输入输出操作能以平衡的方式交叠,改良性能。因为多个硬盘增加了平均故障间隔时间(MTBF),储存冗余数据也增加了容错。
简而言之,raid的基本思想就是把多个相对便宜的磁盘组合起来,成为一个硬盘阵列组,目的就是使性能达到甚至超过一个价格昂贵,容量巨大的磁盘。因此这项技术出现之后,获得了市场的强烈反响,尤其在企业服务器市场,它基本是一个标配,因此搞IT运维raid相关的概念和技术是必不可少的。
raid的数据组织方式
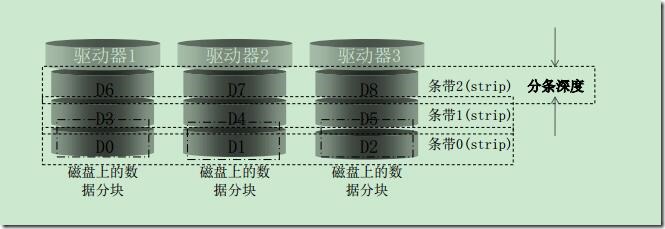
分块:将一个分区分成多个大小相等的、地址相邻的块,这些块称为分块。它是组成条带的元素。
条带(strip): 同一磁盘阵列中的多个磁盘驱动器上相同的“位置”(或者说是相同编号)的分块。
raid校验方式
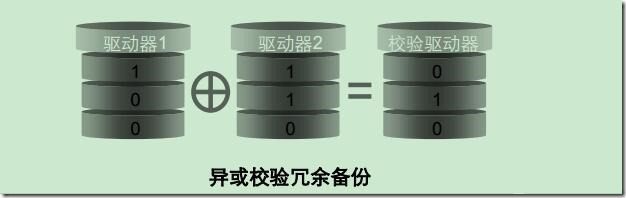
XOR校验的算法----相同为假,相异为假
XOR的逆运算仍为XOR
raid数据保护方式
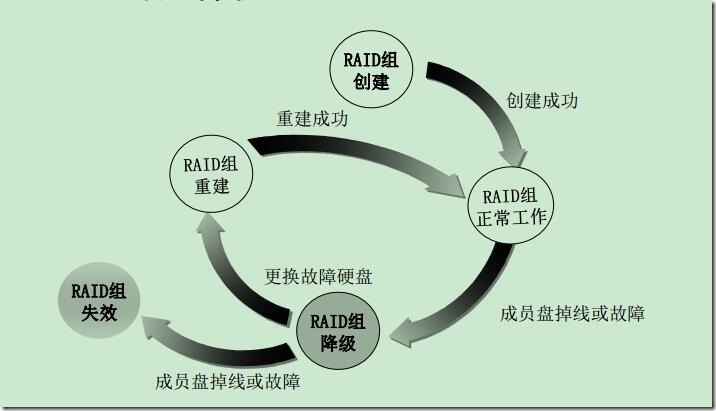
raid数据保护机制之热备和重构
热备(Hot Spare): 当冗余的raid阵列中某个磁盘失效的时候,在不干扰当前raid系统正常使用的情况下,自动顶替失效的磁盘,保证系统在无人工干预的情况下正常工作。
重构: 镜像阵列或者raid阵列中发生故障的磁盘上的所有用户数据和校验数据的重新构建的过程。
配置热备有两种方式,一种是全局热备,一种是局部热备。全局热备是针对raid阵列中的所有raid盘组的,只要raid盘组中有失效的,热备盘就会顶替上去,而局部热备配置的时候是针对指定的盘组的,像这次项目里的做大数据分发集群的raid,我就是两块盘做raid1安装操作系统,剩下22块盘两组raid5+1热备,我这里配置的热备我配置的就是全局热备的,我的想法是如果我只是针对raid5做局部热备的话,那万一raid1系统盘坏了的话,那热备的效能就无法全部发挥出来了,这样做也是加了一层保障,并且我做的还是两块热备盘,那安全性应该更高了。
这就是大数据项目使用的华为服务器,24块1.2T SAS硬盘,

raid的几种状态
raid的等级分类
在讲raid等级之前先简单的回顾下第一次工业革命( 什么鬼,raid跟第一次工业革命能扯上什么关系),大家还记得第一次工业革命开始的主要标志么,蒸汽机哟。那为什么以它作为这次工业革命的主要标志呢,这是因为在资本主义生产中,大机器生产开始取代了工厂手工业,生产力得到了突飞猛进的发展,极大的提高了生产效能和降低了生产成本,这是非常了不得的进步啊。
什么鬼,raid跟第一次工业革命能扯上什么关系),大家还记得第一次工业革命开始的主要标志么,蒸汽机哟。那为什么以它作为这次工业革命的主要标志呢,这是因为在资本主义生产中,大机器生产开始取代了工厂手工业,生产力得到了突飞猛进的发展,极大的提高了生产效能和降低了生产成本,这是非常了不得的进步啊。
回头我们再来看raid,再好好思考下为啥IT先驱们要给它分级呢,其实啊总是绕不开下面这几个因素
raid等级分类结构图
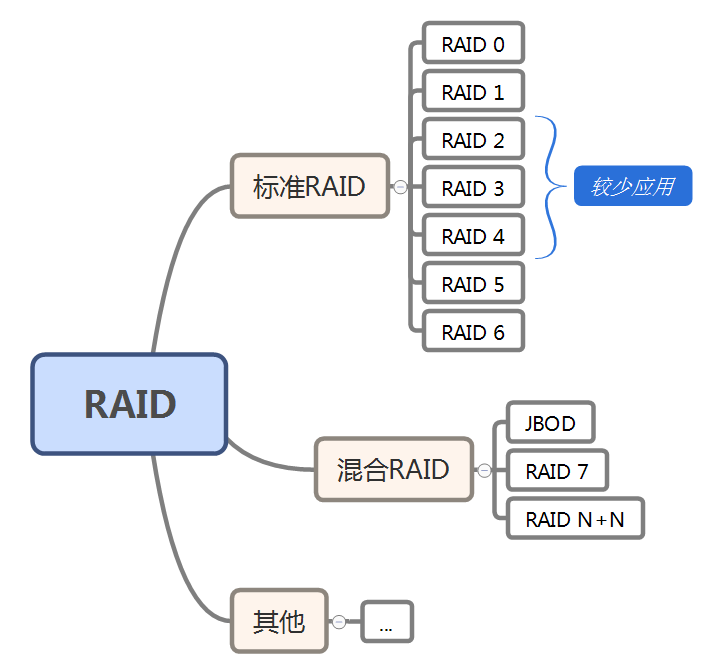
标准raid
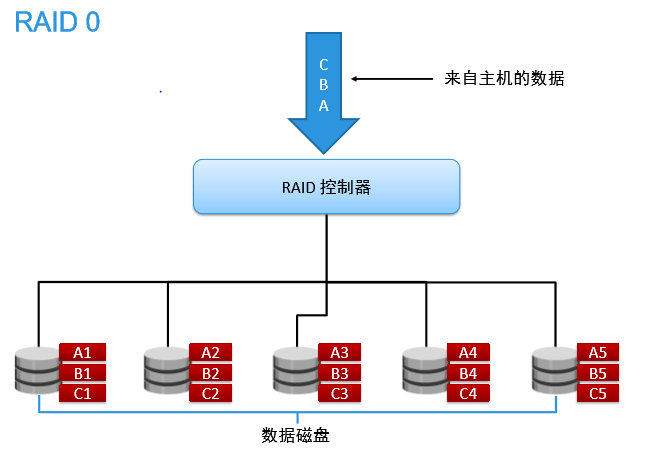
raid0也称为条带(strip)集,它是最早出现的raid模式,它将多个磁盘合并成一个大的磁盘,不具有冗余,并行I/O写入,速度最快。在存放数据时,数据被连续分割成相同大小的数据块,把每段数据分别写到阵列中的不同磁盘上的方法。这样就能使得多个进程同时访问数据的不同部分而不会造成磁盘的冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的 I/O 并行能力,从而获得非常好的性能。
缺点:由于raid0不具有冗余功能,因此如果一块磁盘损坏,则所有的数据都会丢失
适用场景:多数据安全性要求不高的场景
PS:华为服务器在大数据生产应用中,单块数据盘是需要做成raid0才行,就这个问题还咨询过华为工程师,华为工程师的答复是LSI 2208 的RAID卡,需要配置RAID0才能让OS识别到,而且盘一旦坏了进行换新盘操作后是需要重启系统配置新盘raid0,我了个去,这真是一个大坑啊,话说今年夏天的时候不知道重启过多少次系统,停过多少次datanode节点应用。
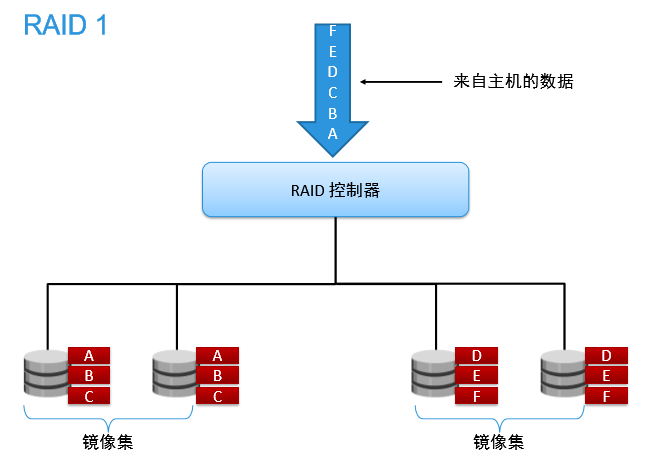
镜像存储(mirroring),没有数据校验。数据被同等地写入两个或多个磁盘中,可想而知,写入速度会比较 慢,但读取速度会比较快。读取速度可以接近所有磁盘吞吐量的总和,写入速度受限于最慢 的磁盘。 RAID1也是磁盘利用率最低的一个。如果用两个不同大小的磁盘建立RAID1,可以用空间较小 的那一个,较大的磁盘多出来的部分可以作他用,不会浪费。
缺点:写入速度慢,磁盘利用率最低
适用生产场景: 对于我而言他唯一的生产场景就是拿来做系统盘安装操作系统。
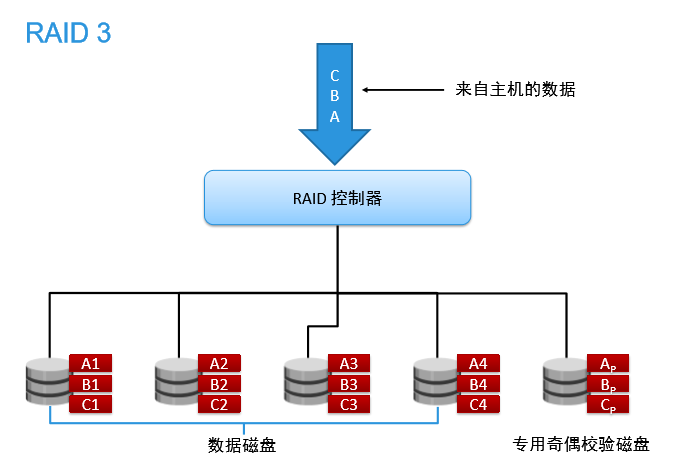
RAID 3是把数据分成多个“块”,数据条带化(stripe)存储于不同的硬盘,数据以字节为单位,使用单块磁盘存储简单的 奇偶校验信息,所以最终磁盘数量为 N+1,实际数据占用的有效空间为N个硬盘的空间总和,而第N+1个硬盘上存储的数据是校验容错信息,当这N+1个硬盘中的其中一个硬盘出现故障时,从其它N个硬盘中的数据也可以恢复原始数据。
缺点:RAID 3会把数据的写入操作分散到多个磁盘上进行,不管是向哪一个数据盘写入数据, 都需要同时重写校验盘中的相关信息。因此,对于那些经常需要执行大量写入操作的应用来 说,校验盘的负载将会很大,无法满足程序的运行速度,从而导致整个RAID系统性能的下降。
适用场景:写入操作较少,读取操作较多的应用环境,比如web服务器。
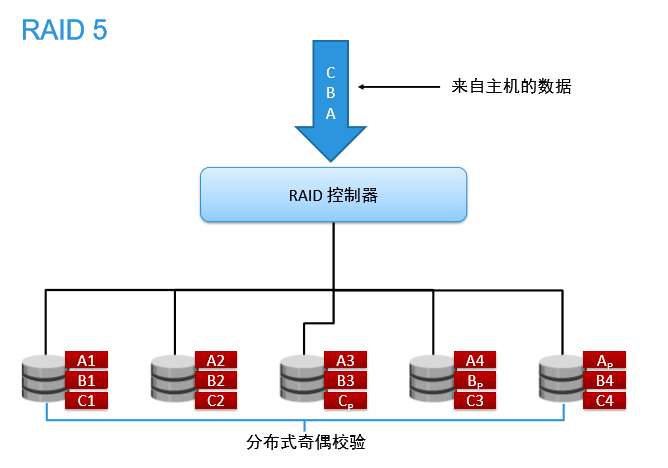
数据以块分段条带化存储。校验信息交叉地存储在所有的数据盘上。
RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和 相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是 说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏 后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动 利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
优点:可以为系统提供安全保障,但它的保障安全性要低于raid1低,磁盘空间利用率比之raid1要高,它具有和raid0相近的读取速度。
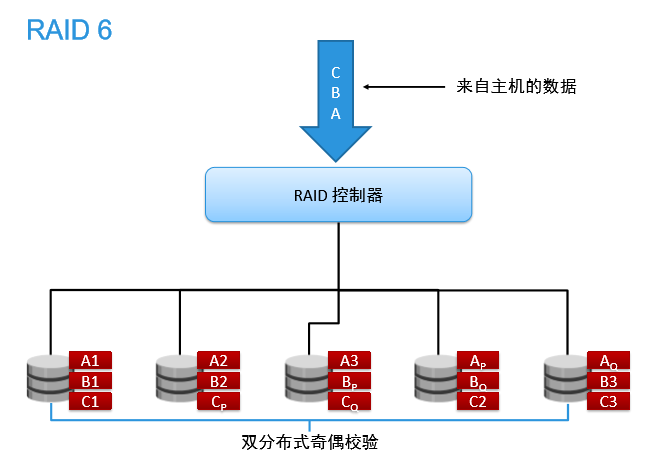
与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实施方式使得RAID 6很少得到实际应用。
优点:两次校验,数据可靠性非常高
缺点:两次校验存在更大的“写损失”,写性能非常差。
这个在大数据平台上也配置过,是拿来做大数据FTP分发集群的,实际应用中效果不是很好,高并发TB级别数据分发经常出现数据文件无法落地。
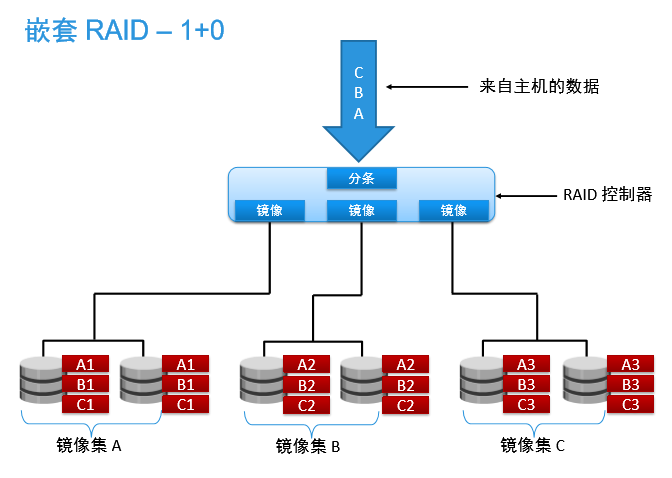
顾名思义,raid10 就是 raid1 和 raid0 的组合,在存放数据时,数据被连续分割成相同大小的数据块,把每段数据分别写到阵列中的不同的镜像集中。
它在提供RAID 1一样的数据安全保证的同时,也提供了与RAID 0近似的存储性能。
常用raid级别比较
| RAID级别 | RAID0 | RAID1 | RAID3 | RAID5 | RAID10 |
| 别名 | 条带 | 镜像 | 专用奇偶位条带 | 分布奇偶位条带 | 镜像条带复制 |
| 容错性 | 无 | 有 | 有 | 有 | 有 |
| 冗余类型 | 无 | 复制 | 奇偶校验 | 奇偶校验 | 复制 |
| 热备盘类型 | 无 | 有 | 有 | 有 | 有 |
| 读性能 | 高 | 低 | 高 | 高 | 一般 |
| 随机写性能 | 高 | 低 | 最低 | 低 | 一般 |
| 连续写性能 | 高 | 低 | 低 | 低 | 一般 |
| 最小硬盘数 | 2块 | 2块 | 3块 | 3块 | 4块 |
| 可用容量 | N*单块硬盘容量 | (N/2)*单块硬盘容量 | (N-1)*单块硬盘容量 | (N-1)*单块硬盘容量 | (N/2)*单块硬盘容量 |
raid典型应用场景
| RAID级别 | RAID0 | RAID1 | RAID3 | RAID5/6 | RAID10 |
| 典型应用环境 |
迅速读写, 安全性要求 不高如图形 工作站等 |
随机数据写入,安 全性要求高,如服 务器、 数据库存储 领域 |
连续数据传输, 安全性要求 高,如视 频编辑、 大型数据 库等 |
随机数据传输 ,安全性要求 高,如金 融、数据 库、存储 等 |
数据量大, 安全性要求 高,如银行、 金融等领域 |
raid的级别选择
从可靠性、性能和成本简单比较各raid级别的优劣,供实际项目中选择时参考
| RAID0 | RAID1 | RAID3 | RAID5 | RAID6 | RAID10 | |
| 可靠性 | * | **** | ** | **** | **** | **** |
| 性能 | **** | **** | *** | *** | ** | **** |
| 成本 | **** | ** | *** | *** | ** | ** |
相关引用链接:
http://support.huawei.com/enterprise/zh/doc/KB1000032748/
http://www.cnblogs.com/gomysql/p/3613767.html
https://www.zhihu.com/question/20131784?from=profile_question_card
http://blog.jobbole.com/83808/
linux操作系统优化系列-RAID不同阵列模式的选择的更多相关文章
- Linux操作系统优化
figure:first-child { margin-top: -20px; } #write ol, #write ul { position: relative; } img { max-wid ...
- linux磁盘管理系列-软RAID的实现
1 什么是RAID RAID全称是独立磁盘冗余阵列(Redundant Array of Independent Disks),基本思想是把多个磁盘组合起来,组合一个磁盘阵列组,使得性能大幅提高. R ...
- linux磁盘管理系列二:软RAID的实现
磁盘管理系列 linux磁盘管理系列一:磁盘配额管理 http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_040_quota.html l ...
- linux磁盘管理系列-LVM的使用
LVM是什么 LVM是Linux操作系统的逻辑卷管理器. 现在有两个Linux版本的LVM,分别是 LVM1,LVM2.LVM1是一种已经被认为稳定了几年的成熟产品,LVM2 是最新最好的LVM版本. ...
- linux磁盘管理系列三:LVM的使用
磁盘管理系列 linux磁盘管理系列一:磁盘配额管理 http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_040_quota.html l ...
- 提高Linux操作系统性能
提高Linux操作系统性能 2011-01-05 13:48 佚名 字号:T | T 本文从磁盘,文件及文件系统,内存和编译等方面详细的讲述了如何对Linux系统性能进行调谐.不管是Linux服务器还 ...
- 【Linux】系统 之 RAID
本人从事DBA相关的工作,最近遇到了IO抖动伴随shread running抖动的情况,主机宕机重启后备库及下游解析binlog出现损坏的案例,向一些有经验的同事咨询学习,其中最大的嫌疑是:raid卡 ...
- Linux基础 - 系统优化及常用命令
目录 Linux基础系统优化及常用命令 Linux基础系统优化 网卡配置文件详解 ifup,ifdown命令 ifconfig命令 ifup,ifdown命令 ip命令 用户管理与文件权限篇 创建普通 ...
- Linux基础系统优化及常用命令
# Linux基础系统优化及常用命令 [TOC] ## Linux基础系统优化 Linux的网络功能相当强悍,一时之间我们无法了解所有的网络命令,在配置服务器基础环境时,先了解下网络参数设定命令. - ...
随机推荐
- 【设计模式】- 生成器模式(Builder)
生成器模式 建造者模式.Builder 生成器模式 也叫建造者模式,可以理解成可以分步骤创建一个复杂的对象.在该模式中允许你使用相同的创建代码生成不同类型和形式的对象. 生成器的结构模式 生成器(Bu ...
- BUAA_OS lab4 难点梳理
BUAA_OS lab4 难点梳理 lab4体会到了OS难度的飞升.实验需要掌握的重点有以下: 系统调用流程 进程通信机制 fork 本lab理解难度较高,接下来将以以上三部分分别梳理. 系统调用 概 ...
- 面试官:Java中线程是按什么顺序执行的?
摘要:Java中多线程并发的执行顺序历来是面试中的重点,掌握Java中线程的执行顺序不仅能够在面试中让你脱颖而出,更能够让你在平时的工作中,迅速定位由于多线程并发问题导致的"诡异" ...
- Linux 网络工具中的瑞士军刀 - socat & netcat
独立博客阅读:https://ryan4yin.space/posts/socat-netcat/ 文中的命令均在 macOS Big Sur 和 Opensuse Tumbleweed 上测试通过 ...
- Day15_87_通过反射机制获取某个特定的方法
通过反射机制获取某个特定的方法 反射是通过 方法名+形参列表来区分各个方法的(形参列表要用class类型.加.class) 示例代码 import java.lang.reflect.Method; ...
- 适用于分布式ID的雪花算法
基于Java实现的适用于分布式ID的雪花算法工具类,这里存一下日后好找 /** * 雪花算法生成ID */ public class SnowFlakeUtil { private final sta ...
- 命令行运行py文件报错
起因 今天用ubuntu 终端运行py文件报了个错,找不到模块? 我切换回pycharm中运行,运行一切正常 解决 在报错模块中,插入绝对路径 import sys sys.path.append(' ...
- windows黑窗口命令笔记
windows有个黑窗口,吃惊吧!意外吧!! 哈哈,我是真的有些吃惊的!! nslookup ipconfig /all ipconfig /flushdns windows 声音修复 windows ...
- 初中级php程序员面试时常见问题整理
初中级php程序员面试问题收集 感悟 有时候草率给出一个答案,比思而无果更糟糕 php基础 php的数据类型 php数据类型的转换 php魔术方法 php 的trait的概念及特点 php 虚拟类和接 ...
- hdu4536 水搜索
题意: XCOM Enemy Unknown Time Limit: 500/200 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others ...