关于c++、go、nodejs、python的计算性能测试,结果令人惊讶
计算性能在计算密集型的服务上,是非常重要的, 一直以为,在计算性能上,肯定是C++ > go > nodejs >= python
但测试结果却让人大跌眼镜!!!
实际的结果是:
go > nodejs > c++ > python
各语言同样逻辑下的运行结果,如下:
其中, ./t是go编译的程序, ./a.out是c++编译的程序, nodejs和python直接跑脚本
不用关注target size的内容,这个是验证结果一致的,保证算法是一致
主要看use time, 单位是秒:
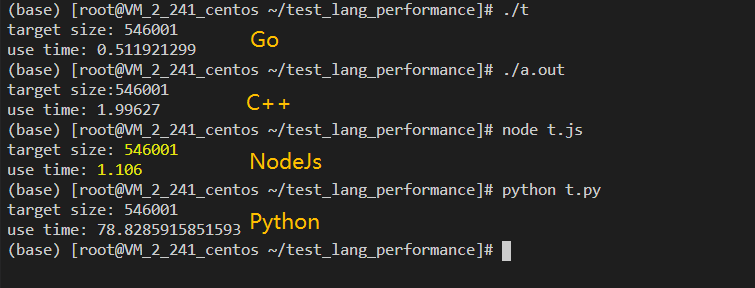
这个结果很奇妙,反映出在计算密集的场景下,C++并非想象中那么快,而nodejs表现却非常亮眼
难道是我的代码问题?各位看官看看有没办办法优化性能的?
相关的编译器、执行器版本如下:
go: 1.15.2
g++: 4.8.2
nodejs: 14.18.0
python:3.7.3
各语言的测试代码如下, 计算逻辑是完全一致的:
Go:
package main; import "fmt"
import "time" type Data struct {
x float64
y float64
a int
} func MakeData(num int) []Data {
var vec = make([]Data, 0, num)
for i:=0; i< num; i++ {
var data Data
data.x = float64(i) + 0.5;
data.y = float64(i) + 1.5;
data.a = i;
vec = append(vec, data)
}
return vec
} func Cal(data []Data, idx int, num int) float64 {
var sum1 float64 = 0.0;
var sum2 float64 = 0.0;
for i:= idx-num+1; i <= idx; i++ {
if i <0 {
continue;
}
var elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
} var avg1 = sum1/float64(num);
var avg2 = sum2/float64(num); return (avg1 + avg2)/2;
} func Make(data []Data) {
var target = make([]float64, 0, len(data));
for i := 0; i < len(data); i++ {
var v = Cal(data, i, 1000);
if v > 1000 {
target = append(target, v)
}
}
fmt.Println("target size:" , len(target))
} func main() {
var t1 = time.Now().UnixNano()
var data = MakeData(300*365*5);
Make(data);
var t2 = time.Now().UnixNano()
fmt.Println("use time:", float64(t2-t1)/1000000000)
}
C++:
#include <stdio.h>
#include <iostream>
#include <vector>
#include <utility>
#include <string>
#include <unistd.h>
#include <sys/time.h> struct Data {
double x;
double y;
int a;
}; std::vector<Data> MakeData(int num) {
std::vector<Data> vec;
vec.reserve(num);
for (int i=0; i< num; i++) {
Data data;
data.x = static_cast<double>(i) + 0.5;
data.y = static_cast<double>(i) + 1.5;
data.a = i;
vec.push_back(std::move(data));
}
return std::move(vec);
} double Cal(std::vector<Data> & data, int idx, int num) {
double sum1 = 0.0;
double sum2 = 0.0;
for (int i = idx-num+1; i <= idx; i++) {
if (i <0) {
continue;
}
auto & elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
} auto avg1 =sum1/num;
auto avg2 =sum2/num; return (avg1 + avg2)/2;
} void Make(std::vector<Data> & data) {
std::vector<double> target;
target.reserve(data.size());
for (int i = 0; i < data.size(); i++) {
auto v = Cal(data, i, 1000);
if (v > 1000) {
target.push_back(v);
}
}
std::cout << "target size:" << target.size() << std::endl;
} int main(int argc,char** argv)
{
struct timeval t1;
struct timeval t2;
gettimeofday(&t1, NULL);
auto data = MakeData(300*365*5);
Make(data);
gettimeofday(&t2, NULL);
auto usetime = double((t2.tv_sec*1000000 + t2.tv_usec) - (t1.tv_sec*1000000 + t1.tv_usec))/1000000;
std::cout <<"use time: " << usetime << std::endl;
}
NodeJs:
class Data {
constructor() {
this.x = 0.0;
this.y = 0.0;
this.a = 0;
}
};
function MakeData(num) {
let vec = [];
for (let i=0; i< num; i++) {
let data = new Data();
data.x = i + 0.5;
data.y = i + 1.5;
data.a = i;
vec.push(data);
}
return vec;
}
function Cal(data, idx, num) {
let sum1 = 0.0;
let sum2 = 0.0;
for (let i = idx-num+1; i <= idx; i++) {
if (i <0) {
continue;
}
let elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
}
let avg1 =sum1/num;
let avg2 =sum2/num;
return (avg1 + avg2)/2;
}
function Make(data) {
let target = [];
for (let i = 0; i < data.length; i++) {
let v = Cal(data, i, 1000);
if (v > 1000) {
target.push(v);
}
}
console.log("target size:", target.length);
}
t1 = new Date().getTime();
let data = MakeData(300*365*5);
Make(data);
t2= new Date().getTime();
console.log("use time:", (t2-t1)/1000)
Python:
import time class Data:
def __init__(self):
self.x = 0.0
self.y = 0.0
self.a = 0 def MakeData(num):
vec = []
for i in range(0, num):
data = Data()
data.x = i + 0.5
data.y = i + 1.5
data.a = i
vec.append(data)
return vec def Cal(data, idx, num):
sum1 = 0.0
sum2 = 0.0
i = idx-num+1
while i<=idx:
if i <0:
i+=1
continue
elem = data[i]
sum1 += elem.x
sum2 += elem.y
i+=1 avg1 =sum1/num
avg2 =sum2/num return (avg1 + avg2)/2 def Make(data):
target = []
data_len = len(data)
for i in range(0, data_len):
v = Cal(data, i, 1000)
if v > 1000:
target.append(v)
print("target size:" , len(target)) t1=time.time()
data = MakeData(300*365*5)
Make(data)
print("use time:", time.time() - t1)
关于c++、go、nodejs、python的计算性能测试,结果令人惊讶的更多相关文章
- [转载] NodeJS无所不能:细数十个令人惊讶的NodeJS开源项目
转载自http://www.searchsoa.com.cn/showcontent_79099.htm 在几年的时间里,Node.JS逐渐发展成一个成熟的开发平台,吸引了许多开发者.有许多大型高流量 ...
- windows下安装python科学计算环境,numpy scipy scikit ,matplotlib等
安装matplotlib: pip install matplotlib 背景: 目的:要用Python下的DBSCAN聚类算法. scikit-learn 是一个基于SciPy和Numpy的开源机器 ...
- Python TF-IDF计算100份文档关键词权重
上一篇博文中,我们使用结巴分词对文档进行分词处理,但分词所得结果并不是每个词语都是有意义的(即该词对文档的内容贡献少),那么如何来判断词语对文档的重要度呢,这里介绍一种方法:TF-IDF. 一,TF- ...
- Python科学计算(二)windows下开发环境搭建(当用pip安装出现Unable to find vcvarsall.bat)
用于科学计算Python语言真的是amazing! 方法一:直接安装集成好的软件 刚开始使用numpy.scipy这些模块的时候,图个方便直接使用了一个叫做Enthought的软件.Enthought ...
- 目前比较流行的Python科学计算发行版
经常有身边的学友问到用什么Python发行版比较好? 其实目前比较流行的Python科学计算发行版,主要有这么几个: Python(x,y) GUI基于PyQt,曾经是功能最全也是最强大的,而且是Wi ...
- Python科学计算之Pandas
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1474979163&ver=1&signature=wnZn1UtW ...
- Python 科学计算-介绍
Python 科学计算 作者 J.R. Johansson (robert@riken.jp) http://dml.riken.jp/~rob/ 最新版本的 IPython notebook 课程文 ...
- Python科学计算库
Python科学计算库 一.numpy库和matplotlib库的学习 (1)numpy库介绍:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成 ...
- Python科学计算基础包-Numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对数 ...
随机推荐
- 使用微软RPA工具 Power Automate自动完成重复性工作
介绍 最近发现了win11自带了一个有趣的功能,可以自动去执行一些流程的工作.恰好目前每天早上都需要去提醒同事填写日计划,刚好可以试用下. 这是官网上对此功能的介绍 可以看到,对于win11我们是可以 ...
- 统计学习2:线性可分支持向量机(Scipy实现)
1. 模型 1.1 超平面 我们称下面形式的集合为超平面 \[\begin{aligned} \{ \bm{x} | \bm{a}^{T} \bm{x} - b = 0 \} \end{aligned ...
- 「日志」Navicat统计的行数竟然和表实际行数不一致
背景 近期为了保障线上数据库的稳定性,我决定针对一些大表的历史数据有计划地进行备份迁移,但是呢,发现一个奇特的现象,Navicat统计行数和表自身count统计数竟然不一致!?0.0 Navicat ...
- echarts中饼状图数据太多进行翻页
echarts饼状图数据太多 echarts 饼状图内容太多怎么处理 有些时候,我们饼状图中echarts的数据可能会很多. 这个时候展示肯定会密密麻麻的.导致显示很凌乱 我们需要'翻页'类似表格展示 ...
- 一个简单的BypassUAC编写
什么是UAC? UAC是微软为提高系统安全而在Windows Vista中引入的新技术,它要求用户在执行可能会影响计算机运行的操作或执行更改影响其他用户的设置的操作之前,提供权限或管理员密码.通过在 ...
- 学习java 7.3
学习内容:定义类不需要加static 成员方法在多个对象时是可以共用的,而成员变量不可以共用,多个对象指向一个内存时,改变变量的值,对象所在的类中的变量都会改变 成员变量前加private,成员方法前 ...
- day04:Python学习笔记
day04:Python学习笔记 1.算数运算符 1.算数运算符 print(10 / 3) #结果带小数 print(10 // 3) #结果取整数,不是四舍五入 print(10 % 3) #结果 ...
- ceph安装部署
环境准备 测试环境是4台虚拟机,所有机器都是刚刚安装好系统(minimal),只配置完网卡和主机名的centos7.7,每个osd增加一块磁盘,/dev/sdb ceph-admin ---- adm ...
- Hadoop RPC通信
Remote Procedure Call(简称RPC):远程过程调用协议 1. 通过网络从远程计算机程序上请求服务 2. 不需要了解底层网络技术的协议(假定某些传输协议的存在,如TCP或UDP) 3 ...
- d3入门二-常用 方法
CSV 版本6.5.0 这里的data实际上是csv中的一行数据 d3.csv("static/data/dept_cpu.csv",function (data) { conso ...