关于c++、go、nodejs、python的计算性能测试,结果令人惊讶
计算性能在计算密集型的服务上,是非常重要的, 一直以为,在计算性能上,肯定是C++ > go > nodejs >= python
但测试结果却让人大跌眼镜!!!
实际的结果是:
go > nodejs > c++ > python
各语言同样逻辑下的运行结果,如下:
其中, ./t是go编译的程序, ./a.out是c++编译的程序, nodejs和python直接跑脚本
不用关注target size的内容,这个是验证结果一致的,保证算法是一致
主要看use time, 单位是秒:
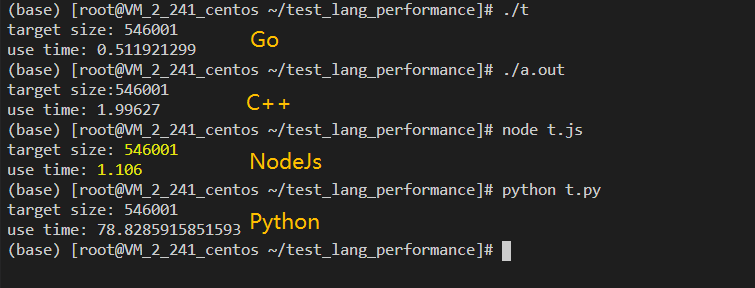
这个结果很奇妙,反映出在计算密集的场景下,C++并非想象中那么快,而nodejs表现却非常亮眼
难道是我的代码问题?各位看官看看有没办办法优化性能的?
相关的编译器、执行器版本如下:
go: 1.15.2
g++: 4.8.2
nodejs: 14.18.0
python:3.7.3
各语言的测试代码如下, 计算逻辑是完全一致的:
Go:
package main; import "fmt"
import "time" type Data struct {
x float64
y float64
a int
} func MakeData(num int) []Data {
var vec = make([]Data, 0, num)
for i:=0; i< num; i++ {
var data Data
data.x = float64(i) + 0.5;
data.y = float64(i) + 1.5;
data.a = i;
vec = append(vec, data)
}
return vec
} func Cal(data []Data, idx int, num int) float64 {
var sum1 float64 = 0.0;
var sum2 float64 = 0.0;
for i:= idx-num+1; i <= idx; i++ {
if i <0 {
continue;
}
var elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
} var avg1 = sum1/float64(num);
var avg2 = sum2/float64(num); return (avg1 + avg2)/2;
} func Make(data []Data) {
var target = make([]float64, 0, len(data));
for i := 0; i < len(data); i++ {
var v = Cal(data, i, 1000);
if v > 1000 {
target = append(target, v)
}
}
fmt.Println("target size:" , len(target))
} func main() {
var t1 = time.Now().UnixNano()
var data = MakeData(300*365*5);
Make(data);
var t2 = time.Now().UnixNano()
fmt.Println("use time:", float64(t2-t1)/1000000000)
}
C++:
#include <stdio.h>
#include <iostream>
#include <vector>
#include <utility>
#include <string>
#include <unistd.h>
#include <sys/time.h> struct Data {
double x;
double y;
int a;
}; std::vector<Data> MakeData(int num) {
std::vector<Data> vec;
vec.reserve(num);
for (int i=0; i< num; i++) {
Data data;
data.x = static_cast<double>(i) + 0.5;
data.y = static_cast<double>(i) + 1.5;
data.a = i;
vec.push_back(std::move(data));
}
return std::move(vec);
} double Cal(std::vector<Data> & data, int idx, int num) {
double sum1 = 0.0;
double sum2 = 0.0;
for (int i = idx-num+1; i <= idx; i++) {
if (i <0) {
continue;
}
auto & elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
} auto avg1 =sum1/num;
auto avg2 =sum2/num; return (avg1 + avg2)/2;
} void Make(std::vector<Data> & data) {
std::vector<double> target;
target.reserve(data.size());
for (int i = 0; i < data.size(); i++) {
auto v = Cal(data, i, 1000);
if (v > 1000) {
target.push_back(v);
}
}
std::cout << "target size:" << target.size() << std::endl;
} int main(int argc,char** argv)
{
struct timeval t1;
struct timeval t2;
gettimeofday(&t1, NULL);
auto data = MakeData(300*365*5);
Make(data);
gettimeofday(&t2, NULL);
auto usetime = double((t2.tv_sec*1000000 + t2.tv_usec) - (t1.tv_sec*1000000 + t1.tv_usec))/1000000;
std::cout <<"use time: " << usetime << std::endl;
}
NodeJs:
class Data {
constructor() {
this.x = 0.0;
this.y = 0.0;
this.a = 0;
}
};
function MakeData(num) {
let vec = [];
for (let i=0; i< num; i++) {
let data = new Data();
data.x = i + 0.5;
data.y = i + 1.5;
data.a = i;
vec.push(data);
}
return vec;
}
function Cal(data, idx, num) {
let sum1 = 0.0;
let sum2 = 0.0;
for (let i = idx-num+1; i <= idx; i++) {
if (i <0) {
continue;
}
let elem = data[i];
sum1 += elem.x;
sum2 += elem.y;
}
let avg1 =sum1/num;
let avg2 =sum2/num;
return (avg1 + avg2)/2;
}
function Make(data) {
let target = [];
for (let i = 0; i < data.length; i++) {
let v = Cal(data, i, 1000);
if (v > 1000) {
target.push(v);
}
}
console.log("target size:", target.length);
}
t1 = new Date().getTime();
let data = MakeData(300*365*5);
Make(data);
t2= new Date().getTime();
console.log("use time:", (t2-t1)/1000)
Python:
import time class Data:
def __init__(self):
self.x = 0.0
self.y = 0.0
self.a = 0 def MakeData(num):
vec = []
for i in range(0, num):
data = Data()
data.x = i + 0.5
data.y = i + 1.5
data.a = i
vec.append(data)
return vec def Cal(data, idx, num):
sum1 = 0.0
sum2 = 0.0
i = idx-num+1
while i<=idx:
if i <0:
i+=1
continue
elem = data[i]
sum1 += elem.x
sum2 += elem.y
i+=1 avg1 =sum1/num
avg2 =sum2/num return (avg1 + avg2)/2 def Make(data):
target = []
data_len = len(data)
for i in range(0, data_len):
v = Cal(data, i, 1000)
if v > 1000:
target.append(v)
print("target size:" , len(target)) t1=time.time()
data = MakeData(300*365*5)
Make(data)
print("use time:", time.time() - t1)
关于c++、go、nodejs、python的计算性能测试,结果令人惊讶的更多相关文章
- [转载] NodeJS无所不能:细数十个令人惊讶的NodeJS开源项目
转载自http://www.searchsoa.com.cn/showcontent_79099.htm 在几年的时间里,Node.JS逐渐发展成一个成熟的开发平台,吸引了许多开发者.有许多大型高流量 ...
- windows下安装python科学计算环境,numpy scipy scikit ,matplotlib等
安装matplotlib: pip install matplotlib 背景: 目的:要用Python下的DBSCAN聚类算法. scikit-learn 是一个基于SciPy和Numpy的开源机器 ...
- Python TF-IDF计算100份文档关键词权重
上一篇博文中,我们使用结巴分词对文档进行分词处理,但分词所得结果并不是每个词语都是有意义的(即该词对文档的内容贡献少),那么如何来判断词语对文档的重要度呢,这里介绍一种方法:TF-IDF. 一,TF- ...
- Python科学计算(二)windows下开发环境搭建(当用pip安装出现Unable to find vcvarsall.bat)
用于科学计算Python语言真的是amazing! 方法一:直接安装集成好的软件 刚开始使用numpy.scipy这些模块的时候,图个方便直接使用了一个叫做Enthought的软件.Enthought ...
- 目前比较流行的Python科学计算发行版
经常有身边的学友问到用什么Python发行版比较好? 其实目前比较流行的Python科学计算发行版,主要有这么几个: Python(x,y) GUI基于PyQt,曾经是功能最全也是最强大的,而且是Wi ...
- Python科学计算之Pandas
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1474979163&ver=1&signature=wnZn1UtW ...
- Python 科学计算-介绍
Python 科学计算 作者 J.R. Johansson (robert@riken.jp) http://dml.riken.jp/~rob/ 最新版本的 IPython notebook 课程文 ...
- Python科学计算库
Python科学计算库 一.numpy库和matplotlib库的学习 (1)numpy库介绍:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成 ...
- Python科学计算基础包-Numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对数 ...
随机推荐
- 洛谷 P6199 - [EER1]河童重工(点分治+虚树)
洛谷题面传送门 神仙题. 首先看到这样两棵树的题目,我们肯定会往动态树分治的方向考虑.考虑每次找出 \(T_2\) 的重心进行点分治.然后考虑跨过分治中心的点对之间的连边情况.由于连边边权与两棵树都有 ...
- Codeforces 193D - Two Segments(线段树)
Codeforces 题目传送门 & 洛谷题目传送门 感觉这个 *2900 并不难啊,为什么我没想出来呢 awa 顺便膜拜 ycx 一眼秒掉此题 %%% 首先碰到这类题有两种思路,一是枚举两个 ...
- 错误笔记: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable) E: Unable to lock the administration di
亲测可用 --jack alexander@alexander-virtual-machine:~$ sudo apt-get install -y httpdE: Could not get loc ...
- mysql 分组统计、排序、取前N条记录解决方案
需要在mysql中解决记录的分组统计.排序,并抽取前10条记录的功能.现已解决,解决方案如下: 1)表结构 CREATE TABLE `policy_keywords_rel` ( `id` int( ...
- (转载) IBM DB2数据库odbc配置步骤详解
[IT168 技术] 首先安装IBM DB2 odbc driver 1):可以单独下载DB2 Run-Time Client,大约(86.6m),安装后则odbc驱动程序安装成功.下载地址:ftp: ...
- 【模板】二分图最大匹配(匈牙利算法)/洛谷P3386
题目链接 https://www.luogu.com.cn/problem/P3386 题目大意 给定一个二分图,其左部点的个数为 \(n\),右部点的个数为 \(m\),边数为 \(e\),求其最大 ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- 从源码看Thread&ThreadLocal&ThreadLocalMap的关系与原理
1.三者的之间的关系 ThreadLocalMap是Thread类的成员变量threadLocals,一个线程拥有一个ThreadLocalMap,一个ThreadLocalMap可以有多个Threa ...
- D3-更改x轴的标签
记录,上代码
- 转 【Android】- Android与html5交互操作
转自:https://blog.csdn.net/baidu_35701759/article/details/70314812 1. Android提供了WebView控件可访问网页 通过webVi ...