mysql使用自定义序列实现row_number功能
看了一些文章,终于知道该怎么在 mysql 里面实现 row_number() 排序
话不多说,show you the code:
第一步:建表:
create table grades(
`name` varchar(10),
`subject` varchar(10),
`score` int(10)
)
第二步:写入数据
insert into grades(name, subject, score)
values('小明', '语文', 85),
('小华', '语文', 89),
('小李', '语文', 91),
('小芳', '语文', 93),
('小明', '数学', 77),
('小华', '数学', 95),
('小李', '数学', 83),
('小芳', '数学', 88),
('小明', '英语', 90),
('小华', '英语', 92),
('小李', '英语', 85),
('小芳', '英语', 88)
数据如下:

第三步:
需求:找出各科目单科第二的同学
首先,先排序:
select name, subject, score
from grades
order by subject, score desc
数据如下:

然后,每个科目按照分组排序
select (@i:=case when @subject_pre=t1.subject then @i+1 else 1 end) as rn,
t1.*,
(@subject_pre:=subject)
from (
select name, subject, score
from grades
order by subject, score desc
) t1,
(select @i:=0, @subject_pre:='') as t2
group by subject, score
order by subject, score desc
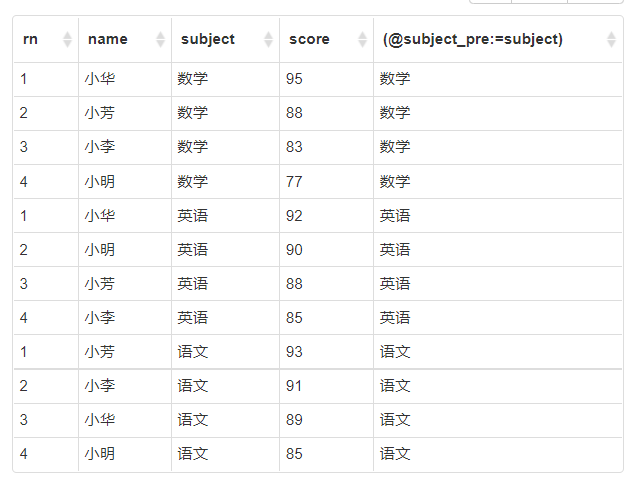
解释一下:
添加一个比较项 subject_pre, 记录前一个科目是什么。
再加上一个自增的序列,实现index+1的功能。
因为数据已经是有序的,如果指向的科目和存储的前一个科目相同,那么序号+1,否则的话,序号从1开始重新计算。
这样就实现了分组排序。
最后,把 rn=2 的数据取出来
select name, subject, score from(
select (@i:=case when @subject_pre=t1.subject then @i+1 else 1 end) as rn,
t1.name,
t1.subject,
t1.score,
(@subject_pre:=subject)
from (
select name, subject, score
from grades
order by subject, score desc
) t1,
(select @i:=0, @subject_pre:='') as t2
group by subject, score
order by subject, score desc
) t
where rn=2
最后结果如下:
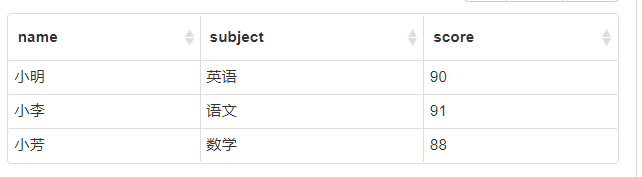
这样就使用mysql实现了row_number()的功能。
在网上找的资料,很多没写清楚,这里特地用一个示例把这个实现讲清楚了,希望对你有帮助!
mysql使用自定义序列实现row_number功能的更多相关文章
- Python进阶:自定义对象实现切片功能
2018-12-31 更新声明:切片系列文章本是分三篇写成,现已合并成一篇.合并后,修正了一些严重的错误(如自定义序列切片的部分),还对行文结构与章节衔接做了大量改动.原系列的单篇就不删除了,毕竟也是 ...
- MySQL下创建序列及创建自定义函数方法介绍
工作过程中需要将基于DB2数据库的应用以及数据迁移到MySQL中去,在原应用中,大量使用了SEQUENCE,考虑尽量减少代码的修改,决定在迁移后的应用中继续保留SEQUENCE的使用,这就要求在MyS ...
- mysql 实现row_number功能
需求: 解答:由于mysql 中没有类似oracle中的 row_number功能,要实现row_number 可以使用如下功能: Select pkid,(@row_number:=@row_num ...
- Mysql - 存储过程/自定义函数
在数据库操作中, 尤其是碰到一些复杂一些的系统, 不可避免的, 会用到函数/自定义函数, 或者存储过程. 实际项目中, 自定义函数和存储过程是越少越好, 因为这个东西多了, 也是一个非常难以维护的地方 ...
- navicat与phpmyadmin做mysql的自定义函数和事件
自定义函数和事件是mysql一个很方便的功能,navicat在5.1以上版本就支持了自定义函数和事件,phpmyadmim不清楚. 用这个是由于一些简单的事情,没有必要去做一个服务器计划使用 接下来我 ...
- python魔法方法-自定义序列
自定义序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列(dict,tuple,list,string等). 如果要实现这个功能,就要遵循 python ...
- MySQL 8.0有什么新功能
https://mysqlserverteam.com/whats-new-in-mysql-8-0-generally-available/ 我们自豪地宣布MySQL 8.0的一般可用性. 现在下载 ...
- python魔法方法-自定义序列详解
自定义序列的相关魔法方法允许我们自己创建的类拥有序列的特性,让其使用起来就像 python 的内置序列(dict,tuple,list,string等). 如果要实现这个功能,就要遵循 python ...
- PythonI/O进阶学习笔记_4.自定义序列类(序列基类继承关系/可切片对象/推导式)
前言: 本文代码基于python3 Content: 1.python中的序列类分类 2. python序列中abc基类继承关系 3. 由list的extend等方法来看序列类的一些特定方法 4. l ...
随机推荐
- [nowcoder5667G]Greater and Greater
令$f[i][j]$表示前i个数的后j位能否匹配b的前j位,有转移$f[i][j]=f[i-1][j-1] \ \&\ [b_{j}\le a_{i}]$ 将$g[i][j]=[b_{j}\ ...
- mabatis的sql标签
定义:mapper.xml映射文件中定义了操作数据库的sql,并且提供了各种标签方法实现动态拼接sql.每个sql是一个statement,映射文件是mybatis的核心. 一,内容标签 1.Name ...
- 学习 DDD 之消化知识!
接触到DDD到现在已经有8个月份了,目前所维护的项目也是基于DDD的思想开发的,从一开始的无从下手,到现在游刃有余,学到不少东西,但是都是一些关键字和零散的知识,同时我也感受到了是因为我对项目越来越熟 ...
- Yet Another Minimization Problem
Yet Another Minimization Problem 一个很显然的决策单调性. 方程是很显然的 $ f_i = \min{f_{j-1} + w(j,i)} $ . 它具有决策单调性,可以 ...
- VS调用别人的COM组件的问题
调用第三方的COM组件,记得要先在管理员cmd执行:regsvr32 xxxx.dll 没执行之前运行 HRESULT hr = pComm.CreateInstance("xxxx.Com ...
- R语言与医学统计图形【5】饼图、条件图
R语言基础绘图系统 基础图形--饼图.克利夫兰点图.条件图 6.饼图 pie(rep(1,26),col=rainbow(26), labels = LETTERS[1:26], #标签 radius ...
- getdelim函数
利用getdelim函数分割读取字段,将文件制表符替换为空格符 1 #include <stdio.h> 2 #include <stdlib.h> 3 4 int main( ...
- mysql 索引的注意事项
mysql 无法使用索引的查询 索引是什么,为什么要用索引,索引使用的时候要注意什么,那些情况下索引无法起作用. 1,索引是什么 mysql的索引也是一张表,并且是一个有序的表,主要记录了需要索引的数 ...
- 巩固java第四天
巩固内容: HTML 元素 HTML 文档由 HTML 元素定义. HTML 元素 开始标签 * 元素内容 结束标签 * <p> 这是一个段落 </p> <a href= ...
- Celery进阶
Celery进阶 在你的应用中使用Celery 我们的项目 proj/__init__.py /celery.py /tasks.py 1 # celery.py 2 from celery ...