scrapy入门到放弃02:整一张架构图,开发一个程序
前言
Scrapy开门篇写了一些纯理论知识,这第二篇就要直奔主题了。先来讲讲Scrapy的架构,并从零开始开发一个Scrapy爬虫程序。
本篇文章主要阐述Scrapy架构,理清开发流程,掌握基本操作。
整体架构
自己动手画架构图一张:
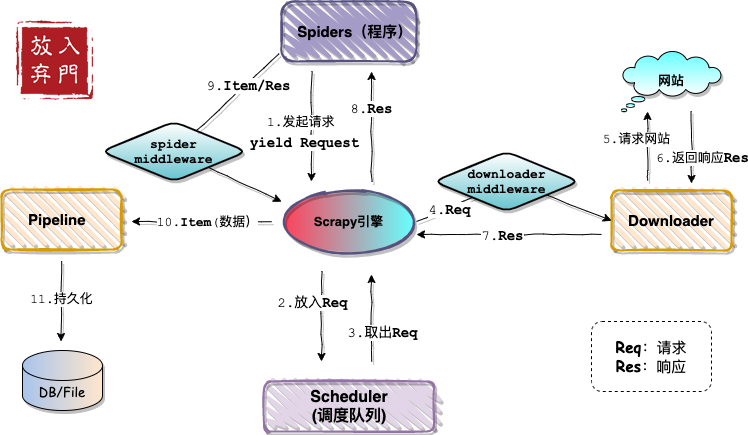
这就是Scrapy的整体架构,看起来流程比较复杂,但其实需要开发者参与的部分不多。这里先介绍一下各个部分。
- Spider:要开发的爬虫程序,用来定义网站入口,实现解析逻辑并发起请求。
- Pipeline:数据管道,可自定义实现数据持久化方式。
- Middleware:中间件,分为两类。一类是下载器中间件,主要处理请求,用于添加请求头、代理等;一类是spider中间件,用于处理响应,用的很少。
- Scheduler:调度器,用来存放爬虫程序的请求。
- Downloader:下载器。对目标网站发起请求,获取响应内容。
一个完整的爬虫,开发者需要参与1、2、3部分的开发。甚至最简单的爬虫,只需要开发Spider部分即可。
准备工作
安装Scrapy
Scrapy的安装和普通模块相同:
pip3 install scrapy
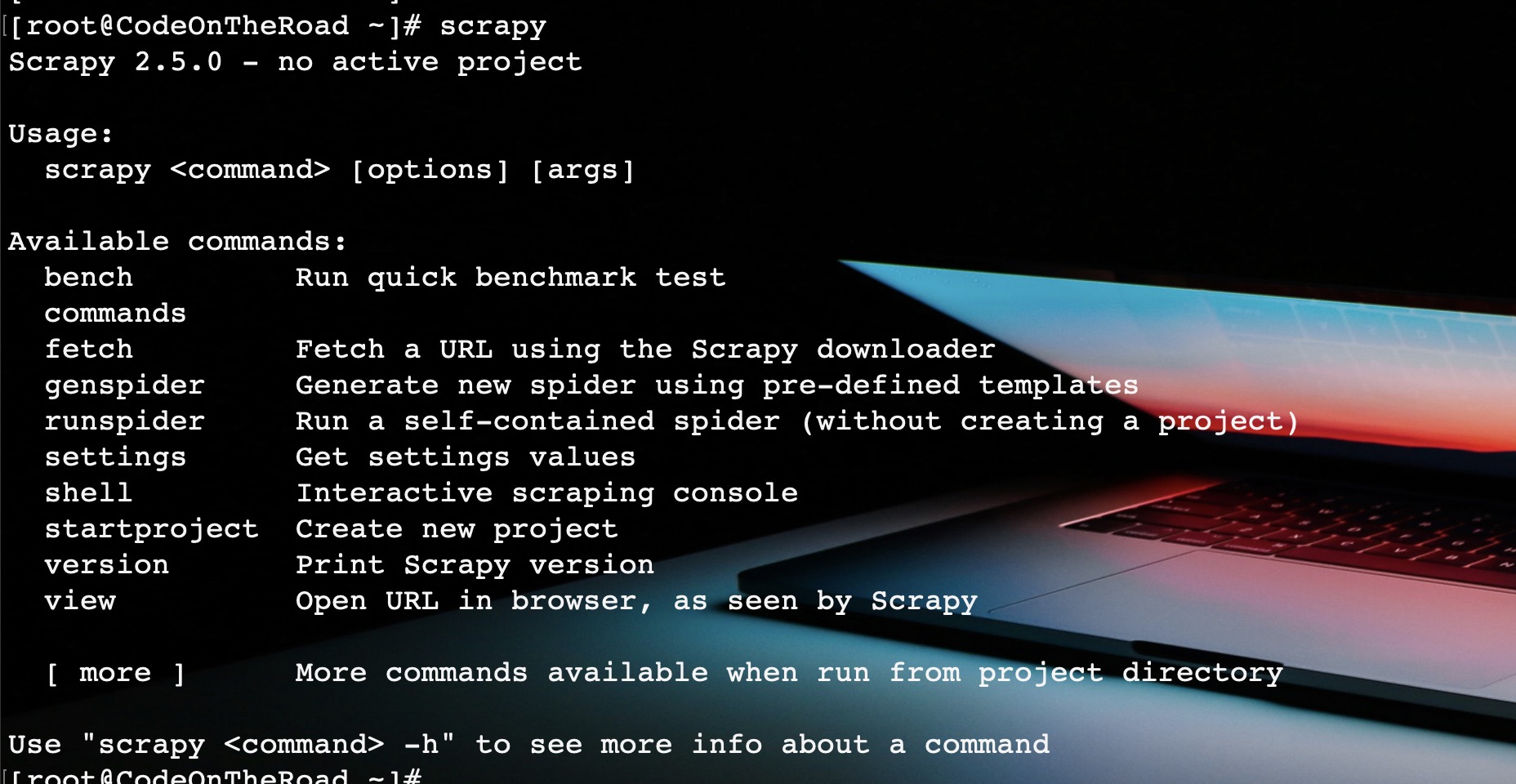
安装之后,就会多出一个scrapy命令,我们可以使用此命令来新建项目、新建爬虫程序、进入shell交互环境等等。
命令说明如下图:
新建项目
和普通python项目不同的是,Scrapy需要使用命令行新建项目,然后再导入IDE进行开发。
scrapy startproject [ProjectName]
执行上面命令,新建一个新的Scrapy项目。
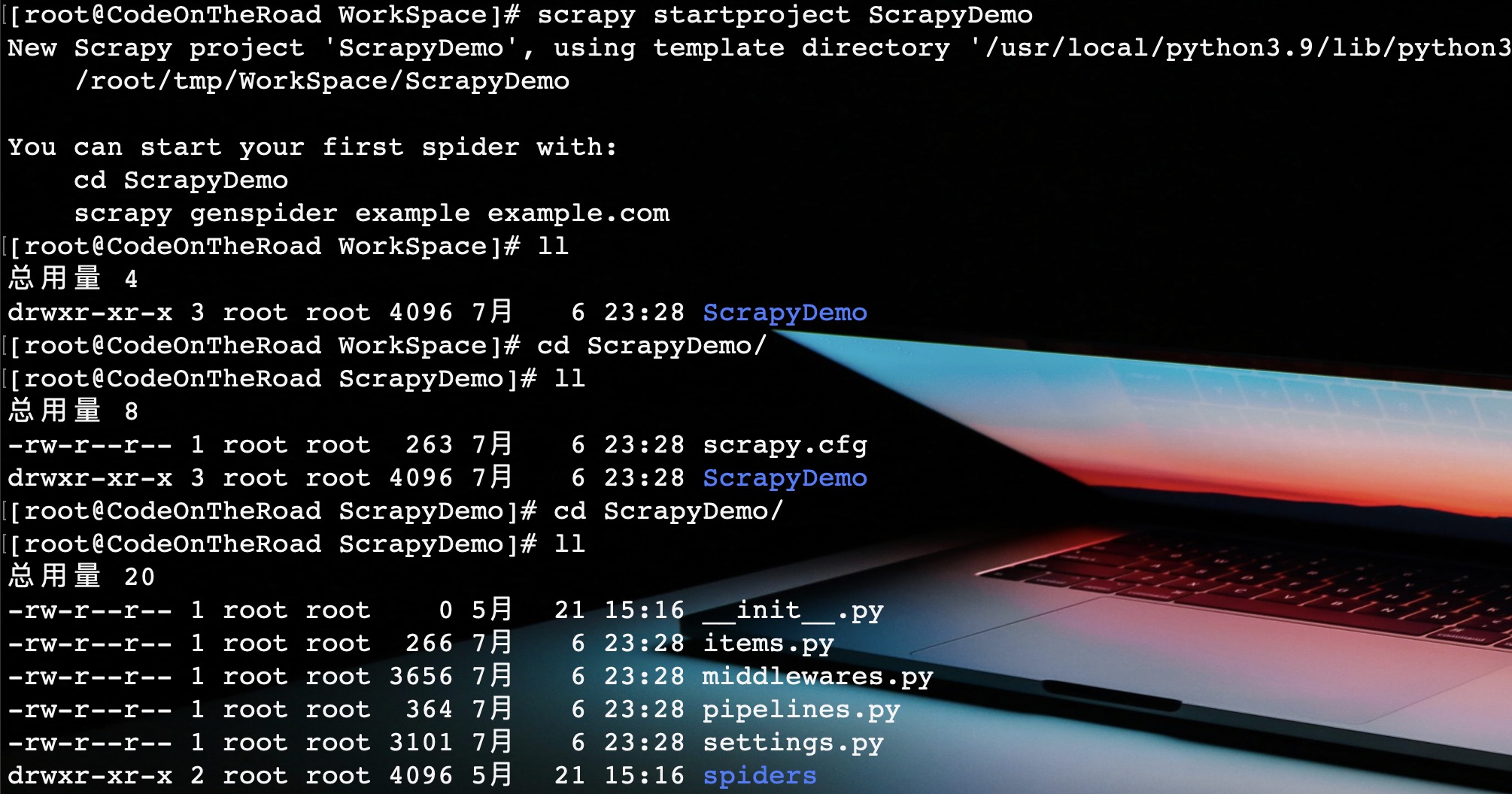
从项目结构可以看出,一个Scrapy项目分为四大模块,与架构中各个部分对应。

新建爬虫程序
将项目导入IDE,spiders包用于存放开发的爬虫程序。而爬虫程序的新建也是通过命令行操作。
# domain就是域名,例如百度域名就是www.baidu.com
scrapy genspider [SpiderName] [domin]
在本scrapy项目任何目录下的命令行中执行此命令,都会在spiders下新建一个爬虫程序。
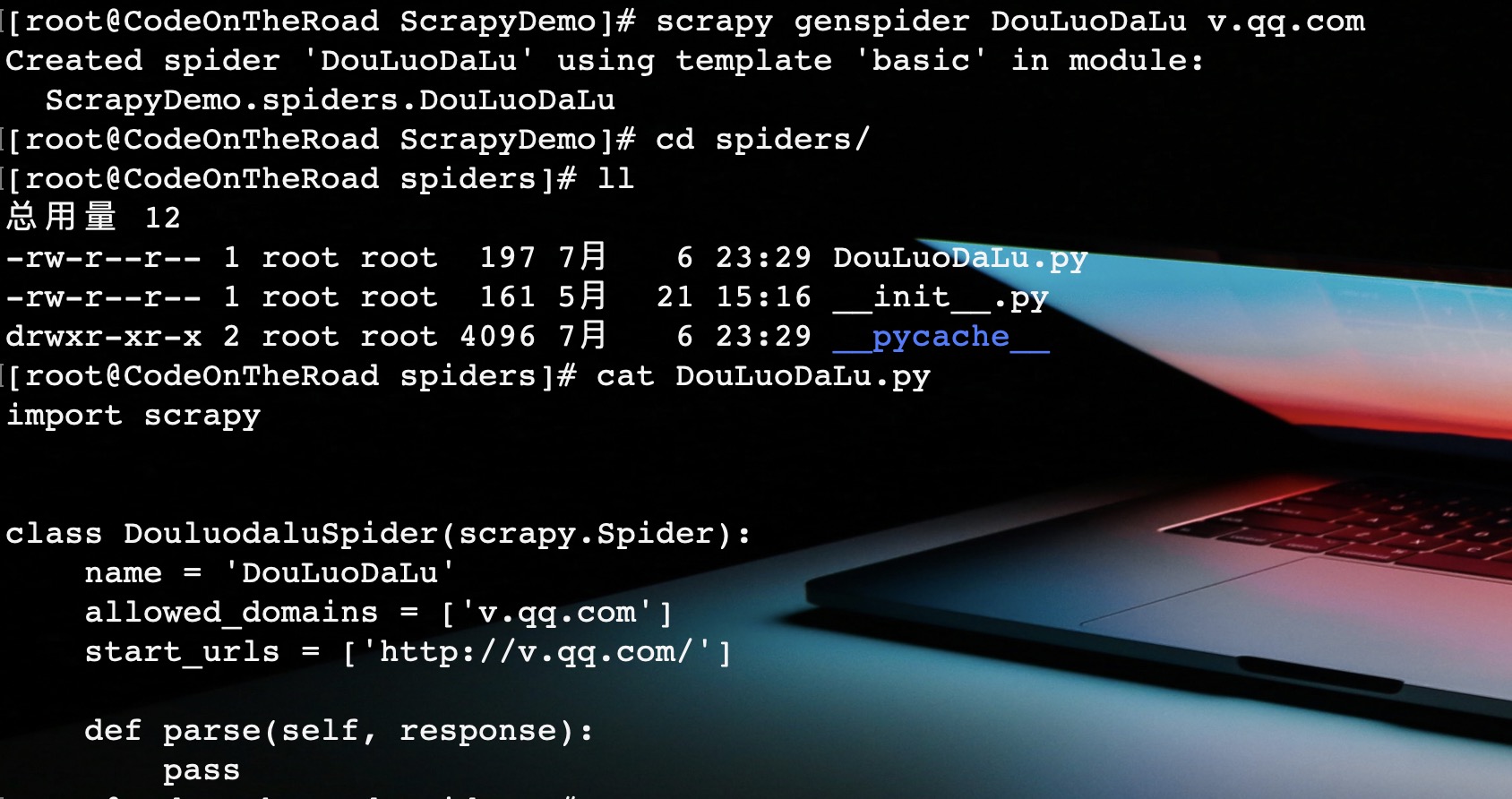
爬虫程序开发
如图,scrapy爬虫程序已经生成,在其中实现解析规则代码即可完成开发。
这里依然以斗罗大陆为例,程序代码如下。
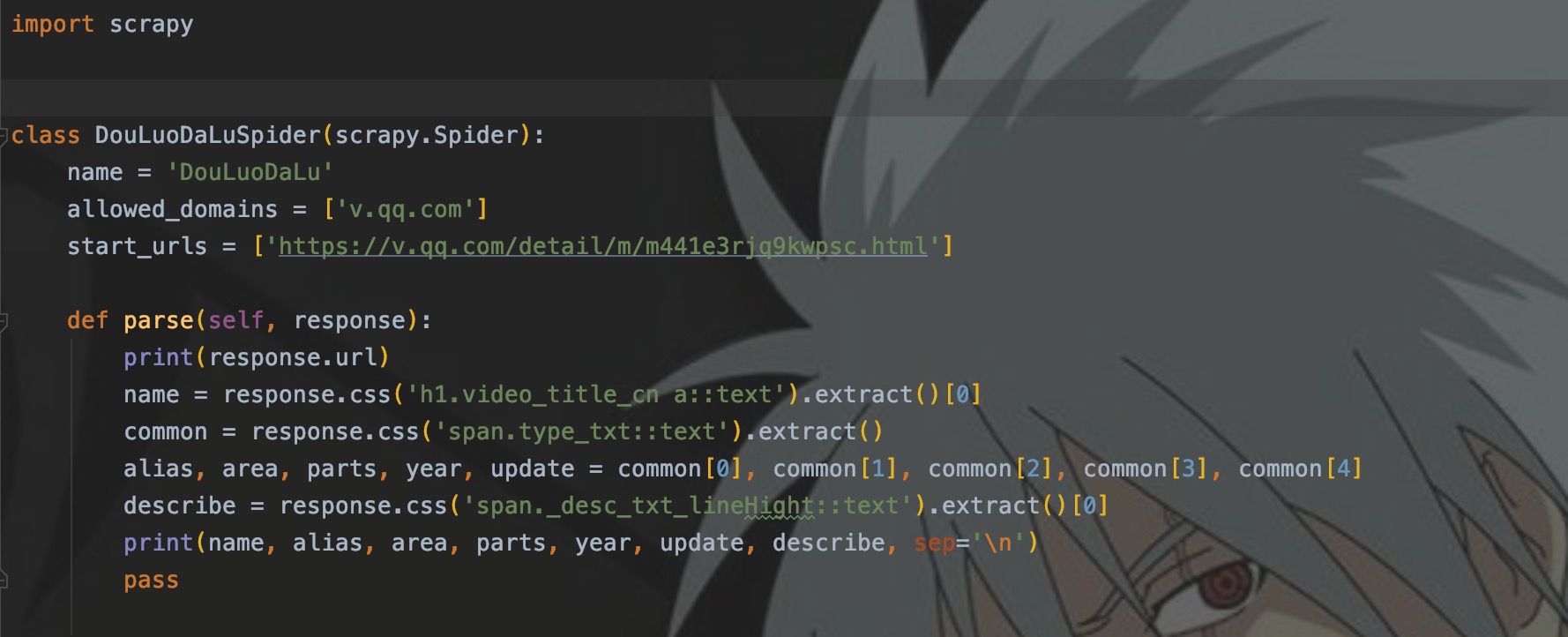
程序结构
每个Scrapy程序都会有三个模块:
- name:每个项目中的爬虫的名称,作为唯一标识用于爬虫的启动
- allowed_domains:主要用于限定运行爬虫网站的域名
- start_urls::网站入口,起始url
- parse:预设的第一个解析函数
上面说道,start_urls是爬虫程序的入口,那么它是怎么发起请求,并将Res响应传给parse解析?作为一个list类型,是否可以有多个入口url?
start_requests()
每个爬虫程序都继承了Spider类,里面的start_requests方法用来发起请求,并自动将响应传递给parse()。
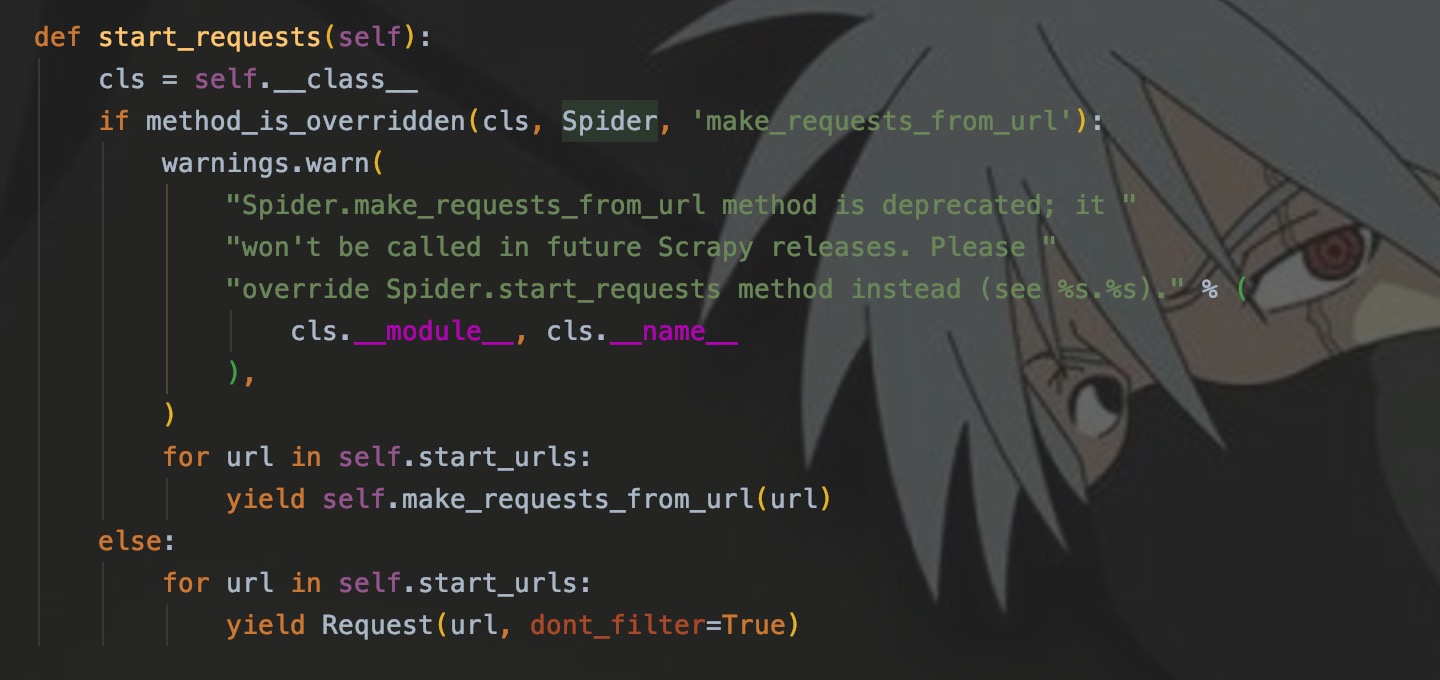
如图,我们可以看到,此方法遍历了start_urls来发起了请求。那么,我就不想传递给parse()解析,我就想自定义方法,啷个怎么办来?
小事莫慌,我们重写start_requests就好了嘛。
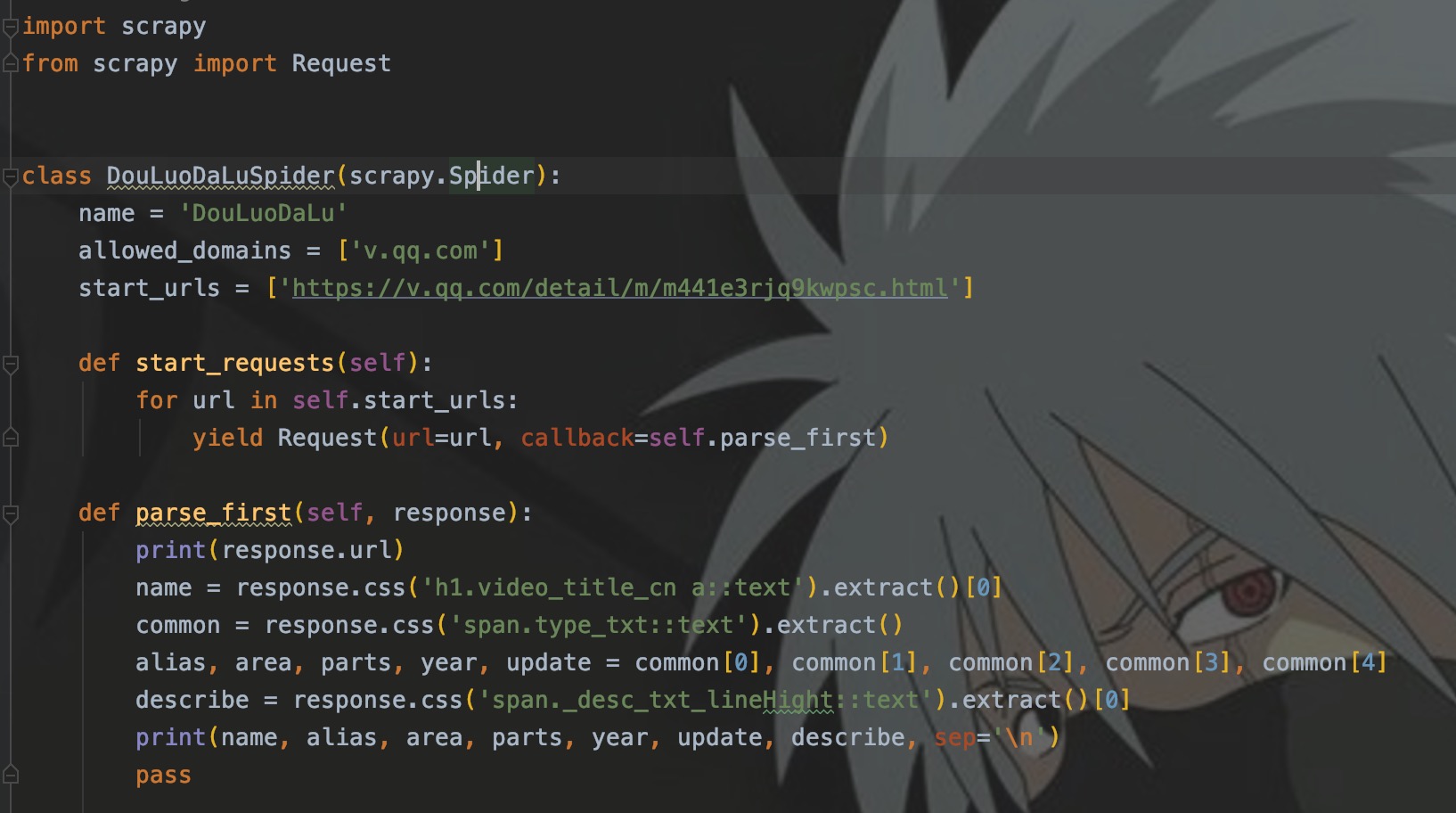
如图,我们自定义了parse_first解析函数,在发起请求时使用callback来指定回调函数,这里记住:函数名一定不要加括号,加括号表示立即执行此函数,不加代表是引用。
修改后的程序输出结果和之前相同。
Request
我们使用yield Request发起一个请求,为什么不用return?因为yield不会立即返回,不会终结方法。这里就涉及到了生成器的问题,有兴趣的可以去研究一下。
Request使用的参数如下顺序排列:
- url:要请求的url
- callback:处理响应的回调函数
- meta:字典,通过响应传递kv数据给回调函数
- dont_filter:默认为False,即开启url去重。如果我们在start_urls写入两条一样的url时,只会输出一次结果,如果我们修改为True,则输出两次。
- method:请求方式,默认为get
- priority:请求优先级,默认为0,数值越大优先级越大
至于cookies、headers参数,我们可以在Request设置,但大多时候都是在下载器middleware中进行设置。
爬虫程序启动
Scrapy爬虫程序的启动主要有两种方式。
命令行启动
第一种就是在scrapy项目目录下的命令行下启动。
scrapy crawl [SpiderName]
这种启动方式的缺点显而易见,就是无法IDE中使用Debug功能,所以这种方式通常用于生产。
IDE启动
我们在开发过程中通常使用第二种启动方式,这也是符合我们常规启动程序的方式。新建一个python程序,引入命令行工具执行爬虫启动命令。
from scrapy.cmdline import execute
if __name__ == "__main__":
execute("scrapy crawl DouLuoDaLu".split(" "))
这样就可以在IDE中启动程序,并使用Debug功能。
scrapy shell交互环境
我们可以shell交互环境中进行解析代码的调试。
scrapy shell https://v.qq.com/detail/m/m441e3rjq9kwpsc.html
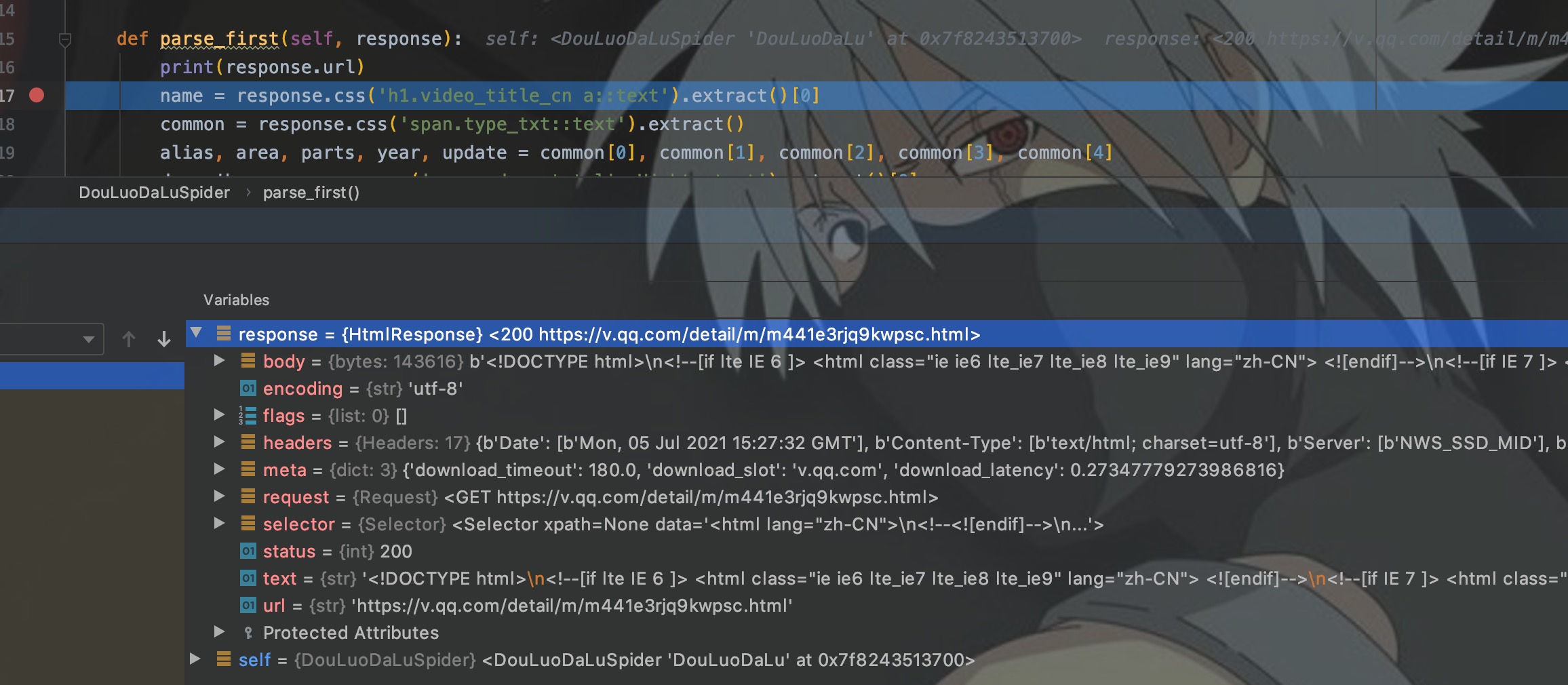
输入命令回车,对斗罗大陆页面发起请求并进入shell环境。
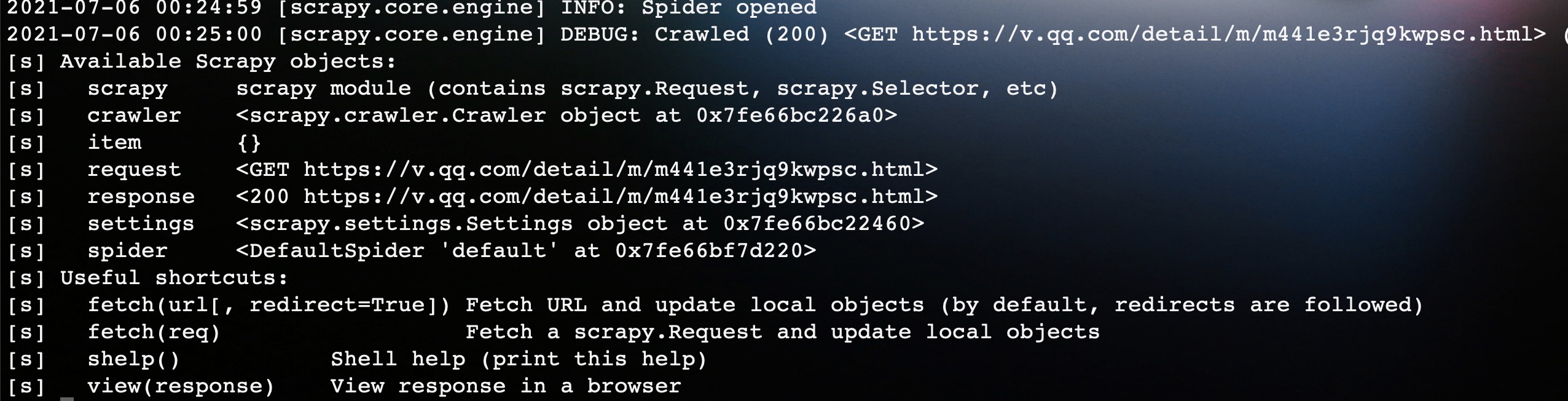
如图所示,在进入shell环境后,自动封装了一些变量,这里我们只关注响应response。
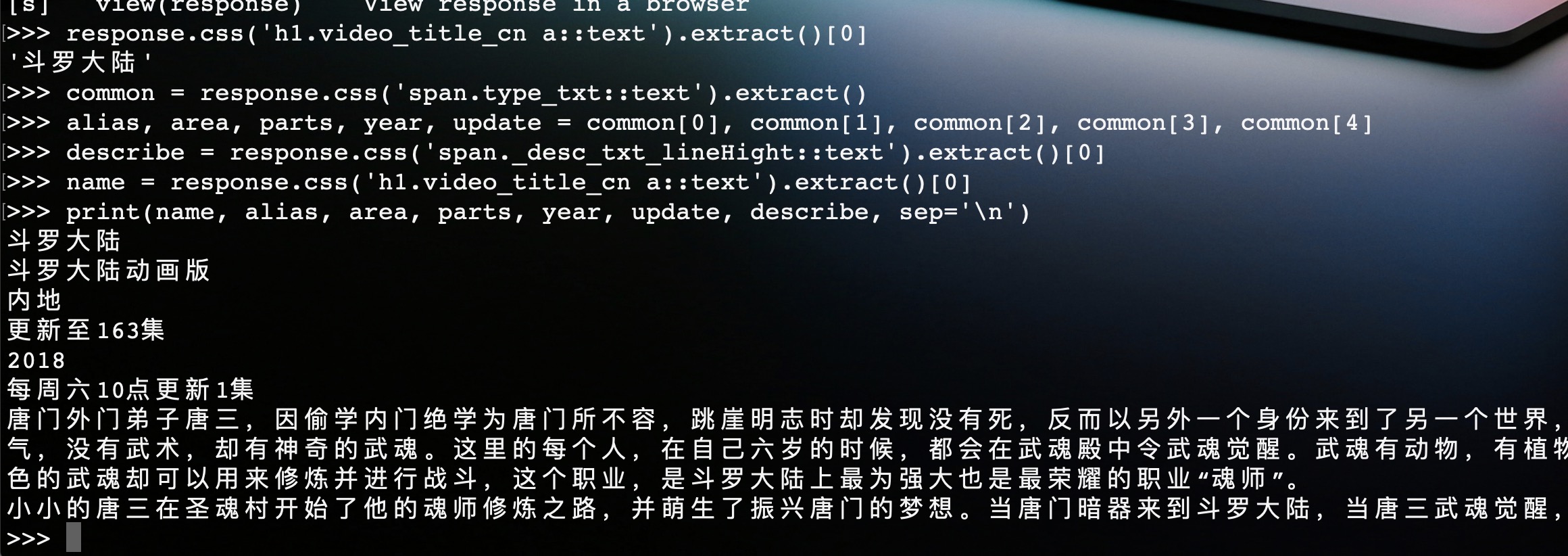
如图,我们在shell交互环境中对网页进行了解析。这样,我们将测试好的解析代码复制到程序中即可,这样提高了开发效率。
输入view(response),敲击回车,将自动在浏览器打开页面。
结语
在样例程序中,请求和响应只在架构图右半边简单地流转,如果想要持久化,还需要定义pipeline等等,而且程序中也只写了一层解析函数,即parse()。
如果在parse中还要进行深度爬取,我们也要在parse中发起请求,并定义新的callback回调函数来进行解析,一直到我们想要的数据页面为止。当然,这些后面都会讲到。
自Scrapy系列写了开篇之后,就搁置了很久。一是最近的确挺忙的,二是Scrapy知识点比较多,一时间不知该从何处写起。不过我还是会继续写下去的,虽然可能更新的有点慢,欢迎小伙伴催更、也希望多多提出宝贵的意见。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

scrapy入门到放弃02:整一张架构图,开发一个程序的更多相关文章
- Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言 MiddleWare,顾名思义,中间件.主要处理请求(例如添加代理IP.添加请求头等)和处理响应 本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件. MiddleWare分类 ...
- Scrapy入门到放弃06:Spider中间件
前言 写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少.因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇. Scrapy-deltafetch插件是在S ...
- Scrapy入门到放弃01:开启爬虫2.0时代
前言 Scrapy is coming!! 在写了七篇爬虫基础文章之后,终于写到心心念念的Scrapy了.Scrapy开启了爬虫2.0的时代,让爬虫以一种崭新的形式呈现在开发者面前. 在18年实习的时 ...
- Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎
前言 代码未动,配置先行.本篇文章主要讲述一下Scrapy中的配置文件settings.py的参数含义,以及如何去获取一个爬虫程序的运行性能指标. 这篇文章无聊的一匹,没有代码,都是配置化的东西,但是 ...
- Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
前言 "又回到最初的起点,呆呆地站在镜子前". 本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再 ...
- Java从入门到放弃——02.常量、变量、数据类型、运算符
本文目标 理解什么是常量,什么是变量 认识八大基本数据类型 了解算数运算符.赋值运算符.关系运算符.逻辑运算符.位运算符.三元运算符 1.什么是常量与变量? 常量是相对静止的量,比如整数:1,2,3 ...
- php从入门到放弃系列-02.php基础语法
php从入门到放弃系列-02.php基础语法 一.学习语法,从hello world开始 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器&qu ...
- 爬虫入门到放弃系列02:html网页如何解析
前言 上一篇文章讲了爬虫的概念,本篇文章主要来讲述一下如何来解析爬虫请求的网页内容. 一个简单的爬虫程序主要分为两个部分,请求部分和解析部分.请求部分基本一行代码就可以搞定,所以主要来讲述一下解析部分 ...
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
随机推荐
- [刷题] 102 Binary Tree Level Order Traversal
要求 对二叉树进行层序遍历 实现 返回结果为双重向量,对应树的每层元素 队列的每个元素是一个pair对,存树节点和其所在的层信息 1 Definition for a binary tree node ...
- 回车与换行的区别:CRLF、CR、LF
引言 以下是 MySQL 8 导出数据的窗口,导出数据时需要选择记录分隔符,这就需要你明白 CRLF.CR 和 LF 分别代表什么,有何区别,否则可能导出数据会出现莫名其米的问题. 名词解释 CR:C ...
- mysql基础之mysql双主(主主)架构
一.概念 在企业中,数据库高可用一直是企业的重中之重,中小企业很多都是使用mysql主从方案,一主多从,读写分离等,但是单主存在单点故障,从库切换成主库需要作改动.因此,如果是双主或者多主,就会增加m ...
- gcc 编译过程详解-(转自CarpenterLee)
前言 C语言程序从源代码到二进制行程序都经历了那些过程?本文以Linux下C语言的编译过程为例,讲解C语言程序的编译过程. 编写hello world C程序: // hello.c #include ...
- Git 系列教程(14)- 远程分支
远程分支 远程引用是对远程仓库的引用(指针),包括分支.标签等等 你可以通过 git ls-remote <remote> 来显式地获得远程引用的完整列表 polo@B-J5D1MD6R- ...
- 只需5分钟!一文读懂CSS布局(二) -- flex布局
目录 简介 基本概念 容器属性 1. flex-direction 测试代码 2. flex-wrap 3. flex-flow 4. justify-content 5. align-items 6 ...
- volatile 关键字笔记
你应该知道的 volatile 关键字 当一个变量被 volatile 修饰时,任何线程对它的写操作都会立即刷新到主内存中,并且会强制让缓存了该变量的线程中的数据清空,必须从主内存重新读取最新数据. ...
- GO语言面向对象05---接口的多态
package main import "fmt" type Fighter interface { Attack() (bloodloss int) Defend() } /*骑 ...
- 编译原理-NFA转化成DFA
1.假定NFA M=<S,∑,f,S0,F> 对M的状态转换图进行以下改造: ①引进新的初态结点X和终态结点Y, X,Y∈S, 从X到S0中的任意结点连一条ε箭弧, ...
- 十二、iptables基本管理
关闭firewalld,启动iptables服务 [root@proxy ~]# systemctl stop firewalld.service //关闭firewalld服务器 [root ...