K8s Scheduler 在调度 pod 过程中遗漏部分节点的问题排查
问题现象
在TKE控制台上新建版本为v1.18.4(详细版本号 < v1.18.4-tke.5)的独立集群,其中,集群的节点信息如下:
有3个master node和1个worker node,并且worker 和 master在不同的可用区。
| node | 角色 | label信息 |
|---|---|---|
| ss-stg-ma-01 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-02 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-ma-03 | master | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200002] |
| ss-stg-test-01 | worker | label[failure-domain.beta.kubernetes.io/region=sh,failure-domain.beta.kubernetes.io/zone=200004] |
待集群创建好之后,再创建出一个daemonset对象,会出现daemonset的某个pod一直卡住pending状态的现象。
现象如下:
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE NODE
debug-4m8lc 1/1 Running 1 89m ss-stg-ma-01
debug-dn47c 0/1 Pending 0 89m <none>
debug-lkmfs 1/1 Running 1 89m ss-stg-ma-02
debug-qwdbc 1/1 Running 1 89m ss-stg-test-01
(补充:TKE当前支持的最新版本号为v1.18.4-tke.8,新建集群默认使用最新版本)
问题结论
k8s的调度器在调度某个pod时,会从调度器的内部cache中同步一份快照(snapshot),其中保存了pod可以调度的node信息。
上面问题(daemonset的某个pod实例卡在pending状态)的原因就是同步的过程发生了部分node信息丢失,导致了daemonset的部分pod实例无法调度到指定的节点上,卡在了pending状态。
接下来是详细的排查过程。
日志排查
截图中出现的节点信息(来自客户线上集群):
k8s master节点:ss-stg-ma-01、ss-stg-ma-02、ss-stg-ma-03
k8s worker节点:ss-stg-test-01
1、获取调度器的日志
这里首先是通过动态调大调度器的日志级别,比如,直接调大到V(10),尝试获取一些相关日志。
当日志级别调大之后,有抓取到一些关键信息,信息如下:

解释一下,当调度某个pod时,有可能会进入到调度器的抢占preempt环节,而上面的日志就是出自于抢占环节。
集群中有4个节点(3个master node和1个worker node),但是日志中只显示了3个节点,缺少了一个master节点。
所以,这里暂时怀疑下是调度器内部缓存cache中少了node info。
2、获取调度器内部cache信息
k8s v1.18已经支持打印调度器内部的缓存cache信息。打印出来的调度器内部缓存cache信息如下:




可以看出,调度器的内部缓存cache中的node info是完整的(3个master node和1个worker node)。
通过分析日志,可以得到一个初步结论:调度器内部缓存cache中的node info是完整的,但是当调度pod时,缓存cache中又会缺少部分node信息。
问题根因
在进一步分析之前,我们先一起再熟悉下调度器调度pod的流程(部分展示)和nodeTree数据结构。
pod调度流程(部分展示)
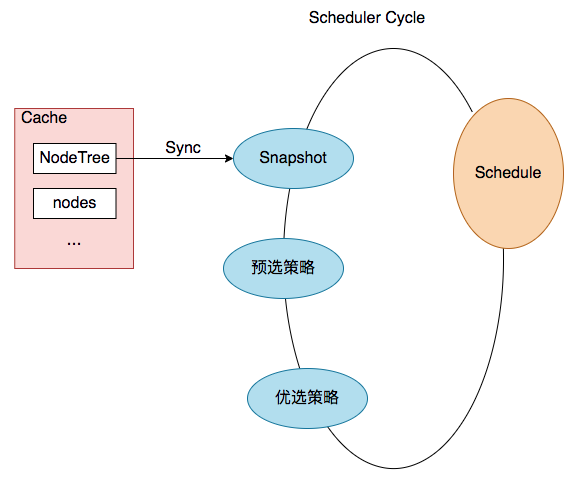
结合上图,一次pod的调度过程就是 一次Scheduler Cycle。 在这个Cycle开始时,第一步就是update snapshot。snapshot我们可以理解为cycle内的cache,其中保存了pod调度时所需的node info,而update snapshot,就是一次nodeTree(调度器内部cache中保存的node信息)到snapshot的同步过程。
而同步过程主要是通过nodeTree.next()函数来实现,函数逻辑如下:
// next returns the name of the next node. NodeTree iterates over zones and in each zone iterates
// over nodes in a round robin fashion.
func (nt *nodeTree) next() string {
if len(nt.zones) == 0 {
return ""
}
numExhaustedZones := 0
for {
if nt.zoneIndex >= len(nt.zones) {
nt.zoneIndex = 0
}
zone := nt.zones[nt.zoneIndex]
nt.zoneIndex++
// We do not check the exhausted zones before calling next() on the zone. This ensures
// that if more nodes are added to a zone after it is exhausted, we iterate over the new nodes.
nodeName, exhausted := nt.tree[zone].next()
if exhausted {
numExhaustedZones++
if numExhaustedZones >= len(nt.zones) { // all zones are exhausted. we should reset.
nt.resetExhausted()
}
} else {
return nodeName
}
}
}
再结合上面排查过程得出的结论,我们可以再进一步缩小问题范围:nodeTree(调度器内部cache)到的同步过程丢失了某个节点信息。
### nodeTree数据结构
(方便理解,本文使用了链表来展示)
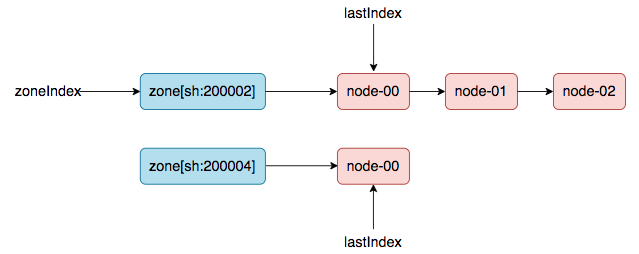
在nodeTree数据结构中,有两个游标zoneIndex 和 lastIndex(zone级别),用来控制 nodeTree(调度器内部cache)到snapshot.nodeInfoList的同步过程。并且,重要的一点是:上次同步后的游标值会被记录下来,用于下次同步过程的初始值。
### 重现问题,定位根因
创建k8s集群时,会先加入master node,然后再加入worker node(意思是worker node时间上会晚于master node加入集群的时间)。
第一轮同步:3台master node创建好,然后发生pod调度(比如,cni 插件,以daemonset的方式部署在集群中),会触发一次nodeTree(调度器内部cache)到的同步。同步之后,nodeTree的两个游标就变成了如下结果:
nodeTree.zoneIndex = 1,
nodeTree.nodeArray[sh:200002].lastIndex = 3,
第二轮同步:当worker node加入集群中后,然后新建一个daemonset,就会触发第二轮的同步(nodeTree(调度器内部cache)到的同步)。同步过程如下:
1、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
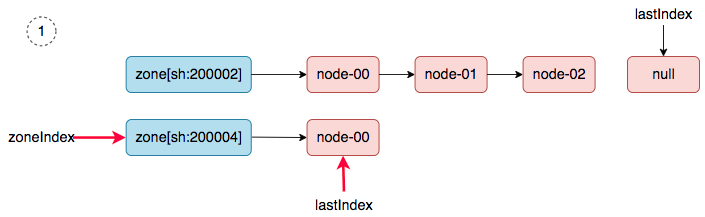
2、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=3, return.
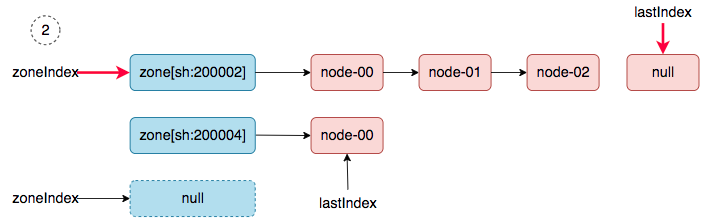
3、 zoneIndex=1, nodeArray[sh:200004].lastIndex=1, return.
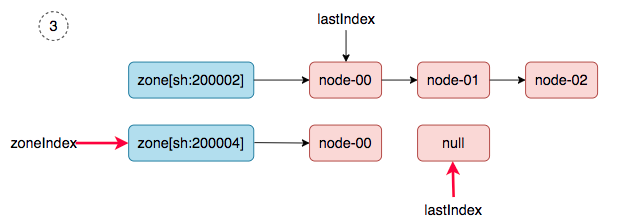
4、 zoneIndex=0, nodeArray[sh:200002].lastIndex=0, we get ss-stg-ma-01.
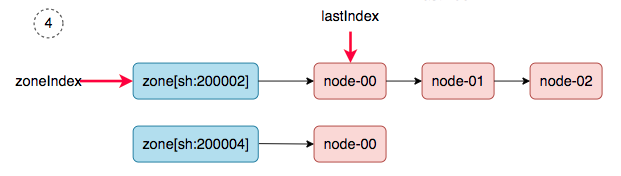
5、 zoneIndex=1, nodeArray[sh:200004].lastIndex=0, we get ss-stg-test-01.
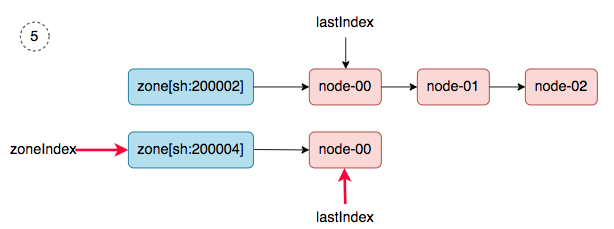
6、 zoneIndex=2 >= len(zones); zoneIndex=0, nodeArray[sh:200002].lastIndex=1, we get ss-stg-ma-02.
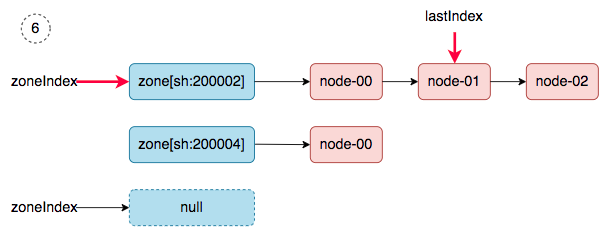
同步完成之后,调度器的snapshot.nodeInfoList得到如下的结果:
[
ss-stg-test-01,
ss-stg-ma-01,
ss-stg-test-01,
ss-stg-ma-02,
]
ss-stg-ma-03 去哪了?在第二轮同步的过程中丢了。
解决方案
从问题根因的分析中,可以看出,导致问题发生的原因,在于 nodeTree 数据结构中的游标 zoneIndex 和 lastIndex(zone级别)值被保留了,所以,解决的方案就是在每次同步SYNC时,强制重置游标(归0)。
相关issue:https://github.com/kubernetes/kubernetes/issues/97120
相关pr(k8s v1.18): https://github.com/kubernetes/kubernetes/pull/93387
TKE修复版本:v1.18.4-tke.5
K8s Scheduler 在调度 pod 过程中遗漏部分节点的问题排查的更多相关文章
- ambari过程中要求各个节点时间同步
设置时间同步 控制节点机器 cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime #设置时区为北京时间,这里为上海,因为centos里面只有上海... ...
- Kubernetes集群搭建过程中遇到的问题
1. 创建Nginx Pod过程中报如下错误: #kubectlcreate -f nginx-pod.yaml Error from server: error when creating &quo ...
- 国内不fq安装K8S四: 安装过程中遇到的问题和解决方法
目录 4 安装过程中遇到的问题和解决方法 4.1 常见问题 4.2 常用的操作命令 4.3 比较好的博客 国内不fq安装K8S一: 安装docker 国内不fq安装K8S二: 安装kubernet 国 ...
- 十五,K8S集群调度原理及调度策略
目录 k8s调度器Scheduler Scheduler工作原理 请求及Scheduler调度步骤: k8s的调用工作方式 常用预选策略 常用优先函数 节点亲和性调度 节点硬亲和性 节点软亲和性 Po ...
- k8s集群调度方案
Scheduler是k8s集群的调度器,主要的任务是把定义好的pod分配到集群节点上 有以下特征: 1 公平 保证每一个节点都能被合理分配资源或者能被分配资源 2 资源高效利用 集群所有资 ...
- k8s运维之pod排错
k8s运维之pod排错 K8S是一个开源的,用于管理云平台中多个主机上的容器化应用,Kubernetes的目标是让部署容器化变得简单并且高效 K8S的核心优势: 1,基于yaml文件实现容器的自动创建 ...
- k8s核心资源之Pod概念&入门使用讲解(三)
目录 1. k8s核心资源之Pod 1.1 什么是Pod? 1.2 Pod如何管理多个容器? 1.3 Pod网络 1.4 Pod存储 1.5 Pod工作方式 1.5.1 自主式Pod 1.5.2 控制 ...
- Cocos2d-x 3.x 学习笔记(三):Scheduler Timer 调度与定时
1. 概述 Cocos2d-x 的 Scheduler 离不开 Timer.Timer 类是定时器,用来规定一个回调函数应该在何时被触发.Timer 封装了已运行时间.重复次数.已执行次数.延迟秒数 ...
- k8s之深入解剖Pod(三)
目录: Pod的调度 Pod的扩容和缩容 Pod的滚动升级 一.Pod的调度 Pod只是容器的载体,通常需要通过RC.Deployment.DaemonSet.Job等对象来完成Pod的调度和自动控制 ...
随机推荐
- 电影AI修复,让重温经典有了新的可能
摘要:有没有一种呈现,不以追求商业为第一目的,不用花大价钱,不用翻拍,没有画蛇添足,低成本的可共赏的让经典更清晰? 本文分享自华为云社区<除了重映和翻拍,重温经典的第三种可能>,原文作者: ...
- Airtest简单上手讲解
Airtest是网易开发的手机UI界面自动化测试工具,它原本的目的是通过所见即所得,截图点击等等功能,简化手机App图形界面测试代码编写工作. 安装和使用 由于本文的目的是介绍如何使用Airtest来 ...
- 服务器安装部署-01-MySQL
1 MySQL 1.1 安装 在root用户权限下 # 创建mysql用户和用户组,同时禁止登陆 shell> groupadd mysql shell> useradd -r -g my ...
- 基于阿里云托管kubernetes的版本升级
前言 因为阿里云的knative对应得k8s版本大于1.15,而我们目前得集群环境是1.14.8,因此需要对预发环境进行版本升级.基于aliyun托管的kubernetes集群版本升级本没有什么可写, ...
- Linux 常用系统性能命令总结
Linux 常用系统性能命令 查看系统负载top,free **w/uptime ** 最后面三个数字表示1分钟,5分钟,15分钟平均有多少个进程占用CPU占用CPU的进程可以是Running,也可 ...
- angular+ionic -- 启动命令
初始angular+ionic项目,启动需ionic的启动命令: ionic serve
- mysql 批量操作,已存在则修改,不存在则insert,同时判断空选择性写入字段
注:如果是批量插入需要在 Java 连接数据库的字串中设置 &allowMultiQueries=true 针对单行数据有则修改无则新增 本案例的建表语句是: -- auto-generate ...
- OO_Unit4_Summary暨课程总结
初始oo,有被往届传言给吓到:oo进行中,也的确有时会被作业困扰(debug到差点放弃):而oo即将结束的此刻,却又格外感慨这段oo历程. 一.单元架构设计 本单元任务是设计一个UML解析器,能够支持 ...
- oo第四单元——UML图解析
本单元是在理解UML图的基础上实现对图的解析和检查.UML图是新接触的一种建模工具,一开始接触UML的时候觉得理解起来比较困难,并不能单纯从代码的角度按照类.方法这样来理解,这只是从类图的角度,还有从 ...
- 机器学习--PR曲线, ROC曲线
在机器学习领域,如果把Accuracy作为衡量模型性能好坏的唯一指标,可能会使我们对模型性能产生误解,尤其是当我们模型输出值是一个概率值时,更不适宜只采取Accuracy作为衡量模型性泛化能的指标.这 ...