python-cmdb资产管理项目4-资产入库处理以及资产变更记录处理
一 资产入库处理
1.1 连接数据库
在192.168.100.101安装数据库,并给总控机授权可以操作,并创建一个autoserver的数据库,密码123456
settiing.py 配置数据库连接
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'autoserver',
'HOST': '192.168.100.101',
'PORT': 3306,
'USER': "root",
'PASSWORD': "123456",
}
}
1.2 创建数据库和表
创建数据库方法参考https://www.cnblogs.com/zyxnhr/p/12629172.html
/home/ningherui/PycharmProjects/cmdb_first_step/autoserver/api/models.py
from django.db import models # Create your models here.
class Server(models.Model):
# server_table,服务器表
hostname = models.CharField(verbose_name="主机名",max_length=32) class Disk(models.Model):
# disk_table,硬盘信息表
slot = models.CharField(verbose_name="槽位",max_length=32)
pd_type = models.CharField(verbose_name="类型",max_length=32)
capacity = models.CharField(verbose_name="容量",max_length=32)
model = models.CharField(verbose_name="型号",max_length=32)
server = models.ForeignKey(verbose_name="服务器",to='Server',on_delete=models.CASCADE)
执行 python3 manage.py makemigrations

执行python3 manage.py migrate查看数据库
autoserver的view文件如下
/home/ningherui/PycharmProjects/cmdb_first_step/autoserver/api/views.py
import json
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
# Create your views here.
@csrf_exempt
def get_data(request):
#print(request.body)
#序列化和反序列化
content = request.body.decode('utf-8')
server_info_dict = json.loads(content)
hostname = server_info_dict['host']
info_dict = server_info_dict['info']
print(info_dict['disk'])
#获取数据之后,把他们放到数据库,然后使用web的APP展示数据
return HttpResponse('成功')
运行autoserver,执行autoclient的app.py,执行,获取disk信息如下
{'status': True, 'data': {
'1': {'slot': '1', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'jinshidun'},
'2': {'slot': '2', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'Samsung'},
'3': {'slot': '3', 'pd_type': 'SATA', 'capacity': '900.12', 'model': 'huawei'},
}, 'error': None}
将上述信息,写入数据库中,这种方式也可以做成模块化的方式
1.3 采集资产的硬盘信息
建立一个server的目录,其中也包含disk.py处理硬盘信息
/home/ningherui/PycharmProjects/cmdb_first_step/autoserver/api/service/disk.py
from api import models
def process_disk_info(host_object,disk_dict):
'''
处理汇报来的硬盘信息
:return:
'''
if not disk_dict['status']:
print('硬盘资产信息没有获取到')
print('获取硬盘资产时报错:',disk_dict['error'])
return
print(disk_dict)
new_disk_dict = disk_dict['data']
#数据库中的硬盘信息
db_disk_queryset = models.Disk.objects.filter(server=host_object).all()
db_disk_dict = {row.slot:row for row in db_disk_queryset}
print(new_disk_dict)
print('===========================')
print(db_disk_dict)
结果如下:
{
'0': {'slot': '0', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'jinshidun'},
'2': {'slot': '2', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'Samsung'},
'3': {'slot': '3', 'pd_type': 'SATA', 'model': 'huawei'
}} #new_disk_dict 新采集的数据
===========================
{'
1': <Disk: Disk object (1)> #db_disk_dict 从数据库中获取的数据
}
然后进行更新数据库信息
'''
更新数据库信息
models.User.objects.filter(id=3).update(age=18)
obj = models.User.objects.filter(id=3).first()
obj.age = 19
obj.save()
'''
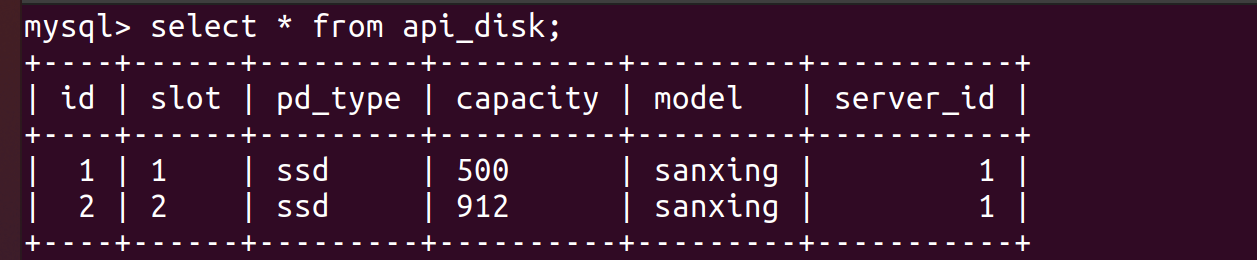
数据在插入一条数据,则数据库中有两条数据
insert into api_disk values("2","2","ssd","912","sanxing","1");
对数据库进行操作的逻辑:
from api import models
def process_disk_info(host_object,disk_dict):
'''
处理汇报来的硬盘信息
:return:
'''
if not disk_dict['status']:
print('硬盘资产信息没有获取到')
print('获取硬盘资产时报错:',disk_dict['error'])
return
# print(disk_dict)
new_disk_dict = disk_dict['data']
#set 就可以取出key值变成集合
new_disk_slot_set = set(new_disk_dict)
#数据库中的硬盘信息
db_disk_queryset = models.Disk.objects.filter(server=host_object).all()
db_disk_dict = {row.slot:row for row in db_disk_queryset}
db_disk_slot_set = set(db_disk_dict)
# 如果数据库中没有,就创建数据,用new_disk_slot_set - db_disk_slot_set就是数据库中没有的,则创建
create_slot_set = new_disk_slot_set - db_disk_slot_set
#如果数据库中有,而采集的数据没有,则删除
remove_slot_set = db_disk_slot_set - new_disk_slot_set
#如果数据库和新增数据都有,但是数据有变化,则更新数据
update_slot_set = new_disk_slot_set & db_disk_slot_set
print("增加",create_slot_set)
print("删除",remove_slot_set)
print("更新",update_slot_set)
结果如下
增加 {'0', '3'}
删除 {'1'}
更新 {'2'}
进行操作
更新数据时,需要提取数据
for slot in update_slot_set:
# new_disk_dict[slot] #'0': {'slot': '0', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'jinshidun'}
# db_disk_dict[slot] # 对象
#循环新数据的key和value
for key,value in new_disk_dict[slot].items():
# 每一项数据库中的值,获取对象的某一个值,对象.x 等同于getatt("对象",'x') ---> getattr(db_disk_dict[slot],key)
# 每一项新增的值 ---> value
print(key,value,getattr(db_disk_dict[slot],key))

整个对数据库的操作代码如下:
from api import models
def process_disk_info(host_object,disk_dict):
'''
处理汇报来的硬盘信息
:return:
'''
if not disk_dict['status']:
print('硬盘资产信息没有获取到')
print('获取硬盘资产时报错:',disk_dict['error'])
return
# print(disk_dict)
new_disk_dict = disk_dict['data']
#set 就可以取出key值变成集合
new_disk_slot_set = set(new_disk_dict)
#数据库中的硬盘信息
db_disk_queryset = models.Disk.objects.filter(server=host_object).all()
db_disk_dict = {row.slot:row for row in db_disk_queryset}
db_disk_slot_set = set(db_disk_dict)
# 如果数据库中没有,就创建数据,用new_disk_slot_set - db_disk_slot_set就是数据库中没有的,则创建
create_slot_set = new_disk_slot_set - db_disk_slot_set
print("增加",create_slot_set)
for slot in create_slot_set:
#**表示对字典操作
models.Disk.objects.create(**new_disk_dict[slot],server=host_object)
#如果数据库中有,而采集的数据没有,则删除
remove_slot_set = db_disk_slot_set - new_disk_slot_set
print("删除", remove_slot_set)
models.Disk.objects.filter(server=host_object,slot__in=remove_slot_set).delete()
#如果数据库和新增数据都有,但是数据有变化,则更新数据
update_slot_set = new_disk_slot_set & db_disk_slot_set
print("更新",update_slot_set)
for slot in update_slot_set:
# new_disk_dict[slot] #'0': {'slot': '0', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'jinshidun'}
# db_disk_dict[slot] # 对象
#循环新数据的key和value
for key,value in new_disk_dict[slot].items():
# 每一项数据库中的值,获取对象的某一个值,对象.x 等同于getatt("对象",'x') ---> getattr(db_disk_dict[slot],key)
# 每一项新增的值 ---> value
#print(key,value,getattr(db_disk_dict[slot],key))
#进行赋值更新操作
setattr(db_disk_dict[slot],key,value)
#写入数据库
db_disk_dict[slot].save()
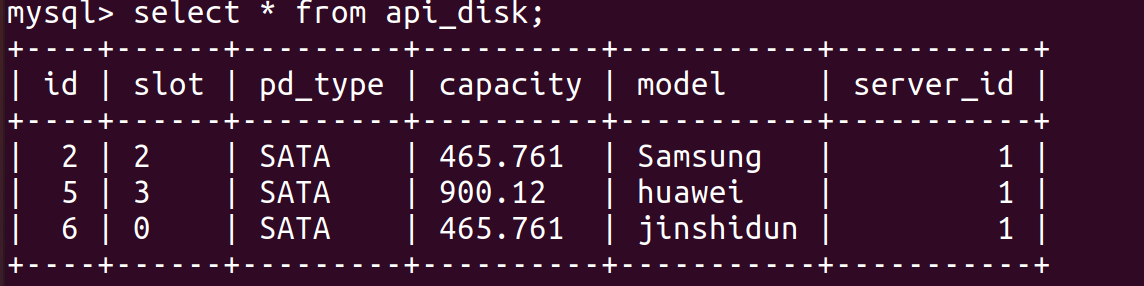
操作后,查看数据库已经更新:
二 资产变更记录
2.1 建表
创建一个新的表,存放变更记录
/home/ningherui/PycharmProjects/cmdb_first_step/autoserver/api/models.py
from django.db import models # Create your models here.
class Server(models.Model):
# server_table 服务器表
hostname = models.CharField(verbose_name="主机名",max_length=32) class Disk(models.Model):
# disk_table,硬盘信息表
slot = models.CharField(verbose_name="槽位",max_length=32)
pd_type = models.CharField(verbose_name="类型",max_length=32)
capacity = models.CharField(verbose_name="容量",max_length=32)
model = models.CharField(verbose_name="型号",max_length=32)
server = models.ForeignKey(verbose_name="服务器",to='Server',on_delete=models.CASCADE) class AssetsRecord(models.Model):
'''
资产变更记录
'''
content = models.TextField(verbose_name="内容")
server = models.ForeignKey(verbose_name="服务器",to='Server',on_delete=models.DO_NOTHING)
create_data = models.DateTimeField(verbose_name="时间",auto_now=True)
2.2 更新disk数据处理
from api import models
def process_disk_info(host_object,disk_dict):
'''
处理汇报来的硬盘信息
:return:
'''
if not disk_dict['status']:
print('硬盘资产信息没有获取到')
print('获取硬盘资产时报错:',disk_dict['error'])
return
# print(disk_dict)
new_disk_dict = disk_dict['data']
#set 就可以取出key值变成集合
new_disk_slot_set = set(new_disk_dict)
#数据库中的硬盘信息
db_disk_queryset = models.Disk.objects.filter(server=host_object).all()
db_disk_dict = {row.slot:row for row in db_disk_queryset}
db_disk_slot_set = set(db_disk_dict)
# 如果数据库中没有,就创建数据,用new_disk_slot_set - db_disk_slot_set就是数据库中没有的,则创建
create_slot_set = new_disk_slot_set - db_disk_slot_set
record_str_list = []
print("增加",create_slot_set)
for slot in create_slot_set:
#**表示对字典操作
models.Disk.objects.create(**new_disk_dict[slot],server=host_object)
msg = "[新增硬盘]槽位:{slot},类型{pd_type},容量{capacity}".format(**new_disk_dict[slot])
record_str_list.append(msg)
#如果数据库中有,而采集的数据没有,则删除
remove_slot_set = db_disk_slot_set - new_disk_slot_set
print("删除", remove_slot_set)
models.Disk.objects.filter(server=host_object,slot__in=remove_slot_set).delete()
if remove_slot_set:
msg = "[删除硬盘]槽位:{}".format(','.join(remove_slot_set))
record_str_list.append(msg)
#如果数据库和新增数据都有,但是数据有变化,则更新数据
update_slot_set = new_disk_slot_set & db_disk_slot_set
print("更新",update_slot_set)
for slot in update_slot_set:
# new_disk_dict[slot] #'0': {'slot': '0', 'pd_type': 'SATA', 'capacity': '465.761', 'model': 'jinshidun'}
# db_disk_dict[slot] # 对象
temp = []
#循环新数据的key和value
for key,value in new_disk_dict[slot].items():
# 每一项数据库中的值,获取对象的某一个值,对象.x 等同于getatt("对象",'x') ---> getattr(db_disk_dict[slot],key)
# 每一项新增的值 ---> value
#print(key,value,getattr(db_disk_dict[slot],key))
old_vaule = getattr(db_disk_dict[slot],key)
if value == old_vaule:
continue
msg = "硬盘的{},由{}变成了{}".format(key,old_vaule,value)
temp.append(msg)
#进行赋值更新操作
setattr(db_disk_dict[slot],key,value)
#写入数据库
if temp:
db_disk_dict[slot].save()
row = "[更新硬盘]槽位:{},更新的内容:{}".format(slot,':'.join(temp))
record_str_list.append(row) print(record_str_list)
if record_str_list:
models.AssetsRecord.objects.create(content="\n".join(record_str_list),server=host_object)
格式化字符串
"(a1)s-asdfccdas %(a2)s" %{'a1':1,'a2':123456}
"{a1}-asedf{a2}".format(**{'a1':1,'a2':'alex'})
2.3 结果信息
更改数据库或者disk.out的内容,执行效果如下:

已获得更改记录
感谢老男孩教育
python-cmdb资产管理项目4-资产入库处理以及资产变更记录处理的更多相关文章
- CMDB服务器管理系统【s5day89】:部分数据表结构-资产入库思路
1.用django的app作为统一调用库的好处 1.创建repository app截图如下: 2.好处如下: 1.app的本质就是一个文件夹 2.以后所有的app调用数据就只去repository调 ...
- CMDB03 /今日未采集的资产、资产入库、资产变更记录、资产采集
CMDB03 /今日未采集的资产.资产入库.资产变更记录.资产采集 目录 CMDB03 /今日未采集的资产.资产入库.资产变更记录.资产采集 1. 获取今日未采集的服务器 2. server资产入库以 ...
- 2016年GitHub排名前20的Python机器学习开源项目(转)
当今时代,开源是创新和技术快速发展的核心.本文来自 KDnuggets 的年度盘点,介绍了 2016 年排名前 20 的 Python 机器学习开源项目,在介绍的同时也会做一些有趣的分析以及谈一谈它们 ...
- cocos2d-x使用python脚本创建项目的简单方法
本文有CC原创,转载请注明地址:http://blog.csdn.net/oktears/article/details/13297003 在cocos2d-x2.1.4以上的版本中,取消了使用vs模 ...
- Python CMDB开发
Python CMDB开发 运维自动化路线: cmdb的开发需要包含三部分功能: 采集硬件数据 API 页面管理 执行流程:服务器的客户端采集硬件数据,然后将硬件信息发送到API,API负责将获取 ...
- 10个Python基础练习项目,你可能不会想到练手教程还这么有趣
美国20世纪最重要的实用主义哲学家约翰·杜威提出一个学习方法,叫做:Learning By Doing,在实践中精进.胡适.陶行知.张伯苓.蒋梦麟等都曾是他的学生,杜威的哲学也影响了蔡元培.晏阳初等人 ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- Python NLP完整项目实战教程(1)
一.前言 打算写一个系列的关于自然语言处理技术的文章<Python NLP完整项目实战>,本文算是系列文章的起始篇,为了能够有效集合实际应用场景,避免为了学习而学习,考虑结合一个具体的项目 ...
- Python+Flask+Gunicorn 项目实战(一) 从零开始,写一个Markdown解析器 —— 初体验
(一)前言 在开始学习之前,你需要确保你对Python, JavaScript, HTML, Markdown语法有非常基础的了解.项目的源码你可以在 https://github.com/zhu-y ...
随机推荐
- windows认证解读
0x00 本地认证 本地认证基础知识 在本地登录Windows的情况下,操作系统会使用用户输入的密码作为凭证去与系统中的密码进行验证,但是操作系统中的密码存储在哪里呢? %SystemRoot%\sy ...
- Java中获取类的运行时结构
获取运行时类的完整结构 通过反射获取运行时类的完整结构 Field(属性).Method(方法).Constructor(构造器).Superclass(父类).Interface(接口).Annot ...
- 从一个Demo开始,揭开Netty的神秘面纱
本文是Netty系列第5篇 上一篇文章我们对于I/O多路复用.Java NIO包 和 Netty 的关系有了全面的认识. 到目前为止,我们已经从I/O模型出发,逐步接触到了Netty框架.这个过程中, ...
- [源码分析] 分布式任务队列 Celery 多线程模型 之 子进程
[源码分析] 分布式任务队列 Celery 多线程模型 之 子进程 目录 [源码分析] 分布式任务队列 Celery 多线程模型 之 子进程 0x00 摘要 0x01 前文回顾 1.1 基类作用 1. ...
- JDBC_12_JDBC事务
JDBC事务 JDBC中事务默认自动提交,每执行一次SQL就会自动提交一次. 这样的话可能出现数据安全性问题. connection.setAutoCommit(false) false代表关闭自动提 ...
- Effective Java 笔记
1. 静态工厂 静态工厂的第 5 个优点是,在编写包含该方法的类时,返回的对象的类不需要存在.他的意思是面向接口编程??就是说我们只需知道接口,具体实现类是否存在没有关系?? 只提供静态工厂方法的主要 ...
- git merge --ff/--no-ff/--ff-only 三种选项参数的区别
前言 git merge 应该是开发者最常用的 git 指令之一, 默认情况下你直接使用 git merge 命令,没有附加任何选项命令的话,那么应该是交给 git 来判断使用哪种 merge 模式, ...
- animation几个比较好玩的属性(alternate,及animation-fill-mode)
<!DOCTYPE html> <html> <head> <style> div { width:100px; height:100px; backg ...
- Nessus扫描器的使用
目录 Nessus Scans Settings 一个基本扫描的建立 自定义扫描策略 Nessus的高级扫描方法 Nessus Nessus号称是世界上最流行的漏洞扫描程序,全世界有超过75000个组 ...
- hdu3374最小表示法+KMP
题意: 给你一个最长100W的串,然后让你找到最小同构子串,还有最大同构子串的下标,最小同构子串就是把字符串连接成一个环,然后选择一个地方断开,得到的一个ASCII最小的子串(求最大同理) ...