Pythonweb采集
一.访问页面
import webbrowser
webbrowser.open('http://www.baidu.com/')
pip3 install requests
import requests
res = requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
res.status_code == requests.codes.ok #返回真假
len(res.text) #变量保存
print(res.text[:250])
res.raise_for_status() #下载出错抛出异常,成功则不返回
playFile = open('a.txt', 'wb') #写入二进制文件,保存Unicode编码
for chunk in res.iter_content(100000): #指定字节数
playFile.write(chunk)
playFile.close()
pip3 install sqlalchemy
import sqlalchemy as sa
conn = sa.create_engine('sqlite://')
meta = sa.MetaData()
zoo = sa.Table('zoo', meta,
sa.Column('critter', sa.String, primary_key=True),
sa.Column('count', sa.Integer),
sa.Column('damages', sa.Float)
)
meta.create_all(conn)
conn.execute(zoo.insert(('bear', 2, 1000.0)))
conn.execute(zoo.insert(('weasel', 1, 2000.0)))
result = conn.execute(zoo.select()) #类似select *
rows = result.fetchall()
print(rows)
#web
import urllib.request as ur
url = 'http://www.iheartquotes.com/api/v1/random'
conn = ur.urlopen(url)
print(conn)
data = conn.read() #获取网页数据
print(data)
conn.status #状态码
print(conn.getheader('Content-Type')) #数据格式
for key, value in conn.getheaders(): #查看所有http头
print(key, value)
pip3 install requests
import requests
url = 'http://www.iheartquotes.com/api/v1/random'
resp = requests.get(url)
resp
<Response [200]>
print(resp.text)
二.页面过滤
pip3 install beautifulsoup4
import requests,bs4
res = requests.get('http://nostarch.com')
res.raise_for_status()
noStarchSoup = bs4.BeautifulSoup(res.text)
exampleFile = open('example.html')
exampleSoup = bs4.BeautifulSoup(exampleFile)
soup.select('p #author')
soup.select('p')[0] #只取第一个放里面
xx.get('id') #返回id的值
三.CSS选择器例子
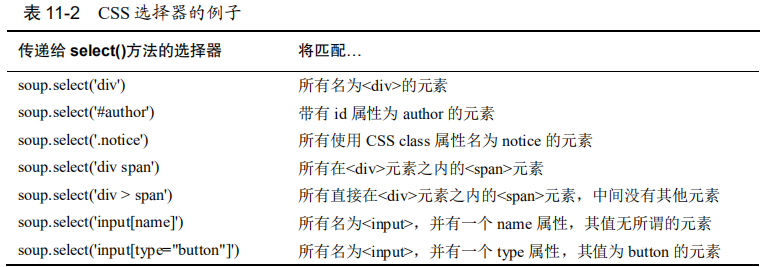
四.实际例子
example.html
<!-- This is the example.html example file. -->
<html><head><title>The Website Title</title></head>
<body>
<p>Download my <strong>Python</strong> book from <a href="http://
inventwithpython.com">my website</a>.</p>
<p class="slogan">Learn Python the easy way!</p>
<p>By <span id="author">Al Sweigart</span></p>
</body></html>
#过滤文件的id
import bs4
exampleFile = open('example.html') #打开到对象
exampleSoup = bs4.BeautifulSoup(exampleFile,features="html.parser")
elems = exampleSoup.select('#author') #找寻id元素,返回列表 tag对象到变量
print(type(elems))
print(type(elems[0]))
print(len(elems)) #看有几个匹配结果
print(elems[0].getText()) #返回第一个结果
print(str(elems[0])) #返回字符串,包含标签和文本
print(elems[0].attrs) #返回字典ID和值
#循环输出
import bs4
exampleFile = open('example.html') #打开到对象
exampleSoup = bs4.BeautifulSoup(exampleFile,features="html.parser")
elems = exampleSoup.select('p')
for i in range(len(elems)):
print(str(elems[i]))
print(elems[i].getText())
Pythonweb采集的更多相关文章
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- 再谈C#采集,一个绕过高强度安全验证的采集方案?方案很Low,慎入
说起采集,其实我是个外行,以前拔过阿里巴巴的客户数据,在我博客的文章:C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子) 中,介绍过采集用的工具,其实很Low的,分析 ...
- iOS从零开始学习直播之2.采集
直播的采集由采集的设备(摄像头.话筒)不同分为视频采集和音频采集,本篇文章会分别介绍. 1.采集步骤 1.创建捕捉会话(AVCaptureSession),iOS调用相机和话筒之前都需要创建捕 ...
- 让OMCS支持更多的视频采集设备
有些OMCS用户在他的系统使用了特殊的视频采集卡作为视频源(如AV-878采集卡),虽然这些采集卡可以虚拟为一个摄像头,但有些视频采集卡需要依赖于自带了sdk才能正常地完成视频采集工作.在这种情况下, ...
- NodeJs+http+fs+request+cheerio 采集,保存数据,并在网页上展示(构建web服务器)
目的: 数据采集 写入本地文件备份 构建web服务器 将文件读取到网页中进行展示 目录结构: package.json文件中的内容与上一篇一样:NodeJs+Request+Cheerio 采集数据 ...
- NodeJs+Request+Cheerio 采集数据
目的:采集网站文章. 两个依赖项: request :https://github.com/request/request cheerio:https://github.com/cheeriojs/c ...
- Hawk 3. 网页采集器
1.基本入门 1. 原理(建议阅读) 网页采集器的功能是获取网页中的数据(废话).通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍,在页面中只有一个).因此 ...
- 火车头dede采集接口,图片加水印,远程图片本地化,远程无后缀的无图片本地化
<?php /* [LocoySpider] (C)2005-2010 Lewell Inc. 火车采集器 DedeCMS 5.7 UTF8 文章发布接口 Update content: 图片加 ...
- STM32F412应用开发笔记之三:SPI总线通讯与AD采集
本次我们在NUCLEO-F412ZG试验模拟量输入采集.我们的模拟量输入采用ADI公司的AD7705,是一片16位两路差分输入的AD采集芯片.具有SPI接口,我们将采用SPI接口与AD7705通讯.两 ...
随机推荐
- Numpy (嵩老师.)
import numpy as np Numpy 一元函数 对ndarray中的数据执行元素级运算的函数 np.abs(x) np.fabs(x) 计算数组各元素的绝对值 np.sqrt(x) 计算数 ...
- Roslyn 编译器Api妙用:动态生成类并实现接口
在上一篇文章中有讲到使用反射手写IL代码动态生成类并实现接口. 反射的妙用:C#通过反射动态生成类型继承接口并实现 有位网友推荐使用 Roslyn 去脚本化动态生成,今天这篇文章就主要讲怎么使用 Ro ...
- CTF入门学习2->Web基础了解
Web安全基础 00 Web介绍 00-00 Web本意是网,这里多指万维网(World Wide Web),是由许多互相连接的超文本系统组成的,通过互联网访问. Web是非常广泛的互联网应用,每天都 ...
- python实现对象测量
目录: 问题,轮廓找到了,如何去计算对象的弧长与面积(闭合),多边形拟合,几何矩的计算等 (一)对象的弧长与面积 (二)多边形拟合 (三)几何矩的计算 (四)获取图像的外接矩形boundingRect ...
- [luogu4484]最长上升子序列
标算是状压dp+打表,前者时间复杂度为$o(n^{2}2^{n})$,并通过打表做到$o(1)$ 参考loj2265中关于杨表的相关知识,不难发现答案即$\frac{\sum_{a\vdash n}a ...
- CF 786 E ALT
CF 786 E ALT 一个居民有两个选择:分配一只宠物,路上都有宠物 一个守卫有两种选择:分配一只宠物,不分配宠物 我们找一个原点,到每个居民都有一条边,表示是否给他宠物 从每个居民向他路上的守卫 ...
- canvas 基本介绍
# canvas 基本功能介绍 - canvas 能做什么 1. 绘制简单图形线条 2. 裁剪图片 - 开始绘制画布 新建html文档添加 canvas标签 ```html <div style ...
- VS调用别人的COM组件的问题
调用第三方的COM组件,记得要先在管理员cmd执行:regsvr32 xxxx.dll 没执行之前运行 HRESULT hr = pComm.CreateInstance("xxxx.Com ...
- R包MetaboAnalystR安装指南(Linux环境非root)
前言 这是代谢组学数据分析的一个R包,包括用于代谢组学数据分析.可视化和功能注释等众多功能.最近有同事在集群中搭建蛋白和代谢流程,安装这个包出现了问题,于是我折腾了一上午. 这个包的介绍在:https ...
- 数据分析体系 — 用户粘性的两个计算指标(DAU/MAU和月人均活跃天数)
很多运营都了解DAU(日活跃用户数)和MAU(月活跃用户数)的重要性,但在某些情况下这两个数值本身并不能反映出太多问题,这个时候就要引用到[DAU/MAU]的概念,即[日活/月活] 用户粘性的两个计算 ...