DataPipeline在大数据平台的数据流实践
文 | 吕鹏 DataPipeline架构师

进入大数据时代,实时作业有着越来越重要的地位。本文将从以下几个部分进行讲解DataPipeline在大数据平台的实时数据流实践。
一、企业级数据面临的主要问题和挑战
1.数据量不断攀升
随着互联网+的蓬勃发展和用户规模的急剧扩张,企业数据量也在飞速增长,数据的量以GB为单位,逐渐的开始以TB/GB/PB/EB,甚至ZB/YB等。同时大数据也在不断深入到金融、零售、制造等行业,发挥着越来越大的作用。
2. 数据质量的要求不断地提升
当前比较流行的AI、数据建模,对数据质量要求高。尤其在金融领域,对于数据质量的要求是非常高的。
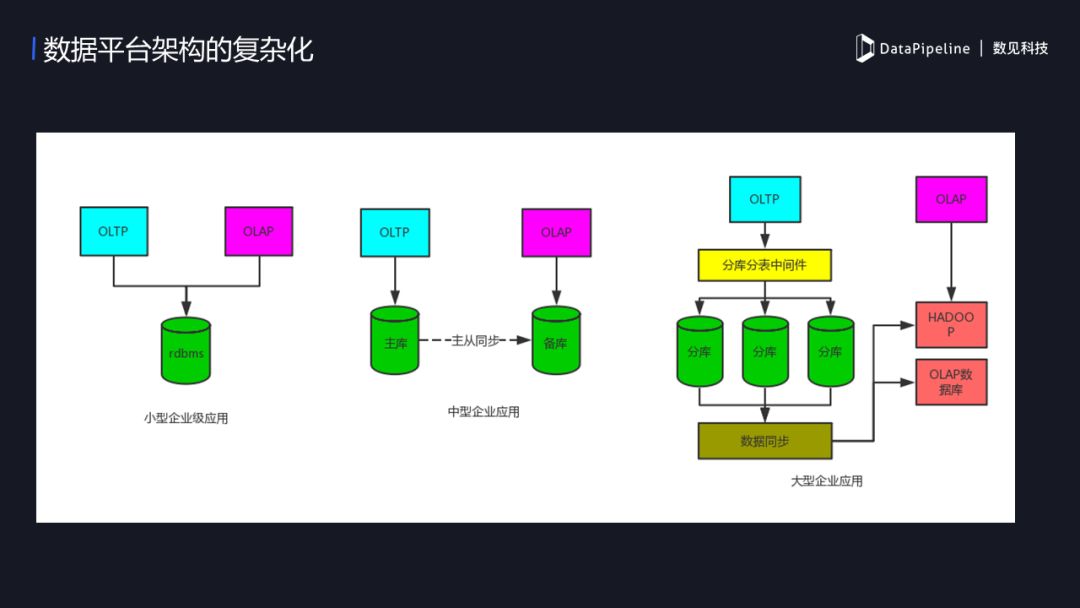
3. 数据平台架构的复杂化
企业级应用架构的变化随着企业规模而变。规模小的企业,用户少、数据量也小,可能只需一个MySQL就搞能搞;中型企业,随着业务量的上升,这时候可能需要让主库做OLTP,备库做OLAP;当企业进入规模化,数据量非常大,原有的OLTP可能已经不能满足了,这时候我们会做一些策略,来保证OLTP和OLAP隔离,业务系统和BI系统分开互不影响,但做了隔离后同时带来了一个新的困难,数据流的实时同步的需求,这时企业就需要一个可扩展、可靠的流式传输工具。
二、大数据平台上的实践案例
下图是一个典型的BI平台设计场景,以MySQL为例,DataPipeline是如何实现MySQL的SourceConnector。MySQL作为Source端时:
- 全量+ 增量;
- 全量:通过select 方式,将数据加载到kafka中;
- 增量:实时读取 binlog的方式;
使用binlog时需要注意开启row 模式并且image设置为 full。
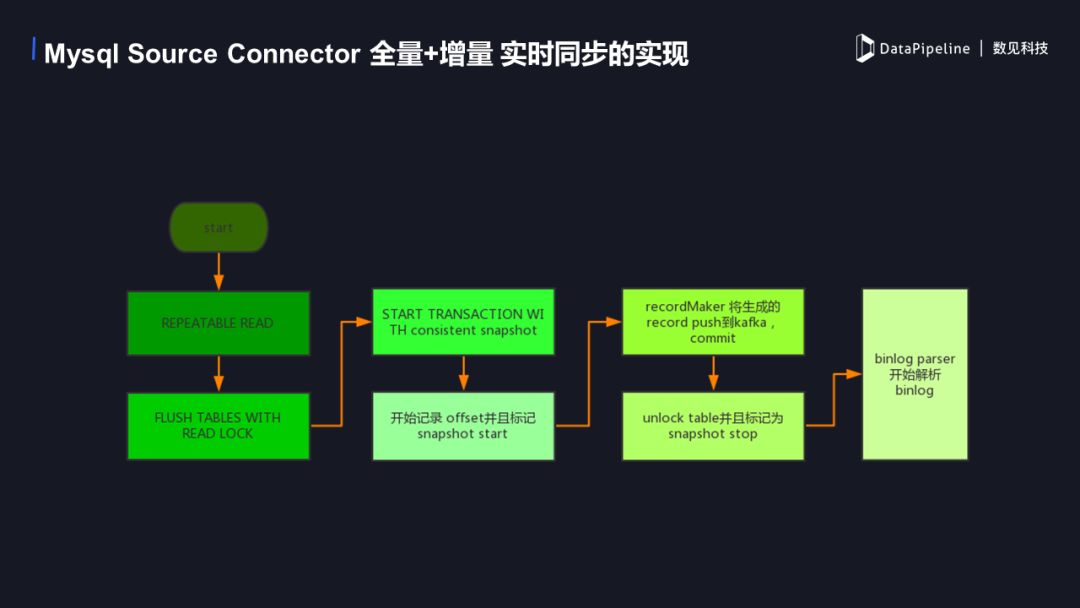
1. MySQL SourceConnector 全量+增量实时同步的实现
下面是具体的实现流程图,首先开启repeatable read事务,保证在执行读锁之前的数据可以确实的读到。然后进行flush table with read lock 操作,添加一个读锁,防止这个时候有新的数据进入影响数据的读取,这时开始一个truncation with snapshot,我们可以记录当前binlog的offset 并标记一个snapshot start,这时的offset 为增量读取时开始的offset。当事务开始后可以进行全量数据的读取。record marker这时会将生成record 写到 kafka 中,然后commit 这个事务。当全量数据push完毕后我们解除读锁并且标记snapshot stop,此时全量数据已经都进入kafka了,之后从之前记录的offset开始增量数据的同步。
2. DataPipeline做了哪些优化工作
1)以往在数据同步环节都分为全量同步和增量同步,全量同步为一个批处理。在批处理时我们都是进行all or nothing的处理,但当大数据情况下一个批量会占用相当长的时间,时间越长可靠性就越难保障,所以往往会出现断掉的情况,这时一个重新处理会让很多人崩溃。DataPipeline 解决了这一痛点,通过管理数据传输时的position 来做到断点续传,这时当一个大规模的数据任务即使发生了意外,也可以重断掉的点来继续之前的任务,大大缩短了同步的时间,提高了同步的效率。
2)在同步多个任务的时候,很难平衡数据传输对源端的压力和目的端的实时性,在大数据量下的传输尤其能够体现,这时DataPipeline 在此做了大量相关测试来优化不同的连接池,开放数据传输效率的自定义化,供客户针对自己的业务系统定制合适的传输任务,对于不同种类的数据库的传输进行优化和调整,保证数据传输的高效性。
3)自定义异构数据类型的转化,往往开源类大数据传输工具如 sqoop 等,对异构数据类型的支持不够灵活,种类也不够齐全。像金融领域中对数据精度要求较高的场景,在传统数据库向大数据平台传输时造成的精度丢失是很大的一个问题。DataPipeline 对此做了更多数据类型的支持,比如hive 支持的复杂类型以及 decimal 和 timestamp 等。
3. Sink端之Hive
1)Hive的特性
- Hive 内部表和外部表;
- 依赖HDFS;
- 支持事务和非事务;
- 多种压缩格式;
- 分区分桶。
2)Hive同步的问题
- 如何保证实时的写入?
- schema change了怎么办?
- 怎么扩展我想保存的格式?
- 怎么实现多种分区方式?
- 同步中断了怎么办?
- 如何保证我的数据不丢?
3)KafkaConnect HDFS 的 Hive 同步实践
- 使用外表:Hive外部表,能够提高写入效率,直接写HDFS,减少IO消耗,而内表会比外表多一次IO;
- Schema change:目前的做法是目的端根据源端的变化而变化,当有增加列删除列的情况,目标端会跟随源端改动;
- 目前支持的存储格式:parquet,avro ,csv;
- 插件化的partitioner,提供多种分区方式,如 Wallclock RecordRecordField:wallclock是使用写入到hive端时的系统时间,Record 使用是读取时生成record的时间,RecordField是使用用户自定义的时间戳来定义分区,未来会实现可自定义化的partitioner 来满足不同的需求;
- Recover 机制保障中断后不会丢失数据;
- 使用WAL (Write-AheadLogging)机制,保证数据目的端数据一致性。
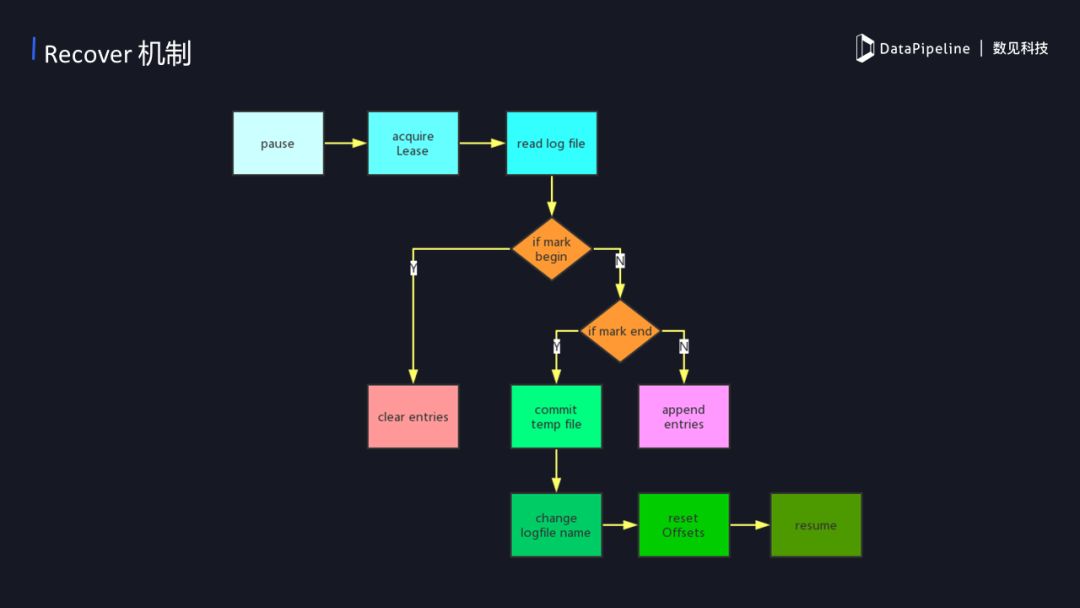
4)Recover的机制
recover 是一种恢复的机制,在数据传输的阶段往往可能出现各种不同的问题,如网络问题等等。当出现问题后我们需要恢复数据同步,那么recover是怎么保证数据正常传输不丢失呢?当recover开始的时候,获取目标文件在hdfs 上的租约,如果这时候需要读写的HDFS当前文件是被占用的,那我们需要等待它直到可以获取到租约。当我们获取到租约后就可以开始读之前写入时候的log,如果第一次会创建一个新的log,并标记一个begin,然后记录了当时的kafka offset。这时候需要清理之前遗留下来的临时数据,清理掉之后再重新开始同步直到同步结束会标记一个end。如果没有结束的话就相当于正在进行中,正在进行中每次都会提交当前同步的offset,来保证出现意外后会回滚到之前offset。
5)WAL (Write-Ahead Logging)机制
Write-Ahead Logging机制其实就是核心思想在数据写入到数据库之前,它先写临时文件,当一个批次结束后,在将这个临时文件改名为正式文件,确保每次提交后的正式文件一致性,如果中途出现写入错误将临时文件删除重新写入,相当于一个回滚。hive 的同步主要利用这种实现方式来保证一致性。首先它同步数据写入到HDFS临时文件上,确保一个批次的数据正常后再重命名到正式文件当中。正式的文件名会包含kafka offset,例如一个avro 文件的文件名为 xxxx+001+0020.avro ,这表示当前文件中有offset 1 到 20 的20条数据。
4. Sink端之GreenPlum
GreenPlum,是一个MPP架构的数据仓库,底层由多个postgres数据库作为计算节点,擅长OLAP,作为BI数据仓库有着良好的性能。
1)DataPipeline对GreenPlum 同步实践以及优化策略
- greenplum 支持多种数据加载方式,目前我们使用copy的加载方式。
- 批量处理提高sink端写入效率,不进行insert 和 update 的操作,一律使用 delete + copy 的方式批量加载;
- 多线程加预加载机制:
➢ 每个需要同步的表单独记录一个offset,当整个任务失败时可以分开进行恢复;
➢ 使用一个线程池管理加载数据的线程,每个同步的表单独一个线程来进行加载数据,多表同时同步;
➢ 在加载数据的时间里,提前对kafka进行消费,缓存处理好的一个数据集,当一个线程加载数据结束后马上开始新的线程加载数据,减少处理加载数据的时间;
- delete + copy的方式可以保证数据最终一致性;
- source 端有主键的表可以通过主键来合并一个批次需要同步的数据,如一个需要同步的批量数据中包含一条 insert 的数据,后面跟着 update 该条数据,那就无需同步两遍,将该数据更新到 update 之后的状态 copy 到 gp 当中即可。
同步GreenPlum需要注意:因为是通过copy 写入文件的,需要文件是结构化数据,典型的是使用CSV,CSV 写入时需注意spiltquote,escapequote,避免出现数据错位的现象。update主键的问题 , 当源端是update一个主键时,同时需要记录update前的主键,并在目标端进行删除。还有 \0 特殊字符的问题,因为核心是用C语言,所以在同步的时候\0需要特殊处理掉。
三、DataPipeline未来的工作
1. 目前我们碰到kafka connect rebalance的一些问题,所以我们对其进行了改造。以往的rebalance机制是假如我们增加或者删除一个task,会导致整个集群rebalance,这样造成很多无谓的开销而且频繁的rebalance 不利于数据同步的任务的稳定。于是我们将rebalance机制改造成一个黏性的机制:
- 当我们增加一个新的任务的时候,我们会检查所有的worker使用率比较低的,当worker的task比较少,我们只把它加进比较少的worker就可以了,也不需要做全量的平衡,当然这时候可能还是有一些不平衡的资源浪费,这是我们可以容忍的,至少比我们做一次全量的rebalance开销要小;
- 假如删除一个task,以往的机制是删除一个task的时候也会做全量的Rebalance,新的机制不会触发rebalance。这时候如果时间长也会造成一个资源不平衡,这是我们可以自动化rebalance一下所有的集群;
- 假如说集群的某个节点宕掉了,该节点的task怎么办呢?我们不会马上就把这个节点上的 task分配出去,会先等待10分钟,因为有的时候它可能只是短暂的连接超时,过一段时间后就会恢复,如果根据这个来做一次rebalance,可能这是不太值的。当等待10分钟后节点还是没有恢复,我们再做rebalance,将宕掉的节点任务分配到其他节点上;
2. 源端的数据一致性,目前通过WAL的机制可以保证目的端的一致性;
3. 大数据量下的同步优化以及提高同步的稳定性。
四、总结
1. 大数据时代企业数据集成主要面临各种复杂的架构,应对这些复杂的系统对ETL的要求也越来越高。我们能做的就是需要权衡利弊选取一个符合业务需求的框架;
2. Kafka Connect 比较适合对数据量大,且有实时性需求的业务;
3. 基于Kafka Connect 优良特性可以依据不同的数据仓库特性来提高数据时效性和同步效率;
4. DataPipeline针对目前企业在大规模实时数据流的痛点,进行了相关的改造和优化,首先数据端到端一致性的保证是几乎所有企业在数据同步过程中碰到的,目前已经做到基于kafka connect 的框架中 rebalance 中的优化和改造。
—end—
DataPipeline在大数据平台的数据流实践的更多相关文章
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 时间序列大数据平台建设(Time Series Data,简称TSD)
来源:https://blog.csdn.net/bluishglc/article/details/79277455 引言在大数据的生态系统里,时间序列数据(Time Series Data,简称T ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- 携程实时大数据平台演进:1/3 Storm应用已迁到JStorm
携程大数据平台负责人张翼分享携程的实时大数据平台的迭代,按照时间线介绍采用的技术以及踩过的坑.携程最初基于稳定和成熟度选择了Storm+Kafka,解决了数据共享.资源控制.监控告警.依赖管理等问题之 ...
- 如何基于Go搭建一个大数据平台
如何基于Go搭建一个大数据平台 - Go中国 - CSDN博客 https://blog.csdn.net/ra681t58cjxsgckj31/article/details/78333775 01 ...
- Train-Alypay-Cloud:蚂蚁大数据平台培训开课通知(第三次)
ylbtech-Train-Alypay-Cloud:蚂蚁大数据平台培训开课通知(第三次) 1.返回顶部 1. 您好! 很高兴通知您,您已经成功报名将于蚂蚁金服计划在2018年2月28日- 2018年 ...
- 基于Ambari构建自己的大数据平台产品
目前市场上常见的企业级大数据平台型的产品主流的有两个,一个是Cloudera公司推出的CDH,一个是Hortonworks公司推出的一套HDP,其中HDP是以开源的Ambari作为一个管理监控工具,C ...
随机推荐
- PAT1107:Social Clusters
1107. Social Clusters (30) 时间限制 1000 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue When ...
- MySql常用两大存储引擎简介
MyISAM存储引擎简介 MyISAM存储引擎的表在数据库中,每一个表都被存放为三个以表名命名的物理文件. 首先肯定会有任何存储引擎都不可缺少的存放表结构定义信息的.frm文件,另外还有.MYD和.M ...
- sql server 分区(上)
分区发展历程 基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能.追溯到逻辑分区表和手动分区表的功能. 二.为什么要进行分区 为了改善大型表以及具有各种访问模式的表的可伸缩 ...
- Windows上使用Git托管代码到Coding
作者:荒原之梦 Git简介: Git是一款分布式版本控制系统,可用于项目的版本管理.Git可以管理本地代码仓库与远程代码仓库间的连接以及进行版本控制,使得我们可以在本地离线进行修改等操作,之后再将代码 ...
- bug排查小结
mysql cpu利用率偏高,并且长时间居高不下. show processlist 发现有一个单表查询的sql语句出现的频率比较高, 这个单表查询中规中矩,where语句中条件都使用”=“连接,再加 ...
- How to untar a TAR file using Apache Commons
import org.apache.commons.compress.archivers.tar.TarArchiveEntry; import org.apache.commons.compress ...
- 如果裸写一个goroutine pool
引言 在上文中,我说到golang的原生http server处理client的connection的时候,每个connection起一个goroutine,这是一个相当粗暴的方法.为了感受更深一点, ...
- 【线段树】Bzoj1230 [Usaco2008 Nov]lites 开关灯
Description Farmer John尝试通过和奶牛们玩益智玩具来保持他的奶牛们思维敏捷. 其中一个大型玩具是牛栏中的灯. N (2 <= N <= 100,000) 头奶牛中的每 ...
- BZOJ_2152_聪聪可可_点分治
BZOJ_2152_聪聪可可_点分治 Description 聪聪和可可是兄弟俩,他们俩经常为了一些琐事打起来,例如家中只剩下最后一根冰棍而两人都想吃.两个人都想玩儿电脑(可是他们家只有一台电脑)…… ...
- 【爆料】-《澳大利亚联邦大学毕业证书》FedUni一模一样原件
☞澳大利亚联邦大学毕业证书[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士& ...