Sparklyr与Docker的推荐系统实战
链接:https://zhuanlan.zhihu.com/p/21574497
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
相关内容:
sparklyr包:实现Spark与R的接口,会用dplyr就能玩Spark
概述
大数据时代,做数据分析的人才辈出,Java、Scala、Go、Julia、Python、JavaScript都不断涌现出很多数据分析的新工具,然而对于数据分析来说,这些工具都不是分析的核心,分析的核心在于对市场业务、对具体数据的理解。相信你也见过太多脱离具体应用场景和业务数据而空谈算法的『数据分析大师』了。算法的文章在教科书、论文、已经各种文章里面都是大把大把的,然而大道至简,真正能将算法转化为生产力解决实际问题才是关键。
作为统计学出身的人,真心无力折腾Java的设计模式、JS的异步回调,我们更倾向于把精力放在数据、模型、分析、拟合、预测、检验、报告等等。在SparkR之后,RStudio公司又推出了全新力作Sparklyr,全面继承dplyr的操作规范。通过Sparklyr和Docker的完美结合,Spark的大数据计算引擎门槛进一步降低!不仅仅简化了分布式计算的操作,还简化了安装部署的环节,我们只几乎不需要做什么改动就可以直接运用R中的dplyr进行分布式的计算,几乎不需要学习此前Scala风格的API。
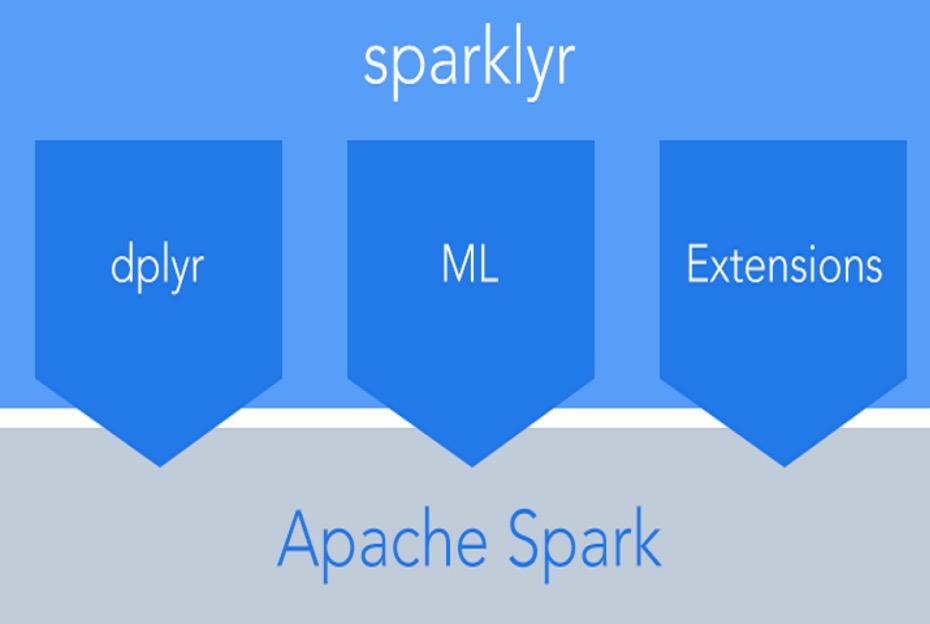
什么是Sparklyr
Sparklyr顾名思义就是 Spark + dplyr。首先,它实现了将dplyr的data frame所有操作规范对Spark计算引擎的完整封装。其次,它是的R可以透过Spark的MLib机器学习库拓展分布式机器学习算法的能力。最后,对于其他Spark功能,我们还可以通过`sparkapi`来调用所有Spark库中的Scala接口。
目前,最新版本的RStudio 已经集成了Spark引擎,本文将带你快速进入大数据分析领域。

什么是Docker
Docker是类似于虚拟机的一种虚拟化软件,让我们可以在不同操作系统上运行相同的软件。它主要解决了虚拟机安装软件速度比较慢的问题,相对于虚拟机,Docker的启动速度是秒级的。本文将通过一个详细的例子,指导各位R语言的爱好者快速安装带有Spark功能的RStudio软件,快速开启您的大数据之旅。
软件安装
鉴于大量数据分析用户还是以Windows操作系统为主,或许还深度绑定了Excel这样的数据分析神器,本文将放弃以Unix视角,采用Windows视角为各位看官介绍软件安装过程。
步骤一:安装Windows版本Docker
你可以进入http://www.docker.com的官网首页,看到软件下载链接,这里需要您的操作系统在Windows
10及其以上版本。如果不想进入官网,也可以点击这个链接:https://download.docker.com/win/beta/InstallDocker.msi
下载之后根据系统提示默认安装即可,不得不说,Docker是一个神奇的软件。
步骤二:启动Docker软件
点击软件图标即可启动Docker软件(最新版本号和此图有可能并不一致)。接着,您可以选择打开系统自带Powershell软件,向Powershell中复制粘贴如下命令:
docker run -d -p 8787:8787 --name financer index.tenxcloud.com/7harryprince/sparkr-rstudio
这时候只需要耐心等待您的大数据分析系统安装完成。(软件大概会占用4G左右的空间,我已经为你预先为你一站式安装了最新的 Shiny, R markdown,R notebook,jdk8,gcc5.3,R 3.3 以及其他数据分析常用的R包)
步骤三:访问RStuido软件
一旦软件完成安装,你可以在Chrome或者Edge中输入下面的地址访问到RStudio软件:
localhost:8787
最后,输入默认账号`harryzhu`,密码`harryzhu`即可进入RStudio软件。
推荐系统实战
library(sparklyr)
library(dplyr)
Sys.setenv(SPARK_HOME="/opt/spark-1.6.0-bin-hadoop2.6")
Sys.getenv("SPARK_HOME")
sc = spark_connect("local")
mtcars_tbl <- copy_to(sc, mtcars,overwrite = TRUE)
未完
求各位看官给点反馈~~~
参考资料
- RStudio又搞出了个大杀器!sparklyr包:实现Spark与R的接口,会用dplyr就能玩Spark
- Using Spark with Shiny and R Markdown Slide
- https://channel9.msdn.com/Events/useR-international-R-User-conference/useR2016/Using-Spark-with-Shiny-and-R-Markdown
Video - https://blogs.msdn.microsoft.com/azuredatalake/2016/08/09/rapid-big-data-prototyping-with-microsoft-r-server-on-apache-spark-context-switching-spark-tuning/
- https://databricks.com/blog/2016/07/07/sparkr-tutorial-at-user-2016.html?twitter=@bigdata
- http://conferences.oreilly.com/strata/hadoop-big-data-ny/public/schedule/detail/52369?twitter=@bigdata
- Top 5 Mistakes When Writing Spark Applications
Sparklyr与Docker的推荐系统实战的更多相关文章
- 云计算Docker全面项目实战(Maven+Jenkins、日志管理ELK、WordPress博客镜像)
2013年,云计算领域从此多了一个名词“Docker”.以轻量著称,更好的去解决应用打包和部署.之前我们一直在构建Iaas,但通过Iaas去实现统一功 能还是相当复杂得,并且维护复杂.将特殊性封装到 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- Docker系列之实战:3.安装MariaDB
环境 [root@centos181001 ~]# cat /etc/centos-release CentOS Linux release 7.6.1810 (Core) [root@centos1 ...
- Docker小白到实战之容器数据卷,整理的明明白白
前言 上一篇把常用命令演示了一遍,其中也提到容器的隔离性,默认情况下,容器内应用产生的数据都是由容器本身独有,如果容器被删除,对应的数据文件就会跟着消失.从隔离性的角度来看,数据就应该和容器共存亡:但 ...
- Docker小白到实战之Dockerfile解析及实战演示,果然顺手
前言 使用第三方镜像肯定不是学习Docker的最终目的,最想要的还是自己构建镜像:将自己的程序.文件.环境等构建成自己想要的应用镜像,方便后续部署.启动和维护:而Dockerfile就是专门做这个事的 ...
- Docker小白到实战之Docker网络简单了解一下
前言 现在对于Docker容器的隔离性都有所了解了,但对容器IP地址的分配.容器间的访问等还是有点小疑问,如果容器的IP由于新启动导致变动,那又怎么才能保证原有业务不会被影响,这就和网络有挂钩了,接下 ...
- Docker基础与实战,看这一篇就够了
docker 基础 什么是Docker Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 AUFS 类的 Uni ...
- 《Docker基础与实战,看这一篇就够了》
什么是Docker? Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 AUFS 类的 Union FS 等技术 ...
- Docker单机网络实战
前言 Docker系列文章: 此篇是Docker系列的第八篇,大家一定要按照我做的Demo都手敲一遍,印象会更加深刻的,加油! 为什么要学习Docker Docker基本概念 Docker镜像基本原理 ...
随机推荐
- angular4在prod模式下的JIT编译问题
最近利用angular4开发一个项目,由于画面中的显示都是从数据表中读取,通过设置显示FLAG和显示顺序对画面布局按既定规则控制的, 所以必须利用动态编译实现. 方法如下, 1,获取JitCompil ...
- VUE脚手架搭建
1.什么vue-cli vue-cli是vue.js的脚手架,用于自动生成vue.js工程模板的. 步骤: 2.安装 ->全局安装 npm install vue-cli -g 或 ...
- 文字滚动效果,jquery和marquee标签
链接:https://pan.baidu.com/s/1pMwHYH1 密码:r9ys marquee标签是微软创建的,后来大部分浏览器都适用后,微软在IE8把这个标签去掉了.为符合W3C规范,还是使 ...
- 通过url获取相应的location信息
var properties = ['href', 'origin', 'host', 'hostname', 'port', 'pathname', 'search', 'hash']; var g ...
- JS对象、原型链
忘记在哪里看到过,有人说鉴别一个人是否 js 入门的标准就是看他有没有理解 js 原型,所以第一篇总结就从这里出发. 对象 JavaScript 是一种基于对象的编程语言,但它与一般面向对象的编程语言 ...
- python中math模块常用的方法整理
ceil:取大于等于x的最小的整数值,如果x是一个整数,则返回x copysign:把y的正负号加到x前面,可以使用0 cos:求x的余弦,x必须是弧度 degrees:把x从弧度转换成角度 e:表示 ...
- 小甲鱼OD学习第2讲
这次我们的任务是让我们输入任意用户名密码判断正确 我们输入fishc和111111,显示错误 我们猜测这是用GetDlgItemTextW来收集账号密码的输入值 我们找到了两个函数,给这两个函数都下断 ...
- 【JavaWeb】JDBC连接MySQL数据库
正文之前 在之前写的JavaWeb项目中使用了JDBC,在此来回顾一下,并做个demo看看,先来看看JDBC的概念 Java数据库连接,(Java Database Connectivity,简称JD ...
- python爬虫(5)——正则表达式(二)
前一篇文章,我们使用re模块来匹配了一个长的字符串其中的部分内容.下面我们接着来作匹配"1305101765@qq.com advantage 314159265358 1892673 ...
- php+redis 学习 一 连接
<?php header('content-type:text/html;chaeset=utf-8'); $redis = new Redis(); $redis->connect('1 ...