DBoW2算法原理介绍
本篇介绍DBoW2算法原理介绍,下篇介绍DBoW2的应用。
DBow2算法
DBow2是一种高效的回环检测算法,DBOW2算法的全称为Bags of binary words for fast place recognition in image sequence,使用的特征检测算法为Fast,描述子使用的是brief描述子,(TODO:和DBow的区别在哪里?)是一种离线的方法。
二进制特征(ORB特征):Fast特征点+Brief描述子
(Hamming distance) 256bits的二进制描述符
Brief描述子:\(b=[b_1, b_2, \cdots, b_{256}]\)总共256bits,每一个bit都是0,1的数
Surf描述子:64位的浮点数,\(d=[d_1, d_2, \cdots, d_{64}]\)
基本的数学知识
Brief使用的距离描述算子为Hamming距离,定义如下:
\]
对于二进制字符串可以通过简单的按位异或实现\(d(v_1,v_2) = v_1 \oplus v_2\)。
算法流程
Bag of Words字典建立方法(最终得到的就是每一层的不同类的median,每一个叶节点对应的就是一个词汇):
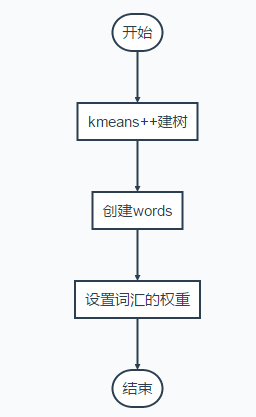
建树流程
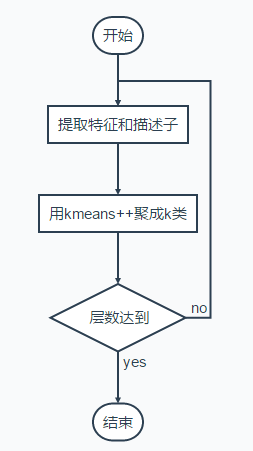
kmeans++方法
输入:(a)聚类数目;(2)初始化中心点(这里使用kmeans++的方法)
算法流程:
迭代:
(1)每个点分类到最近的中心点;
(2)用每一类点的中心点更新中心点。
中心点初始化方法:
-(1)从输入的点集合中随机选择一个点作为第一个聚类中心;
-(2)对于数据集中的每一个点,计算它与已选择的最近的聚类中心的距离D(x);
-(3)选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选为聚类中心的概率较大;
-(4)重复2和3的步骤直到k个聚类中心被选出来;
D(x)到概率上的反应:
- 先从数据库随机挑个随机点当“种子点”
- 对于每个点,计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
- 然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
k-median方法在聚类方法的第二步使用每一个类的中值作为新的中心;
创建words:把建树中所有的节点遍历一遍,找出叶节点。
DBoW2创建节点代码:
\\把所有的节点遍历一遍
for(++nit; nit != m_nodes.end(); ++nit)
{
\\只有节点是字符
if(nit->isLeaf())
{
nit->word_id = m_words.size();
m_words.push_back( &(*nit) );
}
}
权重设置
权重设置用的是idf,意思是词汇在训练过程中出现的频率越高,区分度越低,因此权重越低。
\]
每一个节点包括(只列出了部分信息)
struct Node
{
//在所有节点中的标号
NodeId id;
//该节点的权重,该权重为
//训练的过程中设置的,在得到了树之后,将所有的描述子
//过一遍树,得到每个单词出现的次数,除以总的描述子数目
WordValue weight;
//描述符,为每一类的均值(对于brief描述子,则要对均值进行二值化)
TDescriptor descriptor;
//如果是叶节点,则有词汇的id
WordId word_id;
}
[说明]:上面的方法是分层聚类的,每一次聚类得到的多个节点,都有median \(v\)表
示该类,可以用来判断新的词汇是否属于该类。最终建立的树包括W个叶节点,也就是W个视觉词汇,词汇也用median表示。
DBoW2算法原理介绍的更多相关文章
- CYQ.Data V5 分布式缓存Redis应用开发及实现算法原理介绍
前言: 自从CYQ.Data框架出了数据库读写分离.分布式缓存MemCache.自动缓存等大功能之后,就进入了频繁的细节打磨优化阶段. 从以下的更新列表就可以看出来了,3个月更新了100条次功能: 3 ...
- PageRank算法原理及实现
PageRank算法原理介绍 PageRank算法是google的网页排序算法,在<The Top Ten Algorithms in Data Mining>一书中第6章有介绍.大致原理 ...
- k-近邻算法原理入门-机器学习
//2019.08.01下午机器学习算法1——k近邻算法1.k近邻算法是学习机器学习算法最为经典和简单的算法,它是机器学习算法入门最好的算法之一,可以非常好并且快速地理解机器学习的算法的框架与应用.2 ...
- 红黑树之 原理和算法详细介绍(阿里面试-treemap使用了红黑树) 红黑树的时间复杂度是O(lgn) 高度<=2log(n+1)1、X节点左旋-将X右边的子节点变成 父节点 2、X节点右旋-将X左边的子节点变成父节点
红黑树插入删除 具体参考:红黑树原理以及插入.删除算法 附图例说明 (阿里的高德一直追着问) 或者插入的情况参考:红黑树原理以及插入.删除算法 附图例说明 红黑树与AVL树 红黑树 的时间复杂度 ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- OpenGL学习进程(13)第十课:基本图形的底层实现及算法原理
本节介绍OpenGL中绘制直线.圆.椭圆,多边形的算法原理. (1)绘制任意方向(任意斜率)的直线: 1)中点画线法: 中点画线法的算法原理不做介绍,但这里用到最基本的画0<=k ...
- MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
随机推荐
- hdu 5274 Dylans loves tree(LCA + 线段树)
Dylans loves tree Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Othe ...
- 2015 多校联赛 ——HDU5344(水)
Problem Description MZL loves xor very much.Now he gets an array A.The length of A is n.He wants to ...
- 【AHOI2005】病毒检测
题目描述 科学家们在Samuel星球上的探险仍在继续.非常幸运的,在Samuel星球的南极附近,探险机器人发现了一个巨大的冰湖!机器人在这个冰湖中搜集到了许多RNA片段运回了实验基地. 科学家们经过几 ...
- POJ 3045 Cow Acrobats
Description Farmer John's N (1 <= N <= 50,000) cows (numbered 1..N) are planning to run away a ...
- poj 2104 主席树(区间第k大)
K-th Number Time Limit: 20000MS Memory Limit: 65536K Total Submissions: 44940 Accepted: 14946 Ca ...
- poj2947 高斯消元
Widget Factory Time Limit: 7000MS Memory Limit: 65536K Total Submissions: 5218 Accepted: 1802 De ...
- 习题10-1 UVA 11040(无聊水一水)
题意: 给你一个残缺的塔,每个数字由他下面左右两个数相加得.给你其中一部分,要求输出全部的数字. #include <iostream> #include <cstdio> # ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- rsync 系统用户/虚拟用户 备份web服务器数据及无交互定时推送备份
一.服务环境 (1),WEBserver(192.168.10.130) : BACKserver(192.168.10.129) (2),BACKserver服务器部署,安装所需软件,并启动 (3) ...
- Linux学习之CentOS(十七)-----释放 Linux 系统预留的硬盘空间 与Linux磁盘空间被未知资源耗尽 (转)
释放 Linux 系统预留的硬盘空间 大多数文件系统都会保留一部分空间留作紧急情况时用(比如硬盘空间满了),这样能保证有些关键应用(比如数据库)在硬盘满的时候有点余地,不致于马上就 crash,给监 ...