kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一、前言
kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别。mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整个数据集的大小为(42000,784),加上标签值的一列。
二、模型选择
通过简单的数据观察,发现这些数据都是初始的像素数据,还没经过标准化。所以对其做标准化处理后,我们就可以进入到模型选择的步骤了。
整个数据集dataset的数据量不算小,shape为(42000,784),为了节省时间,我们可以利用全部的x值,以及哑变量后的y为零的数据(单一分类器,关于数字零的OneVsRest分类),初步尝试跑一下各种分类模型。结果如下:
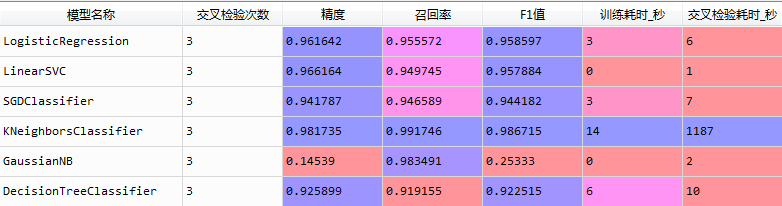
由于k邻近利用空间分割的原理,使得它在这个分类问题上的效果最好,但由于其运算的原理,数据量稍微偏大,它的效率就会变得很低(结尾附上K邻近的OneVsRest模型)。其他的模型表现得还算可以。
不过这个只是一个单一的分类结果,我们的目的是要对十个类别进行多分类输出,考虑到效率和精确度,使用TensorFlow会更好更快,下面采用TensorFlow去搭建一个神经网络进行分类。
三、TensorFlow构建神经网络
import pandas as pd
import numpy as np
import tensorflow as tf root = r'path\train.csv'
df_train = pd.read_csv(root) y = df_train.iloc[:,0]
y_train = pd.get_dummies(y)#独热化
x_train = df_train.iloc[:,1:] #数据处理
#数据标准化以及数据类型转化,训练集和测试集的分割
def train_val_split(x_data,y_data):
n=x_data.shape[0]
print(n)
x_train=x_data.iloc[:n-200,].div(255.0)#进行0-1标准化,训练集
y_train=y_data.values[:n-200,].astype(np.float32)#需要保证数据类型一致性,训练集
x_val=x_data.iloc[n-200:,].div(255.0)#进行0-1标准化,测试集
y_val=y_data.values[n-200:,].astype(np.float32)#需要保证数据类型一致性,测试集
return x_train,y_train,x_val,y_val x_train,y_train,x_val,y_val=train_val_split(x_train,y_train) #建模
def add_layer(x, in_size, out_size, activation_function=None,):
w = tf.Variable(tf.zeros([in_size, out_size]),name='w')
b = tf.Variable(tf.zeros([1, out_size]),name='b')
y = tf.matmul(x,w)+b
if activation_function is None:
outputs = y
else:
outputs = activation_function(y)
return outputs #性能函数
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result #xy值的占位符
xs = tf.placeholder("float",[None,784]) # 28x28
ys = tf.placeholder("float",[None,10]) #建立一层神经网络
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax) #交叉熵成本函数
cross_entropy = -tf.reduce_sum(ys * tf.log(prediction)) # loss
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)#这个步长影响很大,内存和cpe资源足够的话,尽量调小一点步长 #执行部分
sess = tf.Session()
#tensorflow >= 0.12 的版本的,用global_variables_initializer激活变量
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init) #小批量的效果更好更快
for i in range(15):
for k in range(418):
batch_xs = x_train[k*100:(k+1)*100]
batch_ys = y_train[k*100:(k+1)*100]
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
print(compute_accuracy(x_val,y_val))
四、效果

TensorFlow基础神经网络模型的测试集准确率大约92%左右。放到kaggle上面是0.91457,有待提升!下一篇我会利用循环神经网络去提升准确率!

五、K邻近算法模型
k邻近因为其算法的原因,所以在数据量比较大的时候,预测效率会很低。这个模型就跑了我3个多小时。
from sklearn.neighbors import KNeighborsClassifier as KNN
KNN = KNN() #利用网格搜索调出最优参数组合
param_grid = {'n_neighbors':range(1,6),'weights':["uniform","distance"],'algorithm':['auto','kd_tree','ball_tree']}
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(estimator=neigh, param_grid=param_grid, cv=3,n_jobs=-1, verbose=1)
grid_search.fit(x_train, y_train)#这里由于内存有限,只用了数字是否为0的y值 #查看最好的参数选择
print(grid_search.best_params_)#最优组合为(algorithm='auto',n_neighbors=4,weights='uniform') #手写的OneVsRest模型,做预测
from sklearn.neighbors import KNeighborsClassifier as KNN
KNN = KNN(algorithm='auto',n_neighbors=4,weights='uniform') for i in range(10):
KNN.fit(x_train,y_train.iloc[:,i:i+1])
r = KNN.predict(x_test)
result[i] = r
df_result = pd.DataFrame(result)
这样手写的OneVsRest模型,有个问题,预测结果里面可能一条数据有两个以上的结果,譬如认为它是数字‘3’,也认为它是数字‘5’。或者全部为0,认不出它是任何一个数字。
通过对预测结果的检查,发现了有806个是认不出的,所幸没有出现两个以上的情况。
对于这806个空白结果,我利用逻辑回归和SGD,做了个软投币OneVsRest模型,对其进行预测,最后结果还是有297个是空白的。由于这个是计划外的模型,所以我用0补充了结果。
#逻辑回归和SGD的软投币OneVsRest模型
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import SGDClassifier
SGD = SGDClassifier(loss="modified_huber", penalty="l2")
from sklearn import linear_model
lg = linear_model.LogisticRegression()
from sklearn.ensemble import VotingClassifier
VCF = VotingClassifier(estimators=[('SGD', SGD), ('lg', lg)], voting='soft')
ovr = OneVsRestClassifier(VCF)
ovr.fit(x_train,y)
zero_result = ovr.predict(x_zero)
最后这个模型的成绩不错,有0.96多,主要是因为K邻近的原理比较贴合这个案例。

kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)的更多相关文章
- (转)一文学会用 Tensorflow 搭建神经网络
一文学会用 Tensorflow 搭建神经网络 本文转自:http://www.jianshu.com/p/e112012a4b2d 字数2259 阅读3168 评论8 喜欢11 cs224d-Day ...
- 用Tensorflow搭建神经网络的一般步骤
用Tensorflow搭建神经网络的一般步骤如下: ① 导入模块 ② 创建模型变量和占位符 ③ 建立模型 ④ 定义loss函数 ⑤ 定义优化器(optimizer), 使 loss 达到最小 ⑥ 引入 ...
- 一文学会用 Tensorflow 搭建神经网络
http://www.jianshu.com/p/e112012a4b2d 本文是学习这个视频课程系列的笔记,课程链接是 youtube 上的,讲的很好,浅显易懂,入门首选, 而且在github有代码 ...
- kaggle实战记录 =>Digit Recognizer
date:2016-09-13 今天开始注册了kaggle,从digit recognizer开始学习, 由于是第一个案例对于整个流程目前我还不够了解,首先了解大神是怎么运行怎么构思,然后模仿.这样的 ...
- Tensorflow 搭建神经网络及tensorboard可视化
1. session对话控制 matrix1 = tf.constant([[3,3]]) matrix2 = tf.constant([[2],[2]]) product = tf.matmul(m ...
- Kaggle入门(一)——Digit Recognizer
目录 0 前言 1 简介 2 数据准备 2.1 导入数据 2.2 检查空值 2.3 正则化 Normalization 2.4 更改数据维度 Reshape 2.5 标签编码 2.6 分割交叉验证集 ...
- Kaggle 项目之 Digit Recognizer
train.csv 和 test.csv 包含 1~9 的手写数字的灰度图片.每幅图片都是 28 个像素的高度和宽度,共 28*28=784 个像素点,每个像素值都在 0~255 之间. train. ...
- Tensorflow搭建神经网络及使用Tensorboard进行可视化
创建神经网络模型 1.构建神经网络结构,并进行模型训练 import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt ...
- tensorflow搭建神经网络基本流程
定义添加神经层的函数 1.训练的数据2.定义节点准备接收数据3.定义神经层:隐藏层和预测层4.定义 loss 表达式5.选择 optimizer 使 loss 达到最小 然后对所有变量进行初始化,通过 ...
随机推荐
- 【Python】 数字求和
# 用户输入数字 num1 = input('输入第一个数字:') num2 = input('输入第二个数字:') # 求和 sum = float(num1) + float(num2) # 显示 ...
- Redis05——Redis五大数据类型 String
String String是Redis最基本的数据类型(较常用),一个key对应一个value string类型是二进制安全的,Redis的string可以包含任何数据 一个Redis中字符串valu ...
- python正则非贪婪模式
上一篇python正则匹配次数大家应该也发现了,除了?其他匹配次数规则都是尽可能多的匹配 那如果只想匹配1次怎么办呢,这就是正则中非贪婪模式的概念了 原理就是利用?与其他匹配次数规则进行组合 单个匹配 ...
- 链剖-进阶ing-填坑-NOIP2013-货车运输
This article is made by Jason-Cow.Welcome to reprint.But please post the writer's address. http://ww ...
- 一篇文章了解JsBridge
链接:https://blog.csdn.net/duwen90/article/details/79389545
- 安装Tengine版本的nginx
安装tengine版nginx #!/bin/bash yum install epel-release -y yum install gcc unzip gcc-c++ git wget bind- ...
- tomcat安装成功以后进行测试步骤:
tomcat安装成功以后进行测试步骤: 编写测试页面: 进入Tomcat安装对应路径: E:\Tomcat\apache-tomcat-8.5.45\webapps\ROOT 创建:test.jsp ...
- 计算机二级-C语言-程序填空题-190107记录
//给定程序的功能是:调用fun函数建立班级通讯录.通讯中记录每位学生的编号,姓名和电话号码.班级的人数和学生的信息从键盘读入,每个人的信息作为一个数据块(代表要使用结构体)写到名为myfile5.d ...
- Wx-小程序-组件式开发之Vant
开始:https://youzan.github.io/vant-weapp/#/intro 小程序开发者工具中 -->工具栏-->构建npm 一.初始化package.json npm ...
- Markdown编辑器软件安装及问题处理
一.Markdown简介 MarkdownPad是Windows下的一个多功能Markdown编辑器 Markdown是一门编辑语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式,可以用来对 ...