最新2.7版本丨DataPipeline数据融合产品最新版本发布

此次发布的2.7版本在进一步优化产品底层数据处理逻辑的同时更加注重提升用户在数据融合任务的日常管理、运行监控及资源分配等管理方面的功能增强与优化,力求帮助大家更为直观、便捷、稳定地管理数据融合任务,提升系统的易用性与稳定性。
一、新增功能
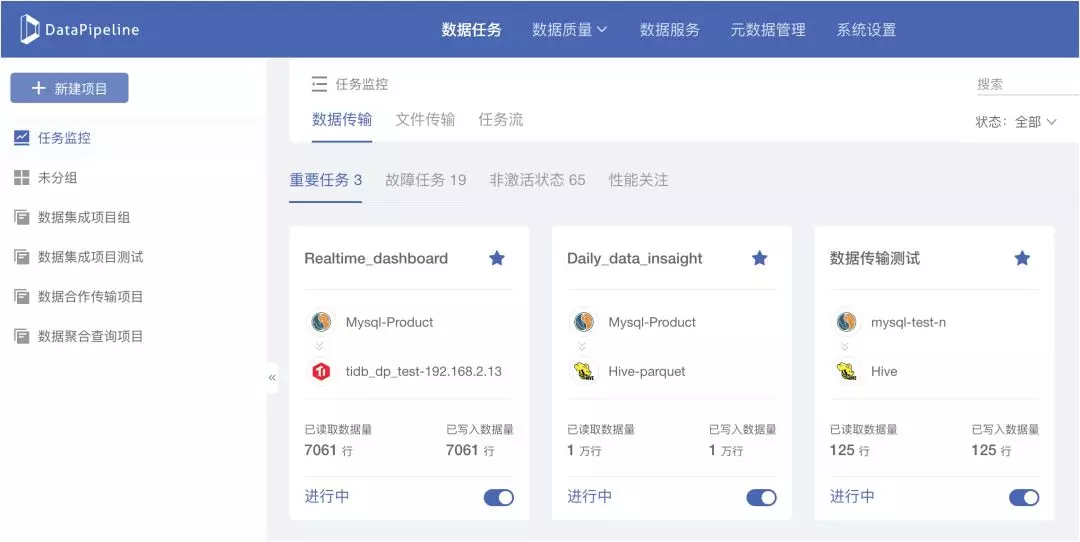
1. 在待处理列表中查看或配置重要任务、故障任务、待完善任务、性能关注任务
功能背景:
对于大多数数据工程师而言,每天需要配置、管理、监控的任务数以百计,任务的重要程度、时效性要求与性能要求也都千差万别,其中既包括为线上产品提供实时计算数据的任务,也有数据备份等优先级较低的任务。同时,为了应对不停变化的市场与业务需求,新的数据融合任务需求也会连续不断地涌现,数据工程师在保证现有任务稳定运行的同时,还需不断地新增数据任务。
大量不同类型、不同状态的任务平铺在客户端首页,导致重要任务难以得到优先关注,待完善任务可能被遗漏,性能较差的任务无法被发现,查找任务、管理任务、处理问题占用了较多工作时间。
新版本上线后,用户可以对重要任务添加标识,平台也会对任务按照重要程度、配置完成情况及运行状态、运行效率进行评估及管理,用户可以通过待处理列表非常直观地看到所关注的重要任务、运行出现问题的故障任务、配置未完成待完善的任务及性能较低需要关注的任务,帮助数据工程师在日常任务监控与新需求处理中提高效率,同时对运行效率有直观的了解,保障业务连续性。
功能详情:
(1)重要任务
工作事务通常带有自身的优先级属性,数据同步任务亦如此。针对重要任务,DataPipeline提供星标设置,于主页优先展示。用户可实时关注重要任务状态,保证重要任务稳定运行。
(2)故障任务
集中展示出现故障的任务,保障问题不被遗漏,任务故障处理全面有序。
(3)非激活状态
集中展示处于非激活状态的任务,明确列示需要进一步完善配置或需要修改配置的任务,保证数据工程师的任务配置工作全面有序。
(4)性能关注
性能关注部分会根据系统对任务效率评估分别展示传输速率较低的10个批量任务和实时任务,通过查看性能关注,可以及时发现运行状态不良的任务,提前做出处理,防止由于性能问题导致更严重的问题发生。
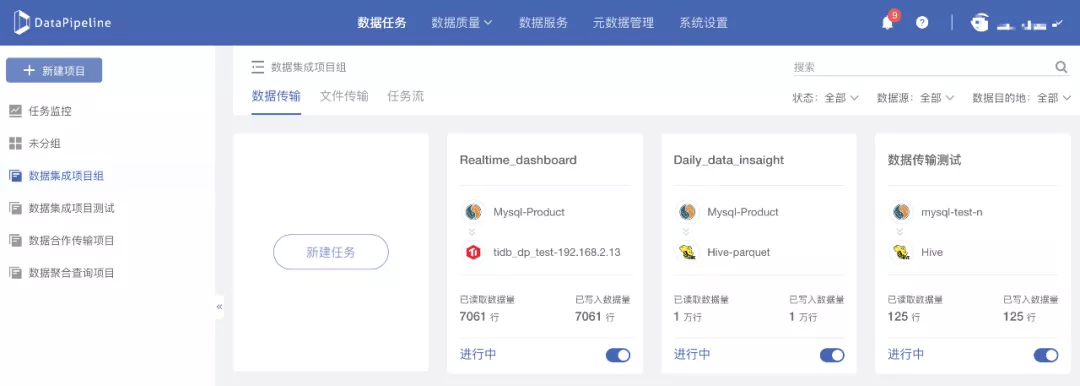
2. 可按照项目对任务进行分组管理
功能背景:
DataPipeline在之前的版本中帮助用户实现了多种来源,不同结构数据的同步处理。但随着产品不断被深度使用,系统用户和数据任务数量的不断增加,多个项目的数据融合任务混杂在一起,导致任务配置、监控及管理有些不便。
我们了解到,一个数据工程师可能同时需要管理多个项目,每个项目可能包含数十个上百个数据融合任务,在不能按照项目对数据融合任务进行分组管理的时候,只能凭借记忆通过名称、数据节点等信息进行搜索,耗时费力。
因此,DataPipeline新增了根据项目进行任务分组的功能,用户可以根据任务所属项目,对上百个任务进行分组管理,大大提高了效率。
功能详情:
(1)支持通过自定义创建项目,对任务进行分组;
(2)支持通过勾选任务,改变多个任务的任务分组。
3. 可以为任务配置特定资源组
功能背景:
虽然DataPipeline数据融合产品基于并行计算框架,从基础架构层面支持任务级高可用,但在资源组管理方面一直未对用户开放,用户在使用之前版本的DataPipeline时,所有数据任务均在一个默认资源组中运行,无法根据任务的重要程度来分配任务运行资源。
这就要求用户只能针对重要任务配置单独的集群以保证任务的稳定、高效运行。这种方式在实际操作过程中存在很多客观限制,如系统资源申请困难,成本预算控制等,也给我们的数据工程师用户们造成了很大的困扰。
因此我们决定在新版本中开放系统资源组配置和分配功能,同时计划在未来的版本中开放动态资源调配功能。
例如,当前系统资源为一台16C64G的服务器,在无法分配资源组时任务运行状态如下:

资源组配置开放以后,用户可以配置一个重要任务资源组和一个一般任务资源组,任务运行状态如下:
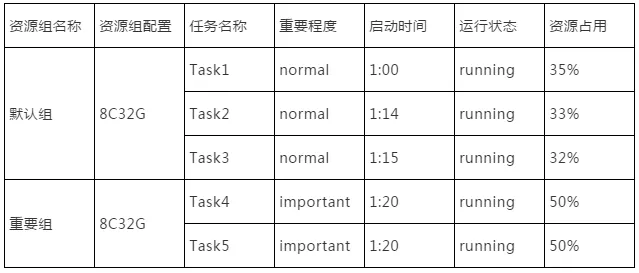
重要任务相较于其他普通任务虽然启动时间较晚。但由于被分配在独立的资源组中,仍然可以保证有足够的资源保障任务平稳运行。
功能详情:
(1)资源组配置
在部署DataPipeline时,通过修改配置文件,可以将数据源端/目的地端的服务器资源划分为多个资源组,实现业务资源组解耦。
资源组配置文件路径:
/data/datapipeline/dpconfig/resource_group_config.json
源端与目的地端均有两个资源组的配置文件,资源组配置文件样例如下:
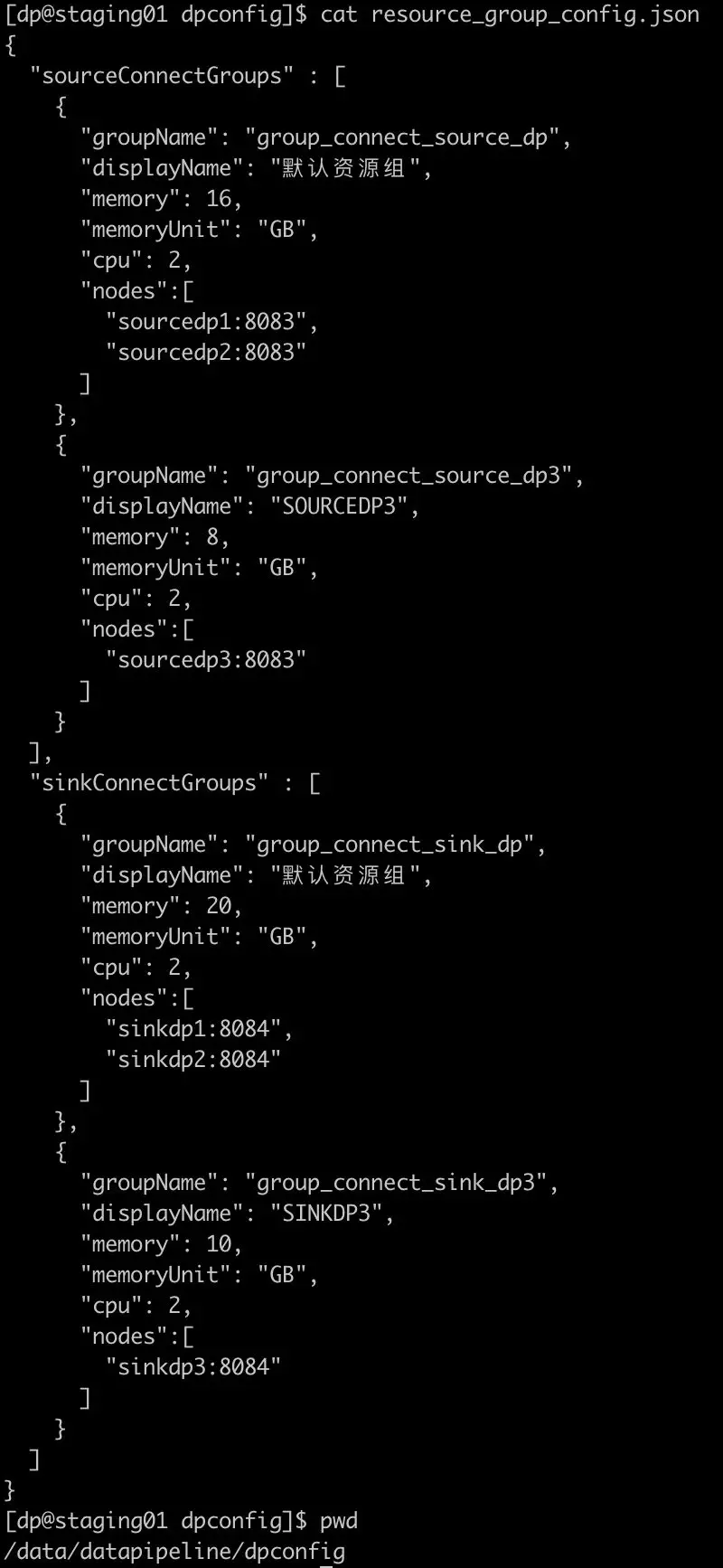
配置详细说明如下:
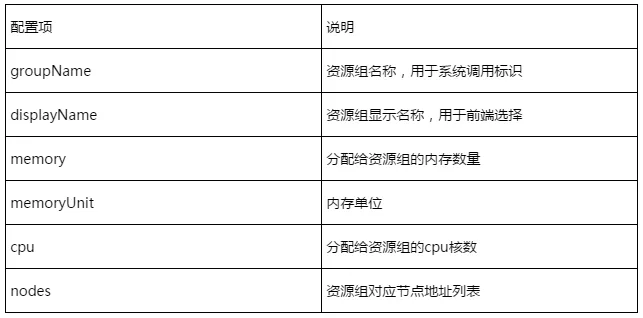
注:修改配置文件后需要重启服务使资源组配置生效
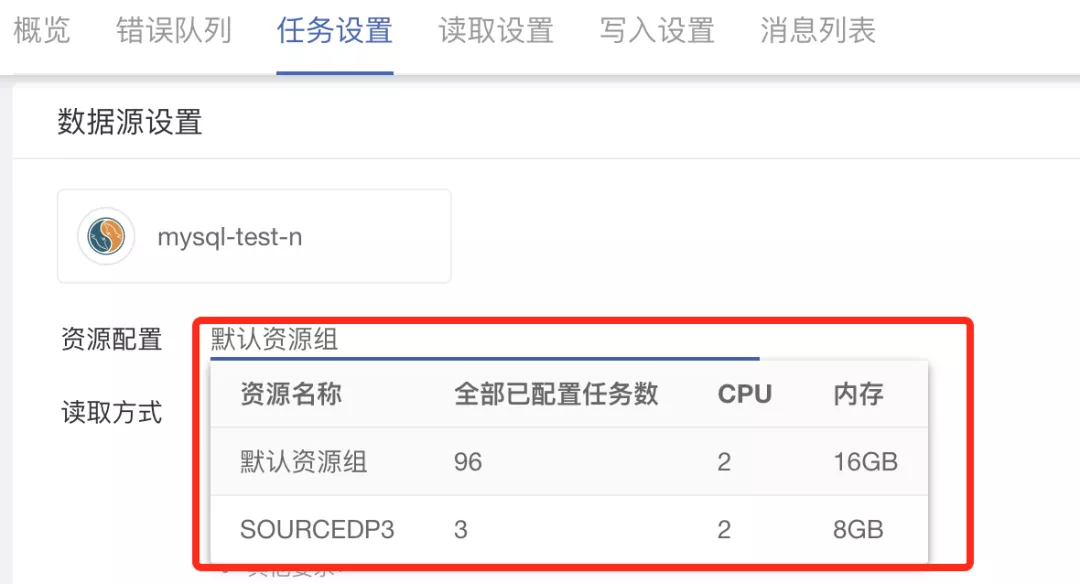
(2)为任务的读取与写入分配资源组
用户在任务设置过程中可以针对每个任务的数据读取和数据写入分别选择支撑任务运行的资源组。
二、优化功能
1. 数据传输消息队列粒度拆分优化
功能背景:
DataPipeline为更好地支持高效数据融合任务,对数据传输消息队列粒度进行了进一步的拆分优化。
功能详情:
首先,我们来看一下数据在DataPipeline是如何流转的:

在此需求的用户场景中,源端数据节点为DB1,DB1中包含三张数据表分别为T1、T2和T3。目的地端数据节点为DB2,DB2中包含三张数据表分别为T4、T5和T6。 数据融合要求为,将T1、T2、T3中的数据进行合并后写入到T4中,将T2中的数据同步到T5中,将T3中的数据同步到T6中。
在之前的处理逻辑中(如图1),按照目的地写入要求的粒度来建立消息队列,即将T1、T2、T3的数据写入1个消息队列进行缓存,也就是图1中的消息队列1。
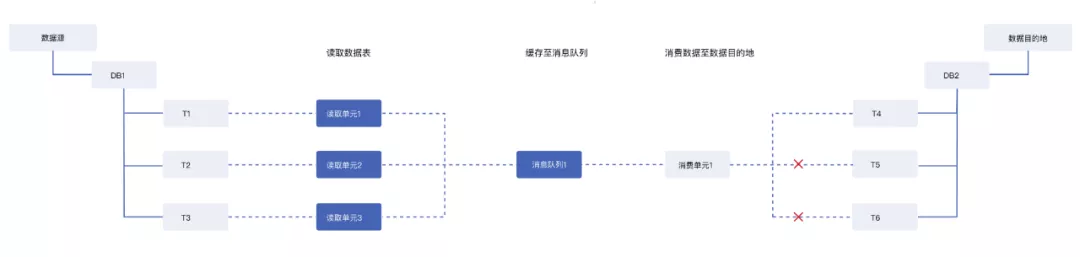
图1
该缓存机制可以很好地支持T4的数据同步,由于数据进入了1个消息队列,所以在同步T5、T6的数据时需要将缓存中的T1、T2、T3数据进行拆分,处理效率较低。
DataPipeline针对数据传输中消息队列缓存粒度进行了拆分优化(如图2),按照数据源数据表的粒度,进行消息队列拆分,即将数据源T1、T2、T3的数据分别写入三个消息队列进行缓存。
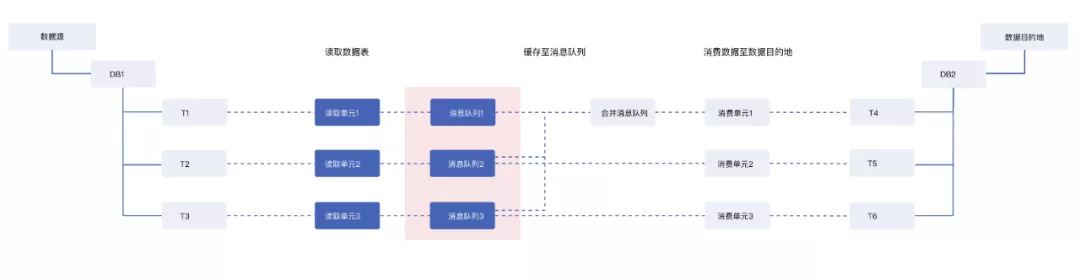
图2
同步至T4的数据会读取T1、T2、T3分别对应的消息队列,进行合并后写入合并消息队列,再供T4对应的消费单元进行消费,同步至T5、T6的任务可以分别读取T2与T3对应的消息队列进行数据写入。
这样,我们便可同时支持源端多表合一同步与其中一张表的单独同步。由于拆分多个并发来读取数据,T2至T5、T3至T6的数据同步速率会明显提升。而对于将T1、T2、T3的数据进行合并同步至T4的流程,虽然添加了一步消息队列内部的合并操作,但速率影响较小,可以较好地支持上述场景。
2. 支持在任一数据同步任务中灵活修改数据源/目的地配置信息
通过支持在任一数据同步任务中灵活修改数据源/目的地配置信息,可使数据节点配置在全局生效,提升任务配置效率。
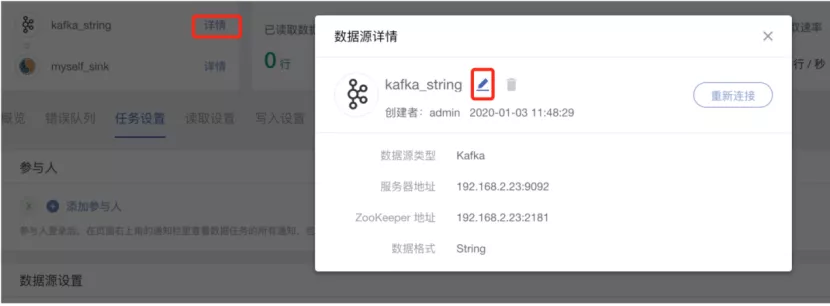
除数据源/目的地类型之外均可修改,当数据源有其他任务正在运行时不允许修改,修改后数据源/目的地节点的配置即全局生效。
三、其他功能增强与问题修复
除上述功能之外,DataPipeline还分别从以下几方面对产品进行了功能增强与问题修复:
1. 支持对用户注册信息中邮箱的修改
2. 为数据任务页面复制、编辑、删除等按钮添加文字注释
3. 优化线程实时任务心跳,支撑运维监控
4. 优化元数据查询SQL和相关逻辑,修复索引查询
5. Hive数据源重构优化
6. Hive Kerberos的验证优化
7. 优化由于JDBC连接造成的任务卡顿问题
DataPipeline的每一次版本迭代都凝聚了团队对企业数据管理需求的深入思考和积极探索,希望在这个特殊时期,新版本能够切实帮助大家更敏捷高效地融合数据、使用数据、分析数据。
最新2.7版本丨DataPipeline数据融合产品最新版本发布的更多相关文章
- DataPipeline数据融合重磅功能丨一对多实时分发、批量读取模式
为能更好地服务用户,DataPipeline最新版本支持: 1. 一个数据源数据同时分发(实时或定时)到多个目的地: 2. 提升Hive的使用场景: 写入Hive目的地时,支持选择任意目标表字段作为 ...
- DataPipeline CTO陈肃:构建批流一体数据融合平台的一致性语义保证
文 | 陈肃 DataPipelineCTO 交流微信 | datapipeline2018 本文完整PPT获取 | 关注公众号后,后台回复“陈肃” 首先,本文将从数据融合角度,谈一下DataPipe ...
- DataPipeline丨新型企业数据融合平台的探索与实践
文 |刘瀚林 DataPipeline后端研发负责人 交流微信 | datapipeline2018 一.关于数据融合和企业数据融合平台 数据融合是把不同来源.格式.特点性质的数据在逻辑上或物理上有机 ...
- Atitit 数据融合merge功能v3新特性.docx
Atitit 数据融合merge功能v3新特性.docx 1.1. 版本历史1 1.2. 生成sql结果1 1.3. 使用范例1 1.4. 核心代码1 1.1. 版本历史 V2增加了replace部分 ...
- 搭建企业级实时数据融合平台难吗?Tapdata + ES + MongoDB 就能搞定
摘要:如何打造一套企业级的实时数据融合平台?Tapdata 已经找到了最佳实践,下文将以 Tapdata 的零售行业客户为例,与您分享:基于 ES 和 MongoDB 来快速构建一套企业级的实时数 ...
- SqlServer高版本数据本分还原到低版本方法
最近遇见一个问题: 想要将Sqlserver高版本备份的数据还原到低版本SqlServer上去,但是这在SqlServer中是没法直接还原数据库的,所以经过一系列的请教总结出来一下可用方法. 首先.你 ...
- 最新选择Godaddy主机方案美国数据中心教程指导
随着Godaddy官方管理层的变动之后,主营重心已经从当初的域名开始转向到域名和主机产品上.这点我们从其发布域名优惠信息的频率也可以看到,而且我们可以看到常年的主机半价优惠,以及针对主机销售年付方案赠 ...
- reshape2 数据操作 数据融合 (melt)
前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致. 下面我们来看下,melt这个函数以及它的特点. melt(da ...
- SLAM+语音机器人DIY系列:(三)感知与大脑——2.带自校准九轴数据融合IMU惯性传感器
摘要 在我的想象中机器人首先应该能自由的走来走去,然后应该能流利的与主人对话.朝着这个理想,我准备设计一个能自由行走,并且可以与人语音对话的机器人.实现的关键是让机器人能通过传感器感知周围环境,并通过 ...
随机推荐
- 洛谷P1147 连续自然数和 题解 枚举
题目链接:https://www.luogu.com.cn/problem/P1147 题目大意: 给你一个数 \(M\) ,求有多少对连续自然数对之和为 \(M\),输出这列连续自然数对的首项和末项 ...
- js滑动导航栏点击后居中效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- [AI开发]零代码分析视频结构化类应用结构设计
视频结构化类应用涉及到的技术栈比较多,而且每种技术入门门槛都较高,比如视频接入存储.编解码.深度学习推理.rtmp流媒体等等.每个环节的水都非常深,单独拿出来可以写好几篇文章,如果没有个几年经验基本很 ...
- SpringBoot 总结篇
时至今日,SpringBoot 系列文章也算是告一段落,回想起当初立flag的情景,仿佛还历历在目.用一个月时间学完 SpringBoot 并整理成文章?又定一些异想天开计划,当时这样 ...
- docker-网络驱动
网络驱动程序 Docker的网络子系统是可插拔的,使用驱动程序.默认情况下存在多个驱动程序,并提供核心网络功能: bridge:默认网络驱动程序.如果未指定驱动程序,则这是要创建的网络类型.当的应用程 ...
- 6.6 hadoop作业调优
提高速度和性能.可以从下面几个点去优化 可以在本地运行调试来优化性能,但是本地和集群是完全不同的环境,数据流模式也截然不同,性能优化要在集群上测试.有些问题如(内存溢出)只能在集群上重现. HPROF ...
- # "可插拔式"组件设计,领略组件开发的奥秘
从一个 Confirm 组件开始,一步步写一个可插拔式的组件. 处理一个正常的支付流程(比如支付宝购买基金) 点击购买按钮 如果风险等级不匹配则:弹确认框(Confirm) 用户确认风险后:弹出支付方 ...
- cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse
cannot open git-upload-pack,cannot open git-receive-pack,Can't connect to any URI错误解决方法eclipse 解决ecl ...
- hexo零基础搭建博客系列(一)
关于其他搭建 [hexo4快速搭建博客(二)更换主题](https://blog.csdn.net/weixin_41800884/article/details/103750634)[hexo4快速 ...
- 哪些工具可以提升PHP开发效率
本文就我自己在开发过程中的一点经验,谈谈如何利用工具来提升开发工作的编码效率, IDE(phpstorm 收费) 一个好的IDE真的可以给开发人员节省大量的时间,我从最开始使用editplus 到su ...