【学习笔记】BP神经网络
转自 huaweizte123的CSDN博客 链接 https://blog.csdn.net/huaweizte123/article/details/78803045

第一步、向前传播得到预测数据:向前传播的过程,即数据从输入层输入,经过隐含层,输出层的计算得到预测值,预测值为输出层的输出结果。网络层的输出即,该层中所有节点(神经元)的输出值的集合。我们以图一的神经网络结构为例,分析向前传播过程。
1.得到隐含层的输出y1,y2,y3:


2.获取到第二层的隐含层输出y4,y5,输入的数据也就是第一层隐含层的输出数据y1,y2,y3。

3、通过输出层,得到最后的预测值y。
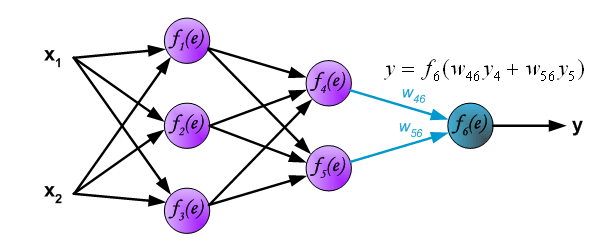
第二步、反向传播更新权重:根据样本的真实类标,计算模型预测的结果与真实类标的误差。然后将该误差反向传播到各个隐含层。计算出各层的误差,再根据各层的误差,更新权重。
1.计算输出层的误差:其中z为该样本的类标
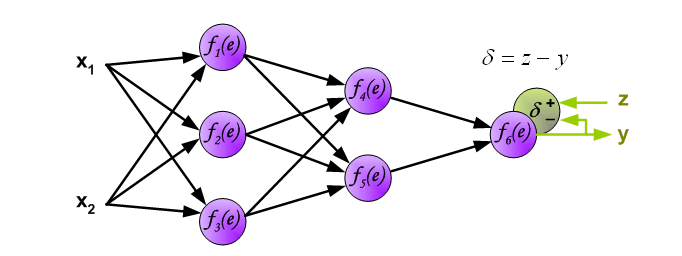
2计算第二层隐含层的误差

3.计算第一次隐含层的误差:

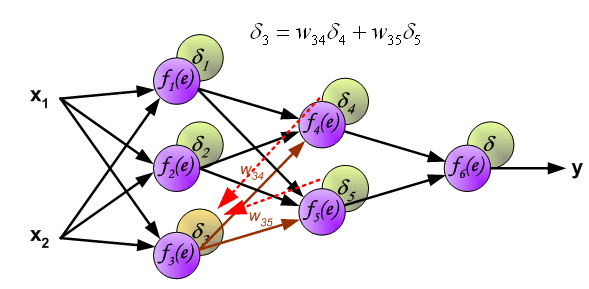
4、更新权重:新的权值=原权值+学习速率×该节点的误差×激励函数的导函数的值(f(e)的倒数)×与该节点相连的输入值
4.1更新输入层与第一层隐含层之间的权值:



4.2更新第一层隐含层与第二层隐含层之间的权值
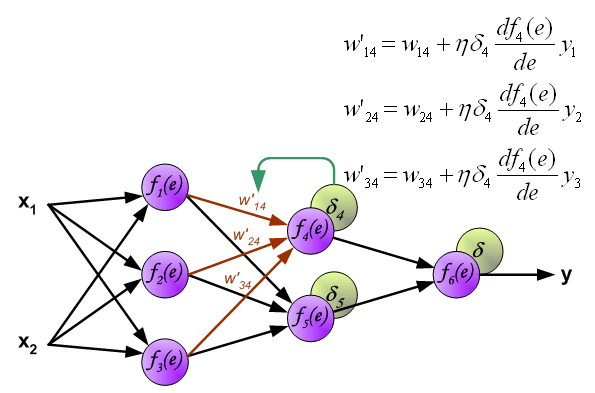

4.3更新第二层隐含层与输出层之间的权值
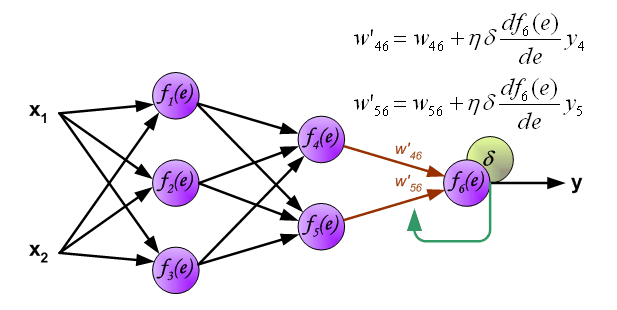
以上就是反向传播的过程。误差从输出层反向的传到输入层,然后再从输入层向前更新权值。
BP神经网络的设计与实现
(一) BP神经网络的设计
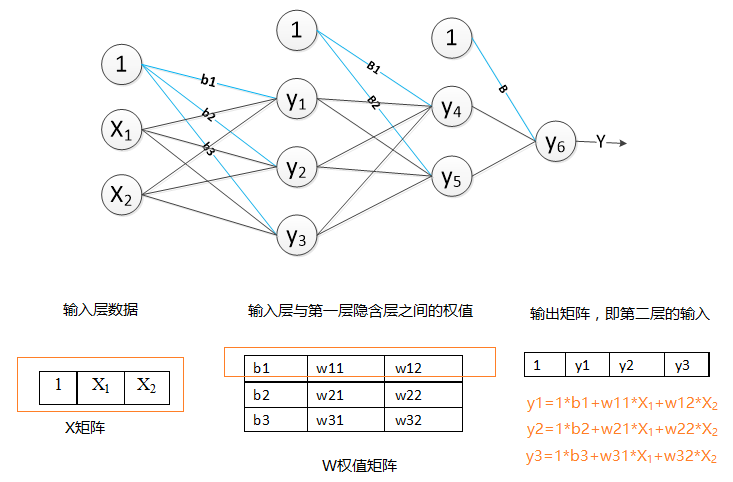
1.设计网络的结构:
本次实验采用java语言实现。设计了包含一个隐含层的神经网络,即一个2层的神经网络。
每层都含有一个一维X特征矩阵即为输入数据,一个二维W权值矩阵,一个一维的误差矩阵error,同时该神经网络中还包含了一个一维的目标矩阵target,记录样本的真实类标。
X特征矩阵:第一层隐含层的X矩阵的长度为输入层输入数据的特征个数+1,隐含层的X矩阵的长度则是上一层的节点的个数+1,X[0]=1。
W权值矩阵:第一维的长度设计为节点(即神经元)的个数,第二维的长度设计为上一层节点的个数+1;W[0][0]为该节点的偏置量
error误差矩阵:数组长度设计为该层的节点个数。
目标矩阵target:输出层的节点个数与其一致。
激活函数:采用sigmoid函数:1/1+e-x
2.神经网络的计算过程
按照以上的设计,向前传播得到下一层的输出结果,如图所示:
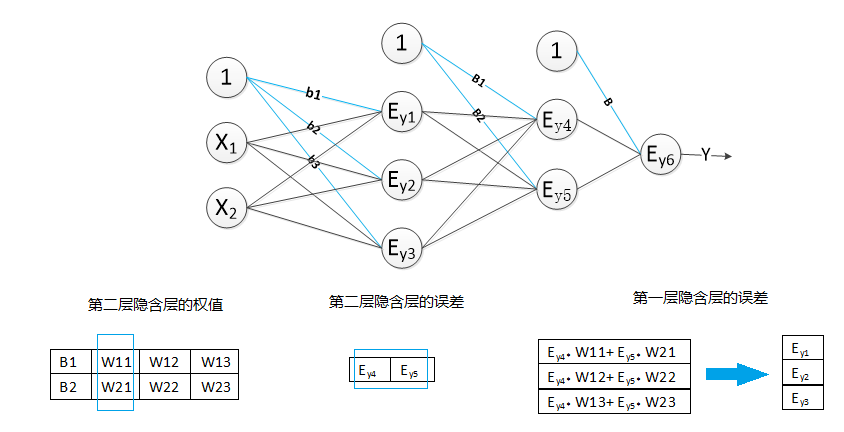
求误差过程,如图所示:
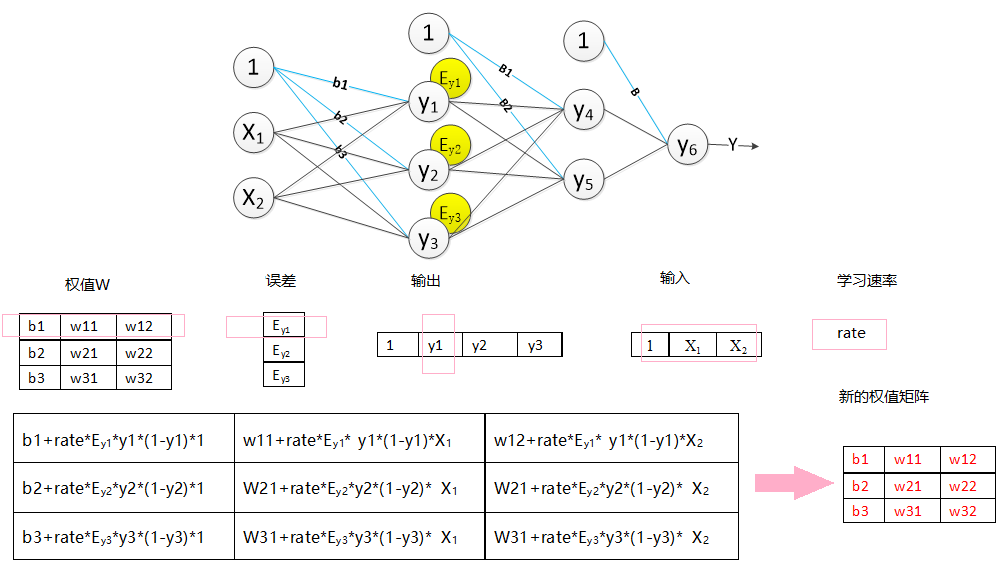
反向传播过程,调整权值,如图所示:
(二) BP神经网络的实现
一、向前传播得到预测数据:
1.初始化权值
2.训练数据集:
2.1、导入训练数据集和目标值;
2.2、向前传播得到输出值;
2.2.1、获取隐含层的输出
2.2.2、获取输出层的输出
二、反向传播更新权重
1、获取输出层的误差;
2、获取隐含层的误差;
3、更新隐含层的权值;
4、更新输出层的权值;
三.测试神经网络
3.3 向前传播得到预测值;
代码如下:
1 public class Bp {
2
3 private double[] hide1_x;//// 输入层即第一层隐含层的输入;hide1_x[数据的特征数目+1], hide1_x[0]为1
4 private double[][] hide1_w;// 隐含层权值,hide1_w[本层的节点的数目][数据的特征数目+1];hide_w[0][0]为偏置量
5 private double[] hide1_errors;// 隐含层的误差,hide1_errors[节点个数]
6
7 private double[] out_x;// 输出层的输入值即第二次层隐含层的输出 out_x[上一层的节点数目+1], out_x[0]为1
8 private double[][] out_w;// 输出层的权值 hide1_w[节点的数目][上一层的节点数目+1]//
9 // out_w[0][0]为偏置量
10 private double[] out_errors;// 输出层的误差 hide1_errors[节点个数]
11
12 private double[] target;// 目标值,target[输出层的节点个数]
13
14 private double rate;// 学习速率
15
16 public Bp(int input_node, int hide1_node, int out_node, double rate) {
17 super();
18
19 // 输入层即第一层隐含层的输入
20 hide1_x = new double[input_node + 1];
21
22 // 第一层隐含层
23 hide1_w = new double[hide1_node][input_node + 1];
24 hide1_errors = new double[hide1_node];
25
26 // 输出层
27 out_x = new double[hide1_node + 1];
28 out_w = new double[out_node][hide1_node + 1];
29 out_errors = new double[out_node];
30
31 target = new double[out_node];
32
33 // 学习速率
34 this.rate = rate;
35 init_weight();// 1.初始化网络的权值
36 }
37
38 /**
39 * 初始化权值
40 */
41 public void init_weight() {
42
43 set_weight(hide1_w);
44 set_weight(out_w);
45 }
46
47 /**
48 * 初始化权值
49 *
50 * @param w
51 */
52 private void set_weight(double[][] w) {
53 for (int i = 0, len = w.length; i != len; i++)
54 for (int j = 0, len2 = w[i].length; j != len2; j++) {
55 w[i][j] = 0;
56 }
57 }
58
59 /**
60 * 获取原始数据
61 *
62 * @param Data
63 * 原始数据矩阵
64 */
65 private void setHide1_x(double[] Data) {
66 if (Data.length != hide1_x.length - 1) {
67 throw new IllegalArgumentException("数据大小与输出层节点不匹配");
68 }
69 System.arraycopy(Data, 0, hide1_x, 1, Data.length);
70 hide1_x[0] = 1.0;
71 }
72
73 /**
74 * @param target
75 * the target to set
76 */
77 private void setTarget(double[] target) {
78 this.target = target;
79 }
80
81 /**
82 * 2.训练数据集
83 *
84 * @param TrainData
85 * 训练数据
86 * @param target
87 * 目标
88 */
89 public void train(double[] TrainData, double[] target) {
90 // 2.1导入训练数据集和目标值
91 setHide1_x(TrainData);
92 setTarget(target);
93
94 // 2.2:向前传播得到输出值;
95 double[] output = new double[out_w.length + 1];
96 forword(hide1_x, output);
97
98 // 2.3、方向传播:
99 backpropagation(output);
100
101 }
102
103 /**
104 * 反向传播过程
105 *
106 * @param output
107 * 预测结果
108 */
109 public void backpropagation(double[] output) {
110
111 // 2.3.1、获取输出层的误差;
112 get_out_error(output, target, out_errors);
113 // 2.3.2、获取隐含层的误差;
114 get_hide_error(out_errors, out_w, out_x, hide1_errors);
115 //// 2.3.3、更新隐含层的权值;
116 update_weight(hide1_errors, hide1_w, hide1_x);
117 // * 2.3.4、更新输出层的权值;
118 update_weight(out_errors, out_w, out_x);
119 }
120
121 /**
122 * 预测
123 *
124 * @param data
125 * 预测数据
126 * @param output
127 * 输出值
128 */
129 public void predict(double[] data, double[] output) {
130
131 double[] out_y = new double[out_w.length + 1];
132 setHide1_x(data);
133 forword(hide1_x, out_y);
134 System.arraycopy(out_y, 1, output, 0, output.length);
135
136 }
137
138
139 public void update_weight(double[] err, double[][] w, double[] x) {
140
141 double newweight = 0.0;
142 for (int i = 0; i < w.length; i++) {
143 for (int j = 0; j < w[i].length; j++) {
144 newweight = rate * err[i] * x[j];
145 w[i][j] = w[i][j] + newweight;
146 }
147
148 }
149 }
150
151 /**
152 * 获取输出层的误差
153 *
154 * @param output
155 * 预测输出值
156 * @param target
157 * 目标值
158 * @param out_error
159 * 输出层的误差
160 */
161 public void get_out_error(double[] output, double[] target, double[] out_error) {
162 for (int i = 0; i < target.length; i++) {
163 out_error[i] = (target[i] - output[i + 1]) * output[i + 1] * (1d - output[i + 1]);
164 }
165
166 }
167
168 /**
169 * 获取隐含层的误差
170 *
171 * @param NeLaErr
172 * 下一层的误差
173 * @param Nextw
174 * 下一层的权值
175 * @param output 下一层的输入
176 * @param error
177 * 本层误差数组
178 */
179 public void get_hide_error(double[] NeLaErr, double[][] Nextw, double[] output, double[] error) {
180
181 for (int k = 0; k < error.length; k++) {
182 double sum = 0;
183 for (int j = 0; j < Nextw.length; j++) {
184 sum += Nextw[j][k + 1] * NeLaErr[j];
185 }
186 error[k] = sum * output[k + 1] * (1d - output[k + 1]);
187 }
188 }
189
190 /**
191 * 向前传播
192 *
193 * @param x
194 * 输入值
195 * @param output
196 * 输出值
197 */
198 public void forword(double[] x, double[] output) {
199
200 // 2.2.1、获取隐含层的输出
201 get_net_out(x, hide1_w, out_x);
202 // 2.2.2、获取输出层的输出
203 get_net_out(out_x, out_w, output);
204
205 }
206
207 /**
208 * 获取单个节点的输出
209 *
210 * @param x
211 * 输入矩阵
212 * @param w
213 * 权值
214 * @return 输出值
215 */
216 private double get_node_put(double[] x, double[] w) {
217 double z = 0d;
218
219 for (int i = 0; i < x.length; i++) {
220 z += x[i] * w[i];
221 }
222 // 2.激励函数
223 return 1d / (1d + Math.exp(-z));
224 }
225
226 /**
227 * 获取网络层的输出
228 *
229 * @param x
230 * 输入矩阵
231 * @param w
232 * 权值矩阵
233 * @param net_out
234 * 接收网络层的输出数组
235 */
236 private void get_net_out(double[] x, double[][] w, double[] net_out) {
237
238 net_out[0] = 1d;
239 for (int i = 0; i < w.length; i++) {
240 net_out[i + 1] = get_node_put(x, w[i]);
241 }
242
243 }
244
245 }
(二) BP神经网络的测试
用上面实现的BP神经网络来训练模型,自动判断它是正数还是复数,奇数还是偶数.
1 public class Test {
2
3 /**
4 * @param args
5 * @throws IOException
6 */
7 public static void main(String[] args) throws IOException {
8
9
10 Bp bp = new Bp(32, 15, 4, 0.05);
11
12 Random random = new Random();
13
14 List<Integer> list = new ArrayList<Integer>();
15 for (int i = 0; i != 6000; i++) {
16 int value = random.nextInt();
17 list.add(value);
18 }
19
20 for (int i = 0; i !=25; i++) {
21 for (int value : list) {
22 double[] real = new double[4];
23 if (value >= 0)
24 if ((value & 1) == 1)
25 real[0] = 1;
26 else
27 real[1] = 1;
28 else if ((value & 1) == 1)
29 real[2] = 1;
30 else
31 real[3] = 1;
32
33 double[] binary = new double[32];
34 int index = 31;
35 do {
36 binary[index--] = (value & 1);
37 value >>>= 1;
38 } while (value != 0);
39
40 bp.train(binary, real);
41
42
43
44 }
45 }
46
47
48
49
50 System.out.println("训练完毕,下面请输入一个任意数字,神经网络将自动判断它是正数还是复数,奇数还是偶数。");
51
52 while (true) {
53
54 byte[] input = new byte[10];
55 System.in.read(input);
56 Integer value = Integer.parseInt(new String(input).trim());
57 int rawVal = value;
58 double[] binary = new double[32];
59 int index = 31;
60 do {
61 binary[index--] = (value & 1);
62 value >>>= 1;
63 } while (value != 0);
64
65 double[] result =new double[4];
66 bp.predict(binary,result);
67
68
69 double max = -Integer.MIN_VALUE;
70 int idx = -1;
71
72 for (int i = 0; i != result.length; i++) {
73 if (result[i] > max) {
74 max = result[i];
75 idx = i;
76 }
77 }
78
79 switch (idx) {
80 case 0:
81 System.out.format("%d是一个正奇数\n", rawVal);
82 break;
83 case 1:
84 System.out.format("%d是一个正偶数\n", rawVal);
85 break;
86 case 2:
87 System.out.format("%d是一个负奇数\n", rawVal);
88 break;
89 case 3:
90 System.out.format("%d是一个负偶数\n", rawVal);
91 break;
92 }
93 }
94 }
95 }
在BP神经网络中, 学习速率,训练集,以及训练次数,都会影响到最终模型的泛化能力。因此,在设计模型时,节点的个数,学习速率的大小,以及训练次数都是需要考虑的。
【学习笔记】BP神经网络的更多相关文章
- CNN学习笔记:神经网络表示
CNN学习笔记:神经网络表示 双层神经网络模型 在一个神经网络中,当你使用监督学习训练它的时候,训练集包含了输入x还有目标输出y.隐藏层的含义是,在训练集中,这些中间节点的真正数值,我们是不知道的,即 ...
- TensorFlow学习笔记——深层神经网络的整理
维基百科对深度学习的精确定义为“一类通过多层非线性变换对高复杂性数据建模算法的合集”.因为深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中可以认为深度学习就是深度神经网络的代名词.从 ...
- TensorFlow 深度学习笔记 卷积神经网络
Convolutional Networks 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Is ...
- 学习笔记DL003:神经网络第二、三次浪潮,数据量、模型规模,精度、复杂度,对现实世界冲击
神经科学,依靠单一深度学习算法解决不同任务.视觉信号传送到听觉区域,大脑听学习处理区域学会“看”(Von Melchner et al., 2000).计算单元互相作用变智能.新认知机(Fukushi ...
- Neural Networks and Deep Learning学习笔记ch1 - 神经网络
近期開始看一些深度学习的资料.想学习一下深度学习的基础知识.找到了一个比較好的tutorial,Neural Networks and Deep Learning,认真看完了之后觉得收获还是非常多的. ...
- TensorFlow深度学习笔记 循环神经网络实践
转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有问题可以到Issue区讨论 官方教程地址 视频/字幕下载 加 ...
- tensorflow学习笔记六----------神经网络
使用mnist数据集进行神经网络的构建 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from ...
- MATLAB神经网络(1) BP神经网络的数据分类——语音特征信号分类
1.1 案例背景 1.1.1 BP神经网络概述 BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传递,误差反向传播.在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层.每一层的神 ...
- [DL学习笔记]从人工神经网络到卷积神经网络_1_神经网络和BP算法
前言:这只是我的一个学习笔记,里边肯定有不少错误,还希望有大神能帮帮找找,由于是从小白的视角来看问题的,所以对于初学者或多或少会有点帮助吧. 1:人工全连接神经网络和BP算法 <1>:人工 ...
- 数模学习笔记(五)——BP神经网络
1.BP神经网络是一种前馈型网络(各神经元接受前一层的输入,并输出给下一层,没有反馈),分为input层,hide层,output层 2.BP神经网络的步骤: 1)创建一个神经网络:newff a.训 ...
随机推荐
- Mongodb 3.2.8: 集群环境搭建
简介 MongoDB是一种面向文档的数据库管理系统,由C++撰写而成,以此来解决应用程序开发社区中的大量现实问题.2007年10月,MongoDB由10gen团队所发展.2009年2月首度推出. ## ...
- 9.3.1 map端连接- DistributedCache分布式缓存小数据集
1.1.1 map端连接- DistributedCache分布式缓存小数据集 当一个数据集非常小时,可以将小数据集发送到每个节点,节点缓存到内存中,这个数据集称为边数据.用map函数 ...
- 使用 pyenv 管理不同的 Python 版本
1. pyenv 的安装 $ yum install git -y $ yum install gcc make patch gdbm-devel openssl-devel sqlite-devel ...
- 兄弟连 企业shell笔试题 16-31
企业实践题16:企业案例:写网络服务独立进程模式下rsync的系统启动脚本 例如:/etc/init.d/rsyncd{start|stop|restart} .要求:1.要使用系统函数库技巧.2.要 ...
- Redis 为什么这么快?
1. 纯内存操作,肯定快 数据存储在内存中,读取的时候不需要进行磁盘的 IO 2. 单线程,无锁竞争损耗 单线程保证了系统没有线程的上下文切换 使用单线程,可以避免不必要的上下文切换和竞争条件,没有多 ...
- 多线程笔记 - provider-consumer
通过多线程实现一个简单的生产者-消费者案例(笔记). 首先定义一个要生产消费的数据类 : public class Data { private String id; private String n ...
- StarUML之七、StarUML的Class Diagram(类图)示例
UML 类图中的概念 类图关系:泛化(继承).实现.聚合.组合.关联.依赖 类图的详解可在网上查询(推荐https://zhuanlan.zhihu.com/p/24576502) 它描述了在一个系统 ...
- mysql实现远程登录
CentOS7上安装mysql后,想要实现mysql远程登录. 主要解决二个问题:(1)为mysql用户授予远程登录权限(改表法或授权法):(2)防火墙开放3306端口. (一)授予登录权限 mysq ...
- Kakfa集群(2.11-0.10.1.0)版本滚动升级方案
Kafka集群版本升级(2.11-0.10.1.0)升级(2.11-0.10.2.2) 官网升级说明: 一.系统环境Zookeeper集群:172.16.2.10172.16.2.11172.16.2 ...
- Edge Chromium 中如何始终允许运行 Flash 内容
众所周知,由于 Adobe Flash 控件历史久远,积累了许多漏洞.早在2017年7月,Adobe就宣布了要在2020年底终止对 Flash 的支持.微软称其浏览器移除 Flash 插件的最后期限是 ...