spark-sql中的分析函数的使用
分析函数的应用场景:
(1)用于分组后组内排序
(2)指定计算范围
(3)Top N
(4)累加计算
(5)层次计算
分析函数的一般语法:
分析函数的语法结构一般是:
分析函数名(参数) over (子partition by 句 order by 字句 rows/range 字句)
1、分析函数名:sum、max、min、count、avg等聚合函数
lead、lag等比较函数
rank 等排名函数
2、over:关键字,表示前面的函数是分析函数,不是普通的聚合函数
3、分析字句:over关键字后面括号内的内容为分析子句,包含以下三部分内容
- partition by :分组子句,表示分析函数的计算范围,各组之间互不相干
- order by:排序子句,表示分组后,组内的排序方式
- rows/range:窗口子句,是在分组(partition by)后,表示组内的子分组(也即窗口),是分析函数的计算范围窗口
数据准备:
cookieid,createtime,pv
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
val conf = new SparkConf()
val ssc = new SparkSession.Builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.config(conf)
.getOrCreate() val sc = ssc.sparkContext
sc.setLogLevel("WARN") val df = ssc.read
.option("header", "true")
.option("inferschema", "true")
.csv("file:///E:/TestFile/analyfuncdata.txt") df.show(false)
df.printSchema()
df.createOrReplaceTempView("table")
val sql = "select * from table"
ssc.sql(sql).show(false)
测试需求:
1、按照cookid进行分组,createtime排序,并前后求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
|from table
""".stripMargin).show
运行结果:

2、与方式1 等价的写法
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
注:这里涉及到窗口子句,后面详细叙述。
运行结果:
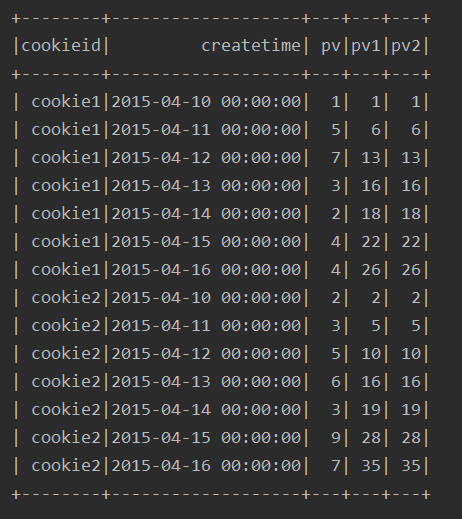
可以看到方式1的写法其实是方式2的一种默认形式
3、按照cookieid分组,不进行排序,求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid) as pv1
|from table
""".stripMargin).show
运行结果:

可以看出,在不进行排序的情况下,最终的求和列是每个分组的所有值得和,并非前后值相加
4、不进行分组,直接进行排序,求和(有问题)
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(order by createtime) as pv1
|from table
""".stripMargin).show
运行结果:
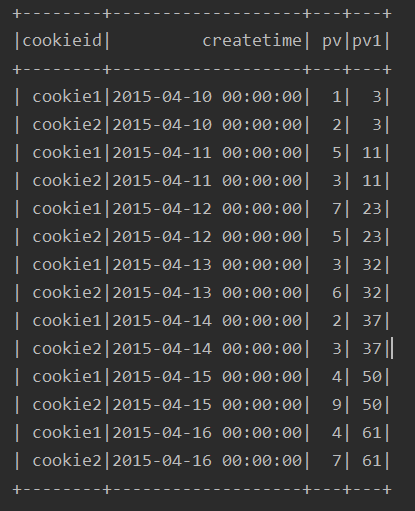
由结果可以看出,如果只是按照排序,不进行分区求和,得出来的结果好像乱七八糟的,有问题,所以我一般不这么做
5、over子句为空的情况下
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over() as pv1
|from table
""".stripMargin).show
运行结果:
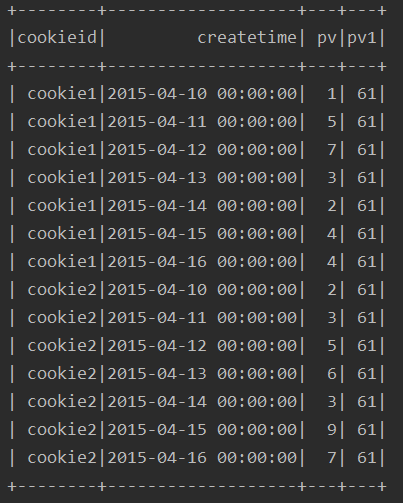
由结果看出,该种方式,其实就是对所有的行进行了求和
window子句
前面一开始执行了一个关于窗口子句:
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的,每个窗口函数应用自己的规则
rows between unbounded preceding and current row:
- rows between ... and ...(开始到结束,位置不能交换)
- unbounded preceding :从第一行开始
- current row:到当前行
当然,上述的从第几行开始到第几行是可以自定义的:
- 首行:unbounded preceding
- 末行:unbounded following
- 前 n 行:n preceding
- 后 n 行:n following
示例需求:
pv:原始值
pv1:起始行到当前行的累计值
pv2:等同于pv1,语法不同
pv3:仅有一个合计值
pv4:前三行到当前行的累计值
pv5:前三行到后一行的累计值
pv6:当前行到最后一行的累计值
注:这里所指的前三行,并不包含当前行本身
运行结果:

row & range
range:是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内
rows:是物理窗口,根据order by子句排序后,取前n行的数据以及后n行的数据进行计算(与当前行的值无关,至于排序由的行号有关)
需求案例:
1、对pv进行排名,求前一名到后两名的和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by pv
| range between 1 preceding and 2 following) as pv1
|from table
""".stripMargin).show
运行结果:
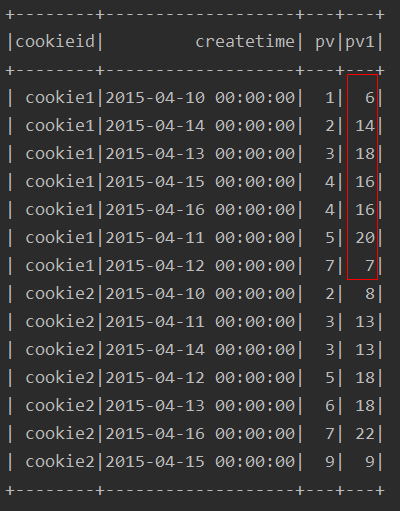
解释:

其他的聚合函数,用法与sum类似,比如:avg,min,max,count等
排名函数
排序方式:
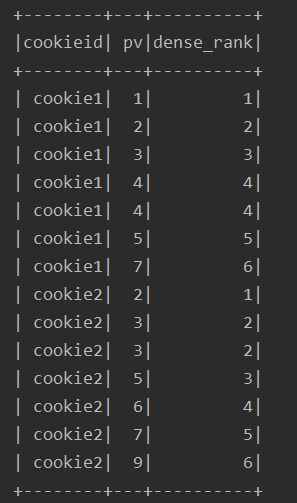
- row_number() :顺序排,忽略 并列排名
- dense_rank() :有并列,后面的元素接着排名
- rank() :有并列,后面的元素跳着排名
- ntile(n) :用于将分组数据按照顺序切分成n片
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
| row_number() over(partition by cookieid order by pv desc) rank1,
| rank() over(partition by cookieid order by pv desc) rank2,
| dense_rank() over(partition by cookieid order by pv desc) rank3,
| ntile(3) over(partition by cookieid order by pv desc) rank4
|from table
""".stripMargin).show
运行结果:

lag & lead
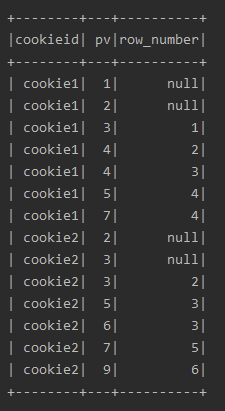
lag(field,n):取前 n 行的值
lead(field n):取后 n 行的值
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
|lag(pv) over(partition by cookieid order by pv) as col1,
|lag(pv,1) over(partition by cookieid order by pv) as col2,
|lag(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
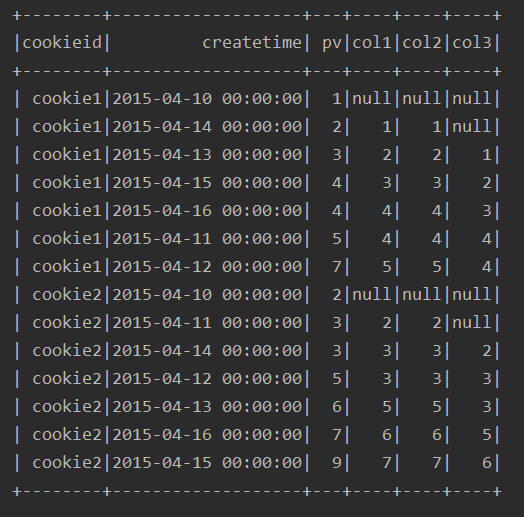
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv) over(partition by cookieid order by pv) as col1,
|lead(pv,1) over(partition by cookieid order by pv) as col2,
|lead(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
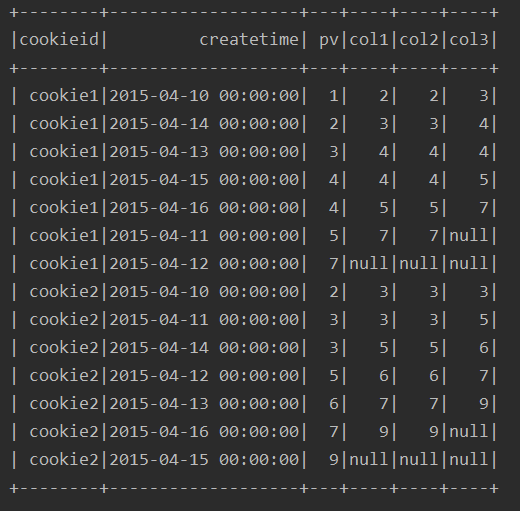
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv,-2) over(partition by cookieid order by pv) as col1,
|lag(pv,2) over(partition by cookieid order by pv) as col2
|from table
""".stripMargin).show
运行结果:

first_value & last_value
first_value(field) :取分组内排序后,截止到当前行的第一个值
last_value(field) :取分组内排序后,截止到当前行的最后一个值
例:
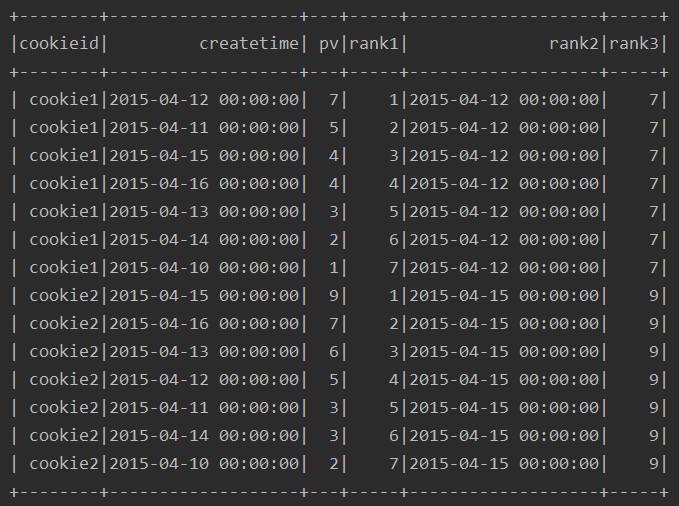
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|first_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|first_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
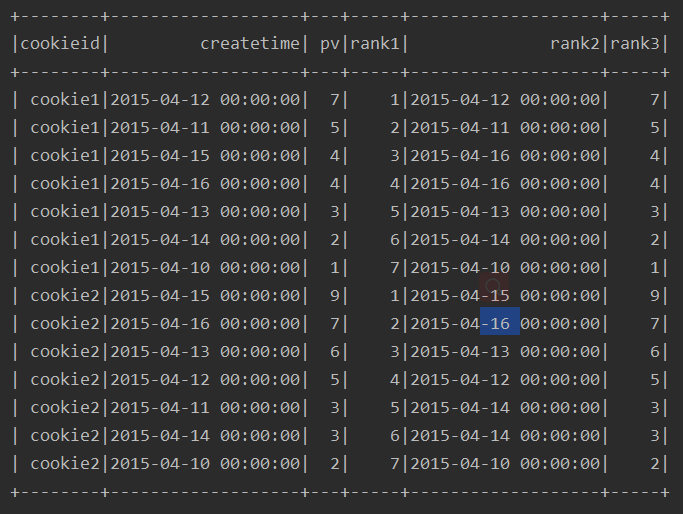
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|last_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|last_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
cube & rollup
cube:根据group by维度的所有组合进行聚合
rollup:是cube的自己,以左侧的维度为主,进行层级聚合
例:
ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by cube(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:

ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by rollup(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:
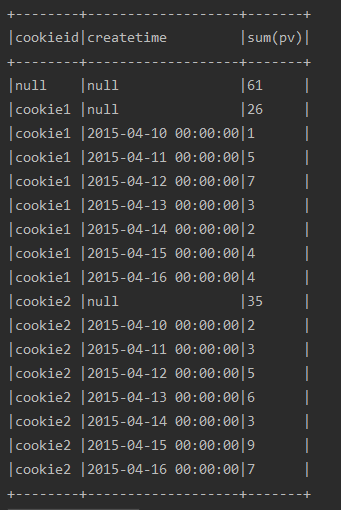
DSL
import org.apache.spark.sql.expressions.Window
import ssc.implicits._
import org.apache.spark.sql.functions._
val w1 = Window.partitionBy("cookieid").orderBy("createtime")
val w2 = Window.partitionBy("cookieid").orderBy("pv") //聚合函数
df.select($"cookieid", $"pv", sum("pv").over(w1).alias("pv1")).show() //排名
df.select($"cookieid", $"pv", rank().over(w2).alias("rank")).show()
df.select($"cookieid", $"pv", dense_rank().over(w2).alias("dense_rank")).show()
df.select($"cookieid", $"pv", row_number().over(w2).alias("row_number")).show() //lag、lead
df.select($"cookieid", $"pv", lag("pv", 2).over(w2).alias("row_number")).show()
df.select($"cookieid", $"pv", lag("pv", -2).over(w2).alias("row_number")).show() //cube、rollup
df.cube("cookieid", "createtime").agg(sum("pv")).show()
df.rollup("cookieid", "createtime").agg(sum("pv")).show()
运行结果:
1、聚合函数

2、排名函数:

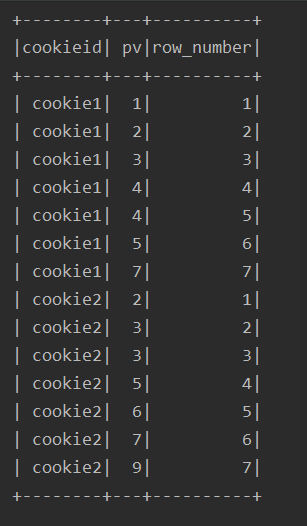
lag、lead

cube、rollup

spark-sql中的分析函数的使用的更多相关文章
- Spark SQL中列转行(UNPIVOT)的两种方法
行列之间的互相转换是ETL中的常见需求,在Spark SQL中,行转列有内建的PIVOT函数可用,没什么特别之处.而列转行要稍微麻烦点.本文整理了2种可行的列转行方法,供参考. 本文链接:https: ...
- spark sql中进行sechema合并
spark sql中支持sechema合并的操作. 直接上官方的代码吧. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // sql ...
- Spark SQL中UDF和UDAF
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- Spark SQL中出现 CROSS JOIN 问题解决
Spark SQL中出现 CROSS JOIN 问题解决 1.问题显示如下所示: Use the CROSS JOIN syntax to allow cartesian products b ...
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- 【原创】大叔经验分享(84)spark sql中设置hive.exec.max.dynamic.partitions无效
spark 2.4 spark sql中执行 set hive.exec.max.dynamic.partitions=10000; 后再执行sql依然会报错: org.apache.hadoop.h ...
- Spark SQL中Not in Subquery为何低效以及如何规避
首先看个Not in Subquery的SQL: // test_partition1 和 test_partition2为Hive外部分区表 select * from test_partition ...
- Spark SQL中的几种join
1.小表对大表(broadcast join) 将小表的数据分发到每个节点上,供大表使用.executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQ ...
- Spark SQL中 RDD 转换到 DataFrame (方法二)
强调它与方法一的区别:当DataFrame的数据结构不能够被提前定义.例如:(1)记录结构已经被编码成字符串 (2) 结构在文本文件中,可能需要为不同场景分别设计属性等以上情况出现适用于以下方法.1. ...
随机推荐
- 【JS学习】慕课网6-11编程联系 简单计算器
使用JS完成一个简单的计算器功能.实现2个输入框中输入整数后,点击第三个输入框能给出2个整数的加减乘除. 提示:获取元素的值设置和获取方法为:例:赋值:document.getElementById( ...
- express 使用art-template模板引擎
下载express-art-template art-template - app.js中配置 - 注册一个模板引擎 - `app.engine('.html',express-art-templat ...
- hdu 3374 最大最小表示法 next
题目大意: 就是求一个串的最大最小表示法的开始下标,然后求有多少个做大最小表示,输出格式为 最小表示下标 它的个数 最大表示下标 它的个数 基本思路: 最小最大表示法模板题,然后求一下循环节,很容易知 ...
- 使用cordova,使html5也能像IOS,Android那样可以 调取手机的相机拍照功能
一,我们在使用html5的技术开发手机app时,并不能像IOS,Android那样可以调取手机原生的相机功能,这是我们就要借助一些插件来时实现. 二,安装Cordoba的相机插件 1.在文件目录下,使 ...
- leetcode-161周赛-1250-检查好数组
题目描述: 唯一的结论是如果数组中所有数的最大公约数为 1,则存在解,否则不存在.所以只需要计算所有数最大公约数即可,时间复杂度O(nlog(m)),其中 m 为数字大小. class Solutio ...
- Unity Log Path
{ //不是开场动画的LOG,是APK的 C:\Program Files\Unity\Editor\Data\PlaybackEngines\AndroidPlayer\Apk\res\mipmap ...
- vue基础四
1.绑定Html Class(在 v-bind 用于 class 和 style 时, Vue.js 专门增强了它.表达式的结果类型除了字符串之外,还可以是对象或数组) 1.1对象语法 传给v-bin ...
- Tomcat启动报:The Server time zone value 'XXXXX' 乱码问题解决
今天给自己项目打包到服务器发布时,运行时,发现报 java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecogniz ...
- host文件是作用
什么是HOST文件:Hosts是一个没有扩展名的系统文件,其基本作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Host ...
- [NOIP模拟测试3] 建造游乐园 题解(欧拉图性质)
Orz 出题人石二队爷 我们可以先求出有n个点的联通欧拉图数量,然后使它删或增一条边得到我们要求的方案 也就是让它乘上$C_n^2$ (n个点里选2个点,要么删边要么连边,选择唯一) 那么接下来就是求 ...