spark-sql中的分析函数的使用
分析函数的应用场景:
(1)用于分组后组内排序
(2)指定计算范围
(3)Top N
(4)累加计算
(5)层次计算
分析函数的一般语法:
分析函数的语法结构一般是:
分析函数名(参数) over (子partition by 句 order by 字句 rows/range 字句)
1、分析函数名:sum、max、min、count、avg等聚合函数
lead、lag等比较函数
rank 等排名函数
2、over:关键字,表示前面的函数是分析函数,不是普通的聚合函数
3、分析字句:over关键字后面括号内的内容为分析子句,包含以下三部分内容
- partition by :分组子句,表示分析函数的计算范围,各组之间互不相干
- order by:排序子句,表示分组后,组内的排序方式
- rows/range:窗口子句,是在分组(partition by)后,表示组内的子分组(也即窗口),是分析函数的计算范围窗口
数据准备:
cookieid,createtime,pv
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
val conf = new SparkConf()
val ssc = new SparkSession.Builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.config(conf)
.getOrCreate() val sc = ssc.sparkContext
sc.setLogLevel("WARN") val df = ssc.read
.option("header", "true")
.option("inferschema", "true")
.csv("file:///E:/TestFile/analyfuncdata.txt") df.show(false)
df.printSchema()
df.createOrReplaceTempView("table")
val sql = "select * from table"
ssc.sql(sql).show(false)
测试需求:
1、按照cookid进行分组,createtime排序,并前后求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
|from table
""".stripMargin).show
运行结果:

2、与方式1 等价的写法
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
注:这里涉及到窗口子句,后面详细叙述。
运行结果:
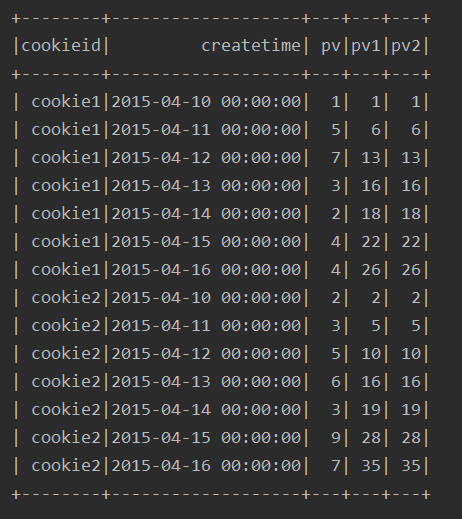
可以看到方式1的写法其实是方式2的一种默认形式
3、按照cookieid分组,不进行排序,求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid) as pv1
|from table
""".stripMargin).show
运行结果:

可以看出,在不进行排序的情况下,最终的求和列是每个分组的所有值得和,并非前后值相加
4、不进行分组,直接进行排序,求和(有问题)
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(order by createtime) as pv1
|from table
""".stripMargin).show
运行结果:
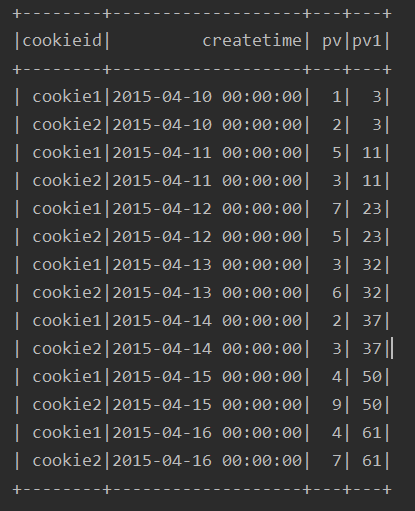
由结果可以看出,如果只是按照排序,不进行分区求和,得出来的结果好像乱七八糟的,有问题,所以我一般不这么做
5、over子句为空的情况下
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over() as pv1
|from table
""".stripMargin).show
运行结果:
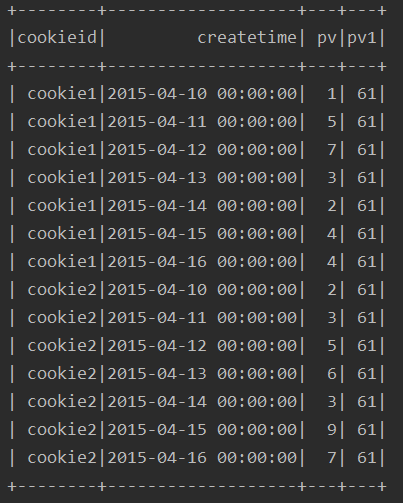
由结果看出,该种方式,其实就是对所有的行进行了求和
window子句
前面一开始执行了一个关于窗口子句:
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的,每个窗口函数应用自己的规则
rows between unbounded preceding and current row:
- rows between ... and ...(开始到结束,位置不能交换)
- unbounded preceding :从第一行开始
- current row:到当前行
当然,上述的从第几行开始到第几行是可以自定义的:
- 首行:unbounded preceding
- 末行:unbounded following
- 前 n 行:n preceding
- 后 n 行:n following
示例需求:
pv:原始值
pv1:起始行到当前行的累计值
pv2:等同于pv1,语法不同
pv3:仅有一个合计值
pv4:前三行到当前行的累计值
pv5:前三行到后一行的累计值
pv6:当前行到最后一行的累计值
注:这里所指的前三行,并不包含当前行本身
运行结果:

row & range
range:是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内
rows:是物理窗口,根据order by子句排序后,取前n行的数据以及后n行的数据进行计算(与当前行的值无关,至于排序由的行号有关)
需求案例:
1、对pv进行排名,求前一名到后两名的和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by pv
| range between 1 preceding and 2 following) as pv1
|from table
""".stripMargin).show
运行结果:
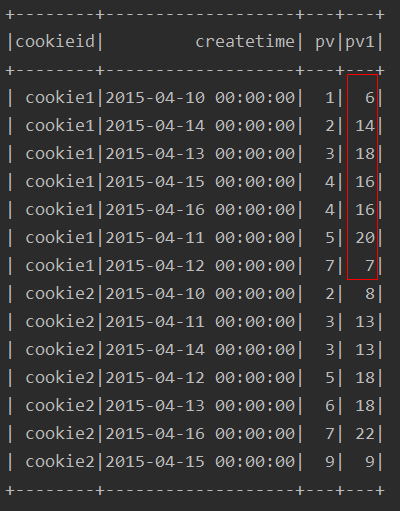
解释:

其他的聚合函数,用法与sum类似,比如:avg,min,max,count等
排名函数
排序方式:
- row_number() :顺序排,忽略 并列排名
- dense_rank() :有并列,后面的元素接着排名
- rank() :有并列,后面的元素跳着排名
- ntile(n) :用于将分组数据按照顺序切分成n片
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
| row_number() over(partition by cookieid order by pv desc) rank1,
| rank() over(partition by cookieid order by pv desc) rank2,
| dense_rank() over(partition by cookieid order by pv desc) rank3,
| ntile(3) over(partition by cookieid order by pv desc) rank4
|from table
""".stripMargin).show
运行结果:

lag & lead
lag(field,n):取前 n 行的值
lead(field n):取后 n 行的值
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
|lag(pv) over(partition by cookieid order by pv) as col1,
|lag(pv,1) over(partition by cookieid order by pv) as col2,
|lag(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
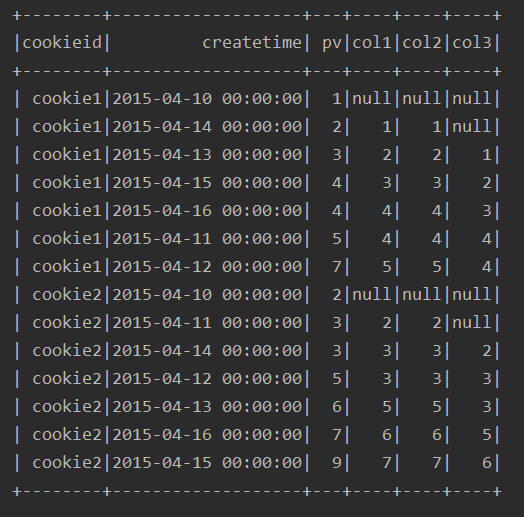
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv) over(partition by cookieid order by pv) as col1,
|lead(pv,1) over(partition by cookieid order by pv) as col2,
|lead(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
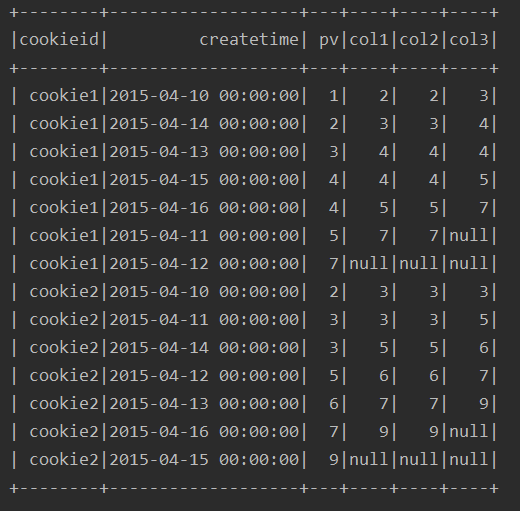
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv,-2) over(partition by cookieid order by pv) as col1,
|lag(pv,2) over(partition by cookieid order by pv) as col2
|from table
""".stripMargin).show
运行结果:

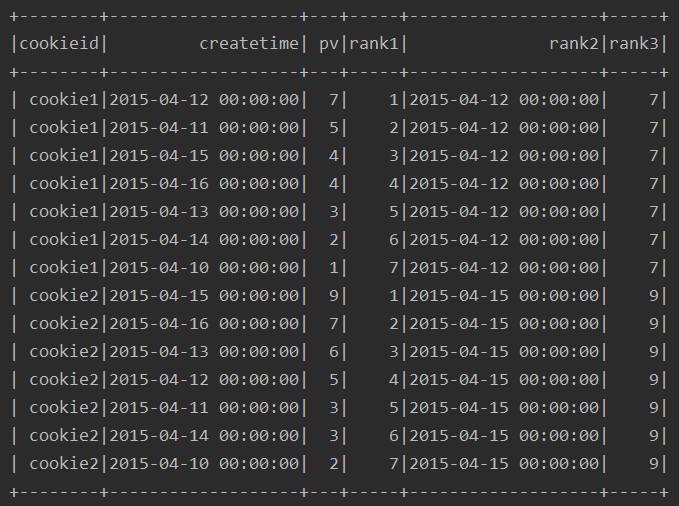
first_value & last_value
first_value(field) :取分组内排序后,截止到当前行的第一个值
last_value(field) :取分组内排序后,截止到当前行的最后一个值
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|first_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|first_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
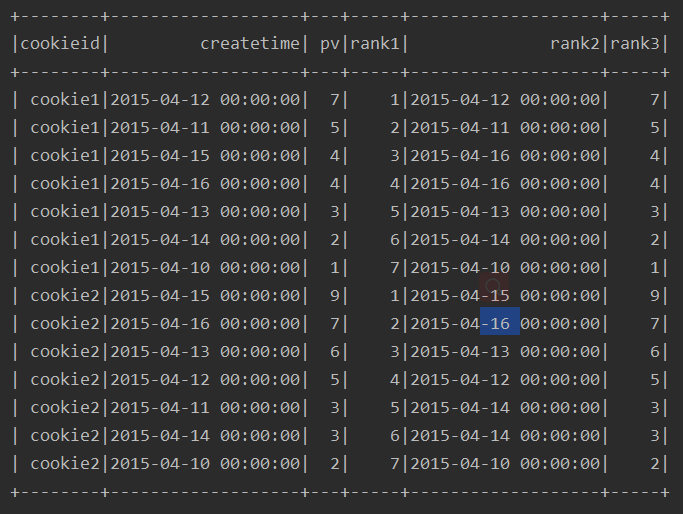
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|last_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|last_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
cube & rollup
cube:根据group by维度的所有组合进行聚合
rollup:是cube的自己,以左侧的维度为主,进行层级聚合
例:
ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by cube(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:

ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by rollup(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:
DSL
import org.apache.spark.sql.expressions.Window
import ssc.implicits._
import org.apache.spark.sql.functions._
val w1 = Window.partitionBy("cookieid").orderBy("createtime")
val w2 = Window.partitionBy("cookieid").orderBy("pv") //聚合函数
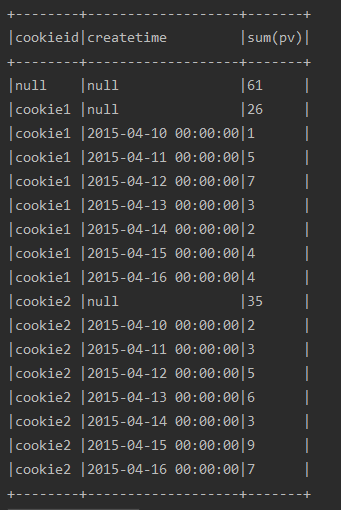
df.select($"cookieid", $"pv", sum("pv").over(w1).alias("pv1")).show() //排名
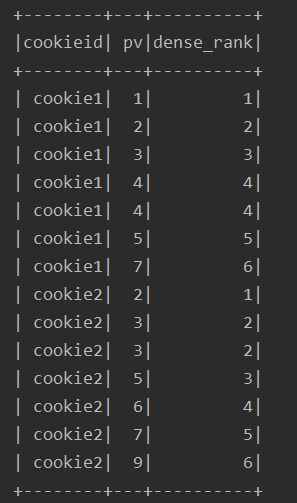
df.select($"cookieid", $"pv", rank().over(w2).alias("rank")).show()
df.select($"cookieid", $"pv", dense_rank().over(w2).alias("dense_rank")).show()
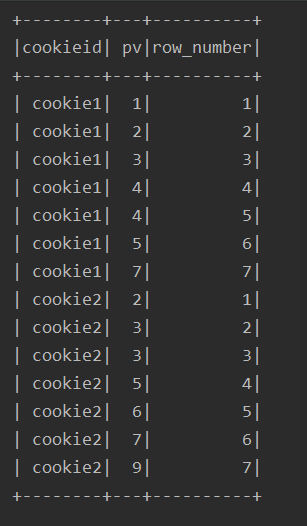
df.select($"cookieid", $"pv", row_number().over(w2).alias("row_number")).show() //lag、lead
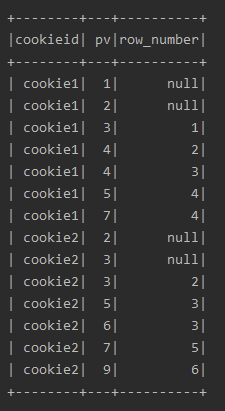
df.select($"cookieid", $"pv", lag("pv", 2).over(w2).alias("row_number")).show()
df.select($"cookieid", $"pv", lag("pv", -2).over(w2).alias("row_number")).show() //cube、rollup
df.cube("cookieid", "createtime").agg(sum("pv")).show()
df.rollup("cookieid", "createtime").agg(sum("pv")).show()
运行结果:
1、聚合函数

2、排名函数:

lag、lead

cube、rollup

spark-sql中的分析函数的使用的更多相关文章
- Spark SQL中列转行(UNPIVOT)的两种方法
行列之间的互相转换是ETL中的常见需求,在Spark SQL中,行转列有内建的PIVOT函数可用,没什么特别之处.而列转行要稍微麻烦点.本文整理了2种可行的列转行方法,供参考. 本文链接:https: ...
- spark sql中进行sechema合并
spark sql中支持sechema合并的操作. 直接上官方的代码吧. val sqlContext = new org.apache.spark.sql.SQLContext(sc) // sql ...
- Spark SQL中UDF和UDAF
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- Spark SQL中出现 CROSS JOIN 问题解决
Spark SQL中出现 CROSS JOIN 问题解决 1.问题显示如下所示: Use the CROSS JOIN syntax to allow cartesian products b ...
- Spark SQL中的Catalyst 的工作机制
Spark SQL中的Catalyst 的工作机制 答:不管是SQL.Hive SQL还是DataFrame.Dataset触发Action Job的时候,都会经过解析变成unresolved的逻 ...
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- 【原创】大叔经验分享(84)spark sql中设置hive.exec.max.dynamic.partitions无效
spark 2.4 spark sql中执行 set hive.exec.max.dynamic.partitions=10000; 后再执行sql依然会报错: org.apache.hadoop.h ...
- Spark SQL中Not in Subquery为何低效以及如何规避
首先看个Not in Subquery的SQL: // test_partition1 和 test_partition2为Hive外部分区表 select * from test_partition ...
- Spark SQL中的几种join
1.小表对大表(broadcast join) 将小表的数据分发到每个节点上,供大表使用.executor存储小表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时,这在SparkSQ ...
- Spark SQL中 RDD 转换到 DataFrame (方法二)
强调它与方法一的区别:当DataFrame的数据结构不能够被提前定义.例如:(1)记录结构已经被编码成字符串 (2) 结构在文本文件中,可能需要为不同场景分别设计属性等以上情况出现适用于以下方法.1. ...
随机推荐
- PHP中unset和null的比较
起因 因为感兴趣于unset($var)和$var=null的区别,于是找了一个stackoverflow高分问题及答案,翻译以供参考. 注:以下的问题和答案翻译自http://stackoverfl ...
- alter update
## sql alter update 添加.修改.删除字段 ## 添加列名alter table 表名 add 列名 列类型;alter table 表名 add 列名 列类型 not null d ...
- java中有几种方法可以实现一个线程?用什么关键字修饰同步方法? stop()和suspend()方法为何不推荐使用?
有两种实现方法,分别是继承Thread类与实现Runnable接口用synchronized关键字修饰同步方法反对使用stop(),是因为它不安全.它会解除由线程获取的所有锁定,而且如果对象处于一种不 ...
- 洛谷P1935 [国家集训队]圈地计划
题目大意: 有个\(n*m\)的网格图 每个点可以选择\(A\),获得\(A[i][j]\)或选\(B\)获得\(B[i][j]\)的收益 相邻点有\(k\)个不同可以获得\(C[i][j]\)的收益 ...
- SQL SELECT TOP, LIMIT, ROWNUM
SQL SELECT TOP, LIMIT, ROWNUM SQL SELECT TOP 子句 SELECT TOP 子句用于指定要返回的记录数量. SELECT TOP子句在包含数千条记录的大型表上 ...
- javascript实现获取指定精度的上传文件的大小简单实例
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- CSP-S2019退役记
分两次写完思路不是很清晰. 作为一名强迫症患者我选择以后再更新一些细节…… upd 真·退役,D1T1为什么都是95分算法他们AC了我挂成了70分555555555555 普及-的题目A不掉我死了55 ...
- $\mathcal{CSP-S}$,私は来ています
记事本 开个坑.背包dp我是真的一点也不会了... NOIP2014飞扬的小鸟 NOIP2018货币系统 11-4:$Countdown$ $to$ $the$ $tenth$ $day$ 上午 困的 ...
-  导致页面顶部空白一行
模板文件生成html文件以后会在页面body开头处生成可见的控制符 导致页面头部出现一个空白行,导致这样的原因就是页面的编码格式是UTF-8 + BOM 解决方法,最简单的就是使用编辑器重新保存文件 ...
- 1242 斐波那契数列的第N项
1242 斐波那契数列的第N项 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 斐波那契数列的定义如下: F(0) = 0 F(1) = 1 F(n) = F( ...