hadoop学习笔记(一):NameNade持久化和DataNode概念

其中的fsimage 称为时点备份,又叫磁盘镜像快照,这个是NameNode的一个
持久化的方式之一:缺点,在内存数据序列化的时候比较慢
具体的过程:因为我们所知道的NameNode一般是存储在内存中的,并没有和磁盘进行交互,这和redis这类的非关系型数据库差不多,但是内存中的数据总是没有持久化的,那么怎么去持久化呢?就比如我们的NameNode结点数据的持久化过程:先将内存中的数据序列化为二进制字节流,之后将其通过IO的形式存入到计算机的文件系统中,就完成了持久化的过程,具体的如果NameNode需要数据的过程的时候,需要将外存中的字节码文件,反序列化,之后加载到内存中,就可以供NameNode使用了
注意点:时点快照:只会按规定的间隔一段时间之后再去持久化到外存中,如13点,15点,17点。。。。而不是每一秒都在进行持久化,因为这样的话又会频繁的和外存也就是磁盘进行交互,这样数据的获取的时间就会很长了

持久化的方式之二:缺点,在数据存入外存的过程不慢,但是当存外存恢复到内存的时候比较慢
edits记录对metadata的操作日志。。。>Redis
即日志编辑方式:1)数据存入外村会将客户端对服务器中的任何的一条指令都写入到操作日志log这个文件当中 2)数据从外存加载到内存中:直接再执行一遍log中的指令即可。
此方式也是时隔一段规定的时间才回去持久化,而不是实时的
********Hadoop集群中NameNode的信息一般的是将这两个结合起来持久化的
下面是具体的持久化 的过程:
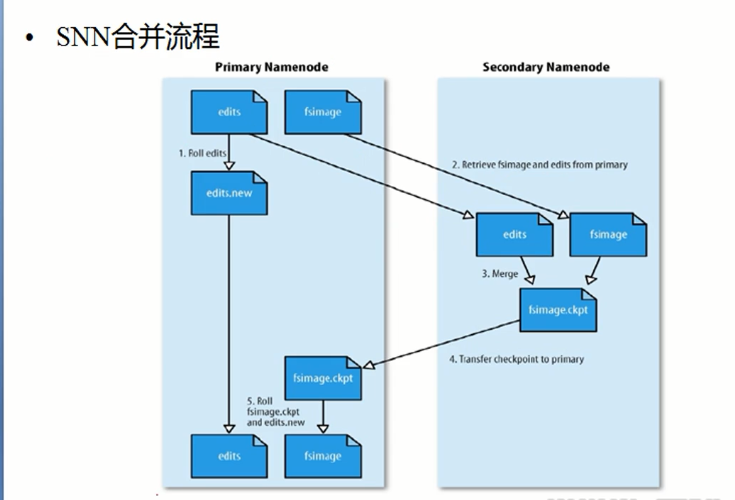
但是怎么去将这两种方式结合起来使用呢?首先先要理解fsimage文件和edits文件的产生的时候,对于fsimage文件是产生于搭建hadoop集群系统的时候,此时产生的文件是空的。edits的产生时机:集群启动的时候,会产生一个edits log文件,此时的文件也是空的,之后启动完毕之后,log文件会和fsimage文件进行合并,之后log一直会增大,因为集群启动之后,客户端会不断的通过NameNode实时的向集群发送指令,这都会记录到log文件中,这个时候 所带来的问题:log文件一直会增大,所以此时更不能通过edits进行恢复数据了,时间会很长,所以hadoop会通过SecondNameNode有时对edits和fsimage文件进行合并
SecondaryNameNode概念:并不是nameNode的备份,而仅仅是为了合并fsimage文件和log文件出现的这个

具体的合并过程
刚刚集群搭建完毕之后:生成了一个空的fsimage,之后启动了系统之后,就会产生一个fsimage文件,之后客户端对NameNode进行发送指令记录在edits中,所以edits会变大,但是通过第二主节点的检查,当edits达到一定的大小之后,便不会让他继续的去记录指令了,NameNode就会将所在结点(也就是主结点)edits传输至第二主节点进行合并处理,同时主结点的edits会清空,为了以后再次接受指令记录的时候仍然从0的大小开始增长。合并之后会发送给NameNode,将原有的主结点中的fsimage进行替代,之后主结点中的那个edits会从新的开始记录客户端发送的指令,之后整个此过程重复即可。但是这个是hadoop1.0时候的持久化的NameNode数据处理机制。在2.x版本之后,这个SecondaryNameNode就消失了
DataNode学习理解

hadoop学习笔记(一):NameNade持久化和DataNode概念的更多相关文章
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
随机推荐
- memcached和redis对比
关于memcached和redis的使用场景,总结如下:两者对比: redis提供数据持久化功能,memcached无持久化. redis的数据结构比memcached要丰富,能完成场景以外的事情: ...
- WPF学习笔记四之命令
1.概念 对于程序来说,命令就是一个个任务,例如保存,复制,剪切这些操作都可以理解为一个个命令.即当我们点击一个复杂按钮时,此时就相当于发出了一个复制的命令,即告诉文本框执行一个复杂选中内容的操作,然 ...
- 大数据-sparkSQL
SparkSQL采用Spark on Hive模式,hive只负责数据存储,Spark负责对sql命令解析执行. SparkSQL基于Dataset实现,Dataset是一个分布式数据容器,Datas ...
- PHP随机生成名字 电话号码
封装函数 随机生成电话号码 function generate_name($count,$type="array",$white_space=false) {$arr = arra ...
- redis5.0.7安装及配置集群
1.安装环境linux系统,时间2020年2月 2.官网下载https://redis.io/ 3.解压 tar -zxvf redis-5.0.7.tar.gz 4.配置文件 //创建etc文件夹, ...
- 2019HDU多校第一场1001 BLANK (DP)(HDU6578)
2019HDU多校第一场1001 BLANK (DP) 题意:构造一个长度为n(n<=10)的序列,其中的值域为{0,1,2,3}存在m个限制条件,表示为 l r x意义为[L,R]区间里最多能 ...
- LED Decorative Light Manufacturer - LED Neon Rope: 5 Advantages
In the past 100 years, lighting has come a long way. Nowadays, the decorative LED lighting design ca ...
- 转载:EQ--biquad filter
http://www.musicdsp.org/files/Audio-EQ-Cookbook.txt https://arachnoid.com/BiQuadDesigner/index.html ...
- jQuery对象和语法
jQuery类型 引入jquery.js时,其实是向全局作用域中,添加了一个新的类型--jQuery. 构造函数:负责创建jQuery类型的对象. 原型对象:保存jQuery对象可用的所有简化版API ...
- linux下删除空行的几种方法
在查看linux下的配置文件时,为了便于一目了然的查看,经常会删除空行和#头的行.而linux在删除空行的方法很多,grep.sed.awk.tr等工具都能实现.现总结如下: 1.grep grep ...